import pandas as pd
import numpy as np
from matplotlib import pyplot as plt # pour les graphiques d'évolution de la population dans le temps
import plotly.express as px # pour les cartes choroplèthes
import requests # pour récupérer les fichiers GeoJSON en ligne pour les cartes
# Pour la génération automatique de graphiques interactifs dans le polycopié
import plotly.io as pio
import os
if os.getenv("QUARTO_OUTPUT_FORMAT") is not None:
# Export Quarto HTML
pio.renderers.default = "iframe_connected"
else:
# Notebook interactif
pio.renderers.default = "notebook_connected"Population des communes de France
Le fichier population.csv contient les séries historiques de population (1876 à 2021) par Commune de France hors Mayotte. Il a été mis en ligne en décembre 2023 (source : Insee, recensements de la population).
Les colonnes correspondent à :
- le code géographique,
- la région,
- le département,
- le libellé géographique
- la population de 1876 à 2021.
Remarque : les treize régions métropolitaines (dont la Corse) et les cinq régions ultramarines ont les codes INSE suivants :
- 84 Auvergne-Rhône-Alpes
- 27 Bourgogne-Franche-Comté
- 53 Bretagne
- 24 Centre-Val de Loire
- 94 Corse
- 44 Grand Est
- 32 Hauts-de-France
- 11 Île-de-France
- 28 Normandie
- 75 Nouvelle-Aquitaine
- 76 Occitanie
- 52 Pays de la Loire
- 93 Provence-Alpes-Côte d’Azur
- 01 Guadeloupe
- 02 Martinique
- 03 Guyane
- 04 La Réunion
- 06 Mayotte
1 Exercice
- Afficher les données
- Lire le fichier
population.csv. - Afficher les 5 premières lignes.
- Afficher les 5 dernières lignes.
- Afficher les noms des colonnes.
- Compter le nombre de communes.
- Afficher les types des colonnes.
- Lire le fichier
- Nettoyer les colonnes et les données
- La colonne
CODGEOne nous intéresse pas. Supprimer cette colonne. - Renommer les étiquettes des colonnes correspondant aux années pour les rendre des entiers (par exemple,
"PMUN2020"devient2020). - Nettoyer les valeurs car elles sont de type
stret contiennent des espaces. Par exemple," 1 000 "devient1000.
- La colonne
- Aggreger/Filtrer les données
- Afficher les lignes correspondant à la région Provence-Alpes-Côte d’Azur. Combien de communes sont présentes dans cette région ?
- Afficher les lignes correspondant au département du Var. Combien de communes sont présentes dans ce département ?
- Choisir une commune et afficher les lignes correspondant à cette commune.
- Visualiser l’évolution de la population
- Afficher sur un graphique l’évolution de la population de la commune de 1876 à 2021.
- Afficher sur un graphique l’évolution de la population de la France metropolitaine de 1876 à 2021.
J’ai crée un dictionnaire regions_dict qui associe les codes régionaux à leur nom. Utilise-le pour afficher les noms des régions présentes dans le fichier population.csv.
# Dictionnaire associant les codes de région à leurs noms
region_dict = {
84: "Auvergne-Rhône-Alpes",
27: "Bourgogne-Franche-Comté",
53: "Bretagne",
24: "Centre-Val de Loire",
94: "Corse",
44: "Grand Est",
32: "Hauts-de-France",
11: "Île-de-France",
28: "Normandie",
75: "Nouvelle-Aquitaine",
76: "Occitanie",
52: "Pays de la Loire",
93: "Provence-Alpes-Côte d'Azur",
1: "Guadeloupe",
2: "Martinique",
3: "Guyane",
4: "La Réunion",
6: "Mayotte"
}J’ai également crée un dictionnaire dep_PACA qui associe les codes départementaux de la région PACA à leur nom. Utilise-le pour afficher les noms des départements présents dans le fichier population.csv.
1.1 Afficher les données
Les cinque premières lignes du fichier population.csv :
| CODGEO | REG | DEP | LIBGEO | PMUN2021 | PMUN2020 | PMUN2019 | PMUN2018 | PMUN2017 | PMUN2016 | ... | PTOT1926 | PTOT1921 | PTOT1911 | PTOT1906 | PTOT1901 | PTOT1896 | PTOT1891 | PTOT1886 | PTOT1881 | PTOT1876 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 55039 | 44 | 55 | Beaumont-en-Verdunois | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 186 | 197 | 215 | 219 | 233 | 260 | 277 | 274 |
| 1 | 55050 | 44 | 55 | Bezonvaux | 0 | 0 | 0 | 0 | 0 | 0 | ... | 3 | 0 | 149 | 156 | 173 | 181 | 221 | 239 | 217 | 235 |
| 2 | 55139 | 44 | 55 | Cumières-le-Mort-Homme | 0 | 0 | 0 | 0 | 0 | 0 | ... | 4 | 3 | 205 | 206 | 239 | 240 | 239 | 238 | 251 | 246 |
| 3 | 55189 | 44 | 55 | Fleury-devant-Douaumont | 0 | 0 | 0 | 0 | 0 | 0 | ... | 90 | 12 | 422 | 361 | 348 | 433 | 425 | 524 | 334 | 378 |
| 4 | 55239 | 44 | 55 | Haumont-près-Samogneux | 0 | 0 | 0 | 0 | 0 | 0 | ... | 5 | 5 | 131 | 148 | 156 | 162 | 172 | 196 | 195 | 215 |
5 rows × 39 columns
Les cinq dernières lignes du fichier population.csv :
| CODGEO | REG | DEP | LIBGEO | PMUN2021 | PMUN2020 | PMUN2019 | PMUN2018 | PMUN2017 | PMUN2016 | ... | PTOT1926 | PTOT1921 | PTOT1911 | PTOT1906 | PTOT1901 | PTOT1896 | PTOT1891 | PTOT1886 | PTOT1881 | PTOT1876 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 34942 | 44109 | 52 | 44 | Nantes | 323 204 | 320 732 | 318 808 | 314 138 | 309 346 | 306 694 | ... | 184 509 | 183 704 | 170 535 | 161 908 | 160 033 | 146 170 | 142 410 | 144 938 | 140 221 | 135 504 |
| 34943 | 06088 | 93 | 06 | Nice | 348 085 | 343 477 | 342 669 | 341 032 | 340 017 | 342 637 | ... | 184 441 | 155 839 | 142 940 | 134 232 | 105 109 | 93 760 | 88 273 | 77 478 | 66 279 | 53 397 |
| 34944 | 31555 | 76 | 31 | Toulouse | 504 078 | 498 003 | 493 465 | 486 828 | 479 553 | 475 438 | ... | 180 771 | 175 434 | 149 576 | 149 438 | 149 841 | 149 963 | 149 791 | 147 617 | 140 289 | 131 642 |
| 34945 | 69123 | 84 | 69 | Lyon | 522 250 | 522 228 | 522 969 | 518 635 | 516 092 | 515 695 | ... | 574 125 | 564 446 | 526 248 | 474 652 | 461 687 | 468 311 | 440 315 | 404 172 | 378 581 | 344 513 |
| 34946 | 13055 | 93 | 13 | Marseille | 873 076 | 870 321 | 870 731 | 868 277 | 863 310 | 862 211 | ... | 652 196 | 586 341 | 550 619 | 517 498 | 491 161 | 442 239 | 403 749 | 376 143 | 360 099 | 318 868 |
5 rows × 39 columns
Les noms des colonnes du fichier population.csv :
Index(['CODGEO', 'REG', 'DEP', 'LIBGEO', 'PMUN2021', 'PMUN2020', 'PMUN2019',
'PMUN2018', 'PMUN2017', 'PMUN2016', 'PMUN2015', 'PMUN2014', 'PMUN2013',
'PMUN2012', 'PMUN2011', 'PMUN2010', 'PMUN2009', 'PMUN2008', 'PMUN2007',
'PMUN2006', 'PSDC1999', 'PSDC1990', 'PSDC1982', 'PSDC1975', 'PSDC1968',
'PSDC1962', 'PTOT1954', 'PTOT1936', 'PTOT1931', 'PTOT1926', 'PTOT1921',
'PTOT1911', 'PTOT1906', 'PTOT1901', 'PTOT1896', 'PTOT1891', 'PTOT1886',
'PTOT1881', 'PTOT1876'],
dtype='object')Combien de régions sont présentes dans le fichier population.csv ?
Lesquelles ?
# Afficher les noms des régions présentes dans le fichier
region_names = [ (code,region_dict[code]) for code in df["REG"].unique()]
sorted(region_names,key=lambda x: x[1]) # trier par nom[(84, 'Auvergne-Rhône-Alpes'),
(27, 'Bourgogne-Franche-Comté'),
(53, 'Bretagne'),
(24, 'Centre-Val de Loire'),
(94, 'Corse'),
(44, 'Grand Est'),
(1, 'Guadeloupe'),
(3, 'Guyane'),
(32, 'Hauts-de-France'),
(4, 'La Réunion'),
(2, 'Martinique'),
(28, 'Normandie'),
(75, 'Nouvelle-Aquitaine'),
(76, 'Occitanie'),
(52, 'Pays de la Loire'),
(93, "Provence-Alpes-Côte d'Azur"),
(11, 'Île-de-France')]Quelle région est absente du fichier population.csv ?
for cle, val in region_dict.items():
if cle not in df["REG"].unique():
print(f"La région absente est : {val} (code {cle})")La région absente est : Mayotte (code 6)Combien de communes ?
# 5. Nombre de communes
# df['LIBGEO'].count()
# ou
df.shape[0] # donne le nombre de lignes = de communes
# df['LIBGEO'].nunique()
# ne pas utiliser `nunique`` car certains nom des communes sont dupliqués34947Les types des colonnes du fichier population.csv :
CODGEO object
REG int64
DEP object
LIBGEO object
PMUN2021 object
PMUN2020 object
PMUN2019 object
PMUN2018 object
PMUN2017 object
PMUN2016 object
PMUN2015 object
PMUN2014 object
PMUN2013 object
PMUN2012 object
PMUN2011 object
PMUN2010 object
PMUN2009 object
PMUN2008 object
PMUN2007 object
PMUN2006 object
PSDC1999 object
PSDC1990 object
PSDC1982 object
PSDC1975 object
PSDC1968 object
PSDC1962 object
PTOT1954 object
PTOT1936 object
PTOT1931 object
PTOT1926 object
PTOT1921 object
PTOT1911 object
PTOT1906 object
PTOT1901 object
PTOT1896 object
PTOT1891 object
PTOT1886 object
PTOT1881 object
PTOT1876 object
dtype: object<class 'pandas.core.frame.DataFrame'>
RangeIndex: 34947 entries, 0 to 34946
Data columns (total 39 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 CODGEO 34947 non-null object
1 REG 34947 non-null int64
2 DEP 34947 non-null object
3 LIBGEO 34947 non-null object
4 PMUN2021 34947 non-null object
5 PMUN2020 34947 non-null object
6 PMUN2019 34947 non-null object
7 PMUN2018 34947 non-null object
8 PMUN2017 34947 non-null object
9 PMUN2016 34947 non-null object
10 PMUN2015 34947 non-null object
11 PMUN2014 34947 non-null object
12 PMUN2013 34947 non-null object
13 PMUN2012 34947 non-null object
14 PMUN2011 34947 non-null object
15 PMUN2010 34947 non-null object
16 PMUN2009 34947 non-null object
17 PMUN2008 34947 non-null object
18 PMUN2007 34947 non-null object
19 PMUN2006 34947 non-null object
20 PSDC1999 34947 non-null object
21 PSDC1990 34947 non-null object
22 PSDC1982 34947 non-null object
23 PSDC1975 34947 non-null object
24 PSDC1968 34947 non-null object
25 PSDC1962 34947 non-null object
26 PTOT1954 34921 non-null object
27 PTOT1936 34835 non-null object
28 PTOT1931 34475 non-null object
29 PTOT1926 34475 non-null object
30 PTOT1921 34475 non-null object
31 PTOT1911 34475 non-null object
32 PTOT1906 34475 non-null object
33 PTOT1901 34475 non-null object
34 PTOT1896 34475 non-null object
35 PTOT1891 34475 non-null object
36 PTOT1886 34475 non-null object
37 PTOT1881 34475 non-null object
38 PTOT1876 34475 non-null object
dtypes: int64(1), object(38)
memory usage: 10.4+ MBLe DataFrame population est composé de 39 colonnes et 34947 lignes.
Toutes les colonnes sont de type object (chaîne de caractères) sauf la colonne REG qui est de type int64.
On remarque de plus qu’il y a des données manquantes dans les dernières colonnes (34475 vs 34947).
1.2 Nettoyer les colonnes et les données
1.2.1 Suppression de colonnes inutiles
La colonne CODGEO est inutile pour notre analyse. Nous allons la supprimer.
| REG | DEP | LIBGEO | PMUN2021 | PMUN2020 | PMUN2019 | PMUN2018 | PMUN2017 | PMUN2016 | PMUN2015 | ... | PTOT1926 | PTOT1921 | PTOT1911 | PTOT1906 | PTOT1901 | PTOT1896 | PTOT1891 | PTOT1886 | PTOT1881 | PTOT1876 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 44 | 55 | Beaumont-en-Verdunois | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 186 | 197 | 215 | 219 | 233 | 260 | 277 | 274 |
| 1 | 44 | 55 | Bezonvaux | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 3 | 0 | 149 | 156 | 173 | 181 | 221 | 239 | 217 | 235 |
| 2 | 44 | 55 | Cumières-le-Mort-Homme | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 4 | 3 | 205 | 206 | 239 | 240 | 239 | 238 | 251 | 246 |
| 3 | 44 | 55 | Fleury-devant-Douaumont | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 90 | 12 | 422 | 361 | 348 | 433 | 425 | 524 | 334 | 378 |
| 4 | 44 | 55 | Haumont-près-Samogneux | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 5 | 5 | 131 | 148 | 156 | 162 | 172 | 196 | 195 | 215 |
| 5 | 44 | 55 | Louvemont-Côte-du-Poivre | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 10 | 0 | 183 | 200 | 204 | 234 | 235 | 265 | 250 | 253 |
| 6 | 84 | 26 | Rochefourchat | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 40 | 52 | 64 | 94 | 89 | 92 | 112 | 125 | 128 | 151 |
| 7 | 44 | 54 | Leménil-Mitry | 2 | 3 | 3 | 3 | 3 | 3 | 3 | ... | 22 | 24 | 34 | 39 | 24 | 37 | 45 | 48 | 50 | 52 |
| 8 | 84 | 26 | La Bâtie-des-Fonds | 2 | 2 | 2 | 3 | 4 | 5 | 6 | ... | 40 | 57 | 60 | 84 | 90 | 100 | 100 | 105 | 106 | 108 |
| 9 | 44 | 51 | Rouvroy-Ripont | 3 | 3 | 4 | 6 | 8 | 10 | 9 | ... | 10 | 6 | 166 | 173 | 169 | 199 | 228 | 235 | 242 | 283 |
| 10 | 76 | 31 | Caubous | 4 | 4 | 4 | 4 | 4 | 4 | 4 | ... | 41 | 43 | 53 | 50 | 53 | 50 | 58 | 66 | 63 | 65 |
| 11 | 84 | 26 | Pommerol | 5 | 5 | 6 | 6 | 11 | 15 | 20 | ... | 37 | 27 | 45 | 67 | 69 | 93 | 87 | 118 | 107 | 115 |
| 12 | 76 | 11 | Fontanès-de-Sault | 5 | 5 | 5 | 5 | 5 | 5 | 5 | ... | 65 | 68 | 136 | 123 | 141 | 171 | 183 | 198 | 196 | 203 |
| 13 | 93 | 04 | Majastres | 5 | 4 | 4 | 4 | 4 | 4 | 3 | ... | 61 | 76 | 150 | 183 | 211 | 221 | 259 | 273 | 276 | 303 |
| 14 | 44 | 52 | Charmes-en-l'Angle | 6 | 6 | 7 | 9 | 10 | 10 | 10 | ... | 40 | 35 | 77 | 59 | 57 | 71 | 82 | 89 | 99 | 124 |
| 15 | 44 | 88 | Maroncourt | 6 | 6 | 7 | 7 | 9 | 11 | 12 | ... | 18 | 23 | 23 | 37 | 35 | 30 | 35 | 49 | 55 | 62 |
| 16 | 32 | 80 | Épécamps | 6 | 6 | 5 | 5 | 5 | 5 | 5 | ... | 21 | 26 | 28 | 36 | 37 | 32 | 36 | 46 | 47 | 56 |
| 17 | 27 | 39 | Mérona | 7 | 7 | 7 | 8 | 8 | 9 | 10 | ... | 27 | 31 | 30 | 30 | 38 | 40 | 41 | 49 | 43 | 47 |
| 18 | 44 | 55 | Ornes | 7 | 7 | 6 | 6 | 5 | 6 | 5 | ... | 24 | 23 | 718 | 841 | 861 | 913 | 975 | 1 021 | 1 033 | 1 100 |
| 19 | 44 | 57 | Molring | 7 | 4 | 5 | 5 | 5 | 7 | 8 | ... | 35 | 43 | 52 | 82 | 74 | 67 | 70 | 70 | 55 | 82 |
20 rows × 38 columns
1.2.2 Modification des labels des colonnes
Nous allons renommer les étiquettes des colonnes de la troisième jusqu’à la dernière df.columns[3:] pour ne garder que les derniers quatre caractères col[-4:] (de sort à avoir encore des string mais qui pourrons être transformées en entiers au besoin).
# Renommer les colonnes des années
# ===============================
# { old_name_of_col : new_name_of_col for col in df.columns[3:] }
dico_old_new = { col:col[-4:] for col in df.columns[3:] }
df.rename(columns=dico_old_new, inplace=True)
df| REG | DEP | LIBGEO | 2021 | 2020 | 2019 | 2018 | 2017 | 2016 | 2015 | ... | 1926 | 1921 | 1911 | 1906 | 1901 | 1896 | 1891 | 1886 | 1881 | 1876 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 44 | 55 | Beaumont-en-Verdunois | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 186 | 197 | 215 | 219 | 233 | 260 | 277 | 274 |
| 1 | 44 | 55 | Bezonvaux | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 3 | 0 | 149 | 156 | 173 | 181 | 221 | 239 | 217 | 235 |
| 2 | 44 | 55 | Cumières-le-Mort-Homme | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 4 | 3 | 205 | 206 | 239 | 240 | 239 | 238 | 251 | 246 |
| 3 | 44 | 55 | Fleury-devant-Douaumont | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 90 | 12 | 422 | 361 | 348 | 433 | 425 | 524 | 334 | 378 |
| 4 | 44 | 55 | Haumont-près-Samogneux | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 5 | 5 | 131 | 148 | 156 | 162 | 172 | 196 | 195 | 215 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 34942 | 52 | 44 | Nantes | 323 204 | 320 732 | 318 808 | 314 138 | 309 346 | 306 694 | 303 382 | ... | 184 509 | 183 704 | 170 535 | 161 908 | 160 033 | 146 170 | 142 410 | 144 938 | 140 221 | 135 504 |
| 34943 | 93 | 06 | Nice | 348 085 | 343 477 | 342 669 | 341 032 | 340 017 | 342 637 | 342 522 | ... | 184 441 | 155 839 | 142 940 | 134 232 | 105 109 | 93 760 | 88 273 | 77 478 | 66 279 | 53 397 |
| 34944 | 76 | 31 | Toulouse | 504 078 | 498 003 | 493 465 | 486 828 | 479 553 | 475 438 | 471 941 | ... | 180 771 | 175 434 | 149 576 | 149 438 | 149 841 | 149 963 | 149 791 | 147 617 | 140 289 | 131 642 |
| 34945 | 84 | 69 | Lyon | 522 250 | 522 228 | 522 969 | 518 635 | 516 092 | 515 695 | 513 275 | ... | 574 125 | 564 446 | 526 248 | 474 652 | 461 687 | 468 311 | 440 315 | 404 172 | 378 581 | 344 513 |
| 34946 | 93 | 13 | Marseille | 873 076 | 870 321 | 870 731 | 868 277 | 863 310 | 862 211 | 861 635 | ... | 652 196 | 586 341 | 550 619 | 517 498 | 491 161 | 442 239 | 403 749 | 376 143 | 360 099 | 318 868 |
34947 rows × 38 columns
1.2.3 Modification des valeurs (nombre d’habitants) : nettoyage et typecasting
Maintenant, nous allons modifier les valeurs corespondant aux nombres d’habitants pour les rendre des entiers (par exemple, " 1 000 " devient 1000).
En effet, les valeurs correspondant à la population sont des chaînes de caractères qui ne peuvent pas être converties en entiers directement. Il faut remplacer le caractère \xa0 (qui correspond à l’espace insécable) par '', puis convertir les chaînes de caractères ainsi nettoyées en entiers.
# Ancienne méthode
# df[df.columns[4:]] = df[df.columns[3:]].applymap(lambda x: int(x.replace('\xa0', '')) if isinstance(x, str) else x)
# df
# Méthode avec la fonction clean_value
def clean_value(val):
try:
if isinstance(val, str):
val = val.replace('\xa0', '').strip()
if val.isdigit():
return int(val)
return val
except Exception as e:
return val
# Apply clean_value function to each column individually using map
for col in df.columns[3:]:
df[col] = df[col].map(clean_value).astype('Int64')
# Int64 est un type Pandas qui permet d'avoir des entiers avec
# des valeurs manquantes (NaN)
df
| REG | DEP | LIBGEO | 2021 | 2020 | 2019 | 2018 | 2017 | 2016 | 2015 | ... | 1926 | 1921 | 1911 | 1906 | 1901 | 1896 | 1891 | 1886 | 1881 | 1876 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 44 | 55 | Beaumont-en-Verdunois | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 186 | 197 | 215 | 219 | 233 | 260 | 277 | 274 |
| 1 | 44 | 55 | Bezonvaux | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 3 | 0 | 149 | 156 | 173 | 181 | 221 | 239 | 217 | 235 |
| 2 | 44 | 55 | Cumières-le-Mort-Homme | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 4 | 3 | 205 | 206 | 239 | 240 | 239 | 238 | 251 | 246 |
| 3 | 44 | 55 | Fleury-devant-Douaumont | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 90 | 12 | 422 | 361 | 348 | 433 | 425 | 524 | 334 | 378 |
| 4 | 44 | 55 | Haumont-près-Samogneux | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 5 | 5 | 131 | 148 | 156 | 162 | 172 | 196 | 195 | 215 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 34942 | 52 | 44 | Nantes | 323204 | 320732 | 318808 | 314138 | 309346 | 306694 | 303382 | ... | 184509 | 183704 | 170535 | 161908 | 160033 | 146170 | 142410 | 144938 | 140221 | 135504 |
| 34943 | 93 | 06 | Nice | 348085 | 343477 | 342669 | 341032 | 340017 | 342637 | 342522 | ... | 184441 | 155839 | 142940 | 134232 | 105109 | 93760 | 88273 | 77478 | 66279 | 53397 |
| 34944 | 76 | 31 | Toulouse | 504078 | 498003 | 493465 | 486828 | 479553 | 475438 | 471941 | ... | 180771 | 175434 | 149576 | 149438 | 149841 | 149963 | 149791 | 147617 | 140289 | 131642 |
| 34945 | 84 | 69 | Lyon | 522250 | 522228 | 522969 | 518635 | 516092 | 515695 | 513275 | ... | 574125 | 564446 | 526248 | 474652 | 461687 | 468311 | 440315 | 404172 | 378581 | 344513 |
| 34946 | 93 | 13 | Marseille | 873076 | 870321 | 870731 | 868277 | 863310 | 862211 | 861635 | ... | 652196 | 586341 | 550619 | 517498 | 491161 | 442239 | 403749 | 376143 | 360099 | 318868 |
34947 rows × 38 columns
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 34947 entries, 0 to 34946
Data columns (total 38 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 REG 34947 non-null int64
1 DEP 34947 non-null object
2 LIBGEO 34947 non-null object
3 2021 34947 non-null Int64
4 2020 34947 non-null Int64
5 2019 34947 non-null Int64
6 2018 34947 non-null Int64
7 2017 34947 non-null Int64
8 2016 34947 non-null Int64
9 2015 34947 non-null Int64
10 2014 34947 non-null Int64
11 2013 34947 non-null Int64
12 2012 34947 non-null Int64
13 2011 34947 non-null Int64
14 2010 34947 non-null Int64
15 2009 34947 non-null Int64
16 2008 34947 non-null Int64
17 2007 34947 non-null Int64
18 2006 34947 non-null Int64
19 1999 34947 non-null Int64
20 1990 34947 non-null Int64
21 1982 34947 non-null Int64
22 1975 34947 non-null Int64
23 1968 34947 non-null Int64
24 1962 34947 non-null Int64
25 1954 34921 non-null Int64
26 1936 34835 non-null Int64
27 1931 34475 non-null Int64
28 1926 34475 non-null Int64
29 1921 34475 non-null Int64
30 1911 34475 non-null Int64
31 1906 34475 non-null Int64
32 1901 34475 non-null Int64
33 1896 34475 non-null Int64
34 1891 34475 non-null Int64
35 1886 34475 non-null Int64
36 1881 34475 non-null Int64
37 1876 34475 non-null Int64
dtypes: Int64(35), int64(1), object(2)
memory usage: 11.3+ MB1.3 Aggregations
1.3.1 Combien de départements par region ?
| DEP | |
|---|---|
| REG | |
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 1 |
| 11 | 8 |
| 24 | 6 |
| 27 | 8 |
| 28 | 5 |
| 32 | 5 |
| 44 | 10 |
| 52 | 5 |
| 53 | 4 |
| 75 | 12 |
| 76 | 13 |
| 84 | 12 |
| 93 | 6 |
| 94 | 2 |
# ou avec groupby
# ====================================
df_grby = df.groupby("REG")["DEP"]
nb_dep_par_reg = df_grby.nunique()
# C'est une série:
# - les index sont les codes régionaux,
# - les valeurs sont le nombre de départements
# On peut alors l'utiliser pour afficher des informations supplémentaires
for reg, count in nb_dep_par_reg.items():
dep_uniques = df_grby.get_group(reg).unique() # les départements uniques pour cette région
print(f"La région {reg} ({region_dict[reg]}) a {count} départements : {dep_uniques}")La région 1 (Guadeloupe) a 1 départements : ['971']
La région 2 (Martinique) a 1 départements : ['972']
La région 3 (Guyane) a 1 départements : ['973']
La région 4 (La Réunion) a 1 départements : ['974']
La région 11 (Île-de-France) a 8 départements : ['77' '95' '78' '91' '92' '94' '93' '75']
La région 24 (Centre-Val de Loire) a 6 départements : ['18' '28' '45' '41' '36' '37']
La région 27 (Bourgogne-Franche-Comté) a 8 départements : ['39' '25' '58' '21' '70' '71' '89' '90']
La région 28 (Normandie) a 5 départements : ['50' '76' '61' '14' '27']
La région 32 (Hauts-de-France) a 5 départements : ['80' '62' '60' '02' '59']
La région 44 (Grand Est) a 10 départements : ['55' '54' '51' '52' '88' '57' '08' '10' '67' '68']
La région 52 (Pays de la Loire) a 5 départements : ['72' '53' '49' '85' '44']
La région 53 (Bretagne) a 4 départements : ['22' '35' '56' '29']
La région 75 (Nouvelle-Aquitaine) a 12 départements : ['23' '24' '19' '16' '47' '33' '40' '64' '87' '17' '79' '86']
La région 76 (Occitanie) a 13 départements : ['31' '11' '09' '65' '66' '34' '30' '32' '12' '81' '48' '82' '46']
La région 84 (Auvergne-Rhône-Alpes) a 12 départements : ['26' '38' '63' '15' '43' '01' '73' '03' '42' '07' '74' '69']
La région 93 (Provence-Alpes-Côte d'Azur) a 6 départements : ['04' '05' '83' '84' '06' '13']
La région 94 (Corse) a 2 départements : ['2B' '2A']1.3.2 Combien de communes par région ?
Attention, avec nunique(), on compte le nombre de valeurs uniques, or certains noms de communes sont dupliqués. Il faut donc utiliser une autre méthode comme pivot_table() avec aggfunc='count'.
df_communes_by_region = df.pivot_table(index='REG', values='LIBGEO', aggfunc='count')
df_communes_by_region
# df.groupby('REG')[2021].count()
# df[['REG','DEP','LIBGEO']].pivot_table(index='REG', values='LIBGEO', aggfunc='count')| LIBGEO | |
|---|---|
| REG | |
| 1 | 32 |
| 2 | 34 |
| 3 | 22 |
| 4 | 24 |
| 11 | 1287 |
| 24 | 1757 |
| 27 | 3699 |
| 28 | 2651 |
| 32 | 3787 |
| 44 | 5119 |
| 52 | 1233 |
| 53 | 1207 |
| 75 | 4308 |
| 76 | 4453 |
| 84 | 4028 |
| 93 | 946 |
| 94 | 360 |
1.3.2.1 Bonus : visualisation des données sur une carte choroplèthe
On peut visualiser le nombre de communes par région sur une carte de France. Cette visualisation nécéssite de récupérer les coordonnées géographiques des régions et de les associer au DataFrame df_communes_by_region. Pour cela, nous pouvons utiliser une base de données géographiques telle que GeoJSON. Ensuite, nous pouvons utiliser la bibliothèque Plotly pour créer une carte choroplèthe en utilisant les coordonnées géographiques et les données de population par région. Voici un exemple de code pour réaliser cette visualisation :
# Préparer les données pour la carte choroplèth
# ===============================================
# Il faut réinitialiser l'index pour que 'REG' devienne une colonne normale
df_communes_by_region = df_communes_by_region.reset_index()
# Renommer les colonnes
df_communes_by_region.columns = ['REG', 'Nombre_communes']
# Ajouter les noms des régions
df_communes_by_region['Nom_Region'] = df_communes_by_region['REG'].map(region_dict)
df_communes_by_region| REG | Nombre_communes | Nom_Region | |
|---|---|---|---|
| 0 | 1 | 32 | Guadeloupe |
| 1 | 2 | 34 | Martinique |
| 2 | 3 | 22 | Guyane |
| 3 | 4 | 24 | La Réunion |
| 4 | 11 | 1287 | Île-de-France |
| 5 | 24 | 1757 | Centre-Val de Loire |
| 6 | 27 | 3699 | Bourgogne-Franche-Comté |
| 7 | 28 | 2651 | Normandie |
| 8 | 32 | 3787 | Hauts-de-France |
| 9 | 44 | 5119 | Grand Est |
| 10 | 52 | 1233 | Pays de la Loire |
| 11 | 53 | 1207 | Bretagne |
| 12 | 75 | 4308 | Nouvelle-Aquitaine |
| 13 | 76 | 4453 | Occitanie |
| 14 | 84 | 4028 | Auvergne-Rhône-Alpes |
| 15 | 93 | 946 | Provence-Alpes-Côte d'Azur |
| 16 | 94 | 360 | Corse |
# Pour comprendre la structure du GeoJSON
# ========================================================
# import json
# print("=== Structure du GeoJSON ===")
# print(f"Type: {type(france_regions_geo)}")
# print(f"Clés principales: {france_regions_geo.keys()}")
# print(f"\nNombre de régions: {len(france_regions_geo['features'])}")
# print("\n=== Exemple d'une région (première feature) ===")
# first_feature = france_regions_geo['features'][0]
# print(f"Clés de la feature: {first_feature.keys()}")
# print(f"\nPropriétés disponibles:")
# print(json.dumps(first_feature['properties'], indent=2, ensure_ascii=False))
# print("\n=== TOUTES les régions avec leurs propriétés ===")
# for i, feature in enumerate(france_regions_geo['features']):
# props = feature['properties']
# print(f"\nRégion {i+1}: {json.dumps(props, indent=2, ensure_ascii=False)}")# Créer la carte choroplèth avec plotly
# ========================================
# Appel utilisant les codes des régions
fig = px.choropleth(
df_communes_by_region, # DataFrame avec les données
geojson=france_regions_geo, # Données géographiques au format GeoJSON
# Appel utilisant les codes des régions
locations='REG', # Colonne du DataFrame avec les codes des régions
featureidkey='properties.code', # Clé du code dans le GeoJSON
# Appel utilisant les noms des régions
#locations='Nom_Region', # Doit correspondre aux noms dans le GeoJSON
#featureidkey='properties.nom', # Clé dans le GeoJSON pour faire correspondre
color='Nombre_communes', # Colonne pour la coloration
color_continuous_scale='Blues', # Palette de couleurs
labels={'Nombre_communes': 'Nombre de communes'}, # Étiquette pour la légende
title='Nombre de communes par région en France',
hover_data={'REG': True, 'Nom_Region': True, 'Nombre_communes': True}, # Infos au survol
scope='europe', # Centrer la carte sur l'Europe (optionnel)
# projection="mercator", # Projection cartographique, par défaut "equirectangular"
)
# Ajuster la vue sur la France et n'afficher que la France
fig.update_geos( fitbounds="locations", visible=False )
# fig.update_layout(width=800, height=600)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
fig.show()1.3.3 Combien de communes par région et département ?
df_grbt_REG_DEP_LIBGEO = df.groupby(['REG', 'DEP'])['LIBGEO'].count()
# On peut utiliser count car dans chaque département le nom des communes est unique
# Pour vérifier on affiché le nombre de communes dans la région PACA (93) selon le département
df_grbt_REG_DEP_LIBGEO[93] DEP
04 198
05 162
06 163
13 119
83 153
84 151
Name: LIBGEO, dtype: int641.3.4 Combien de personnes par region en 2021 ?
df_sum_2021_by_region = df.pivot_table(index='REG', values='2021', aggfunc='sum', margins=True)
# df.groupby('REG')['2021'].sum()
df_sum_2021_by_region| 2021 | |
|---|---|
| REG | |
| 1 | 384315.0 |
| 2 | 360749.0 |
| 3 | 286618.0 |
| 4 | 871157.0 |
| 11 | 12317279.0 |
| 24 | 2573303.0 |
| 27 | 2800194.0 |
| 28 | 3327966.0 |
| 32 | 5995292.0 |
| 44 | 5561287.0 |
| 52 | 3853999.0 |
| 53 | 3394567.0 |
| 75 | 6069352.0 |
| 76 | 6022176.0 |
| 84 | 8114361.0 |
| 93 | 5127840.0 |
| 94 | 347597.0 |
| All | 67408052.0 |
Quelle est la région la plus peuplée en 2021 ?
# margins=True ajoute une ligne "All" qu'on doit retirer avant de tracer
df_sum_2021_by_region = df_sum_2021_by_region.drop(index="All")
region_max_2021 = df_sum_2021_by_region.idxmax()
display(region_max_2021) # indice = code de la région la plus peuplée en 2021
region_dict[region_max_2021.iloc[0]] # nom de la région la plus peuplée en 20212021 11
dtype: object'Île-de-France'df_sum_2021_by_region.index = ( df_sum_2021_by_region.index.map(region_dict) )
df_sum_2021_by_region.plot(
kind='bar',
figsize=(8, 5)
)
plt.xticks(rotation=45, ha='right')
plt.grid()
plt.title("Nombre d'habitants en 2021 par région")
plt.xlabel("Région")
plt.ylabel("Nombre d'habitants")
plt.show()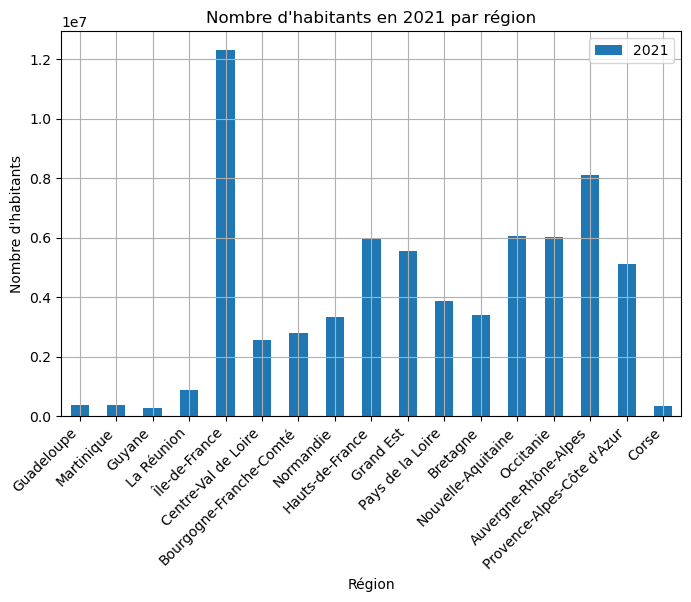
# Tri en ordre croissant
df_sum_2021_by_region_plot = df_sum_2021_by_region.sort_values(by="2021", ascending=True)
# Pie chart
df_sum_2021_by_region_plot.plot.pie(
y='2021',
autopct='%1.1f%%',
figsize=(8, 8),
legend=False
)
plt.ylabel("") # enlève le label y
plt.title("Répartition de la population 2021 par région")
plt.tight_layout()
plt.show()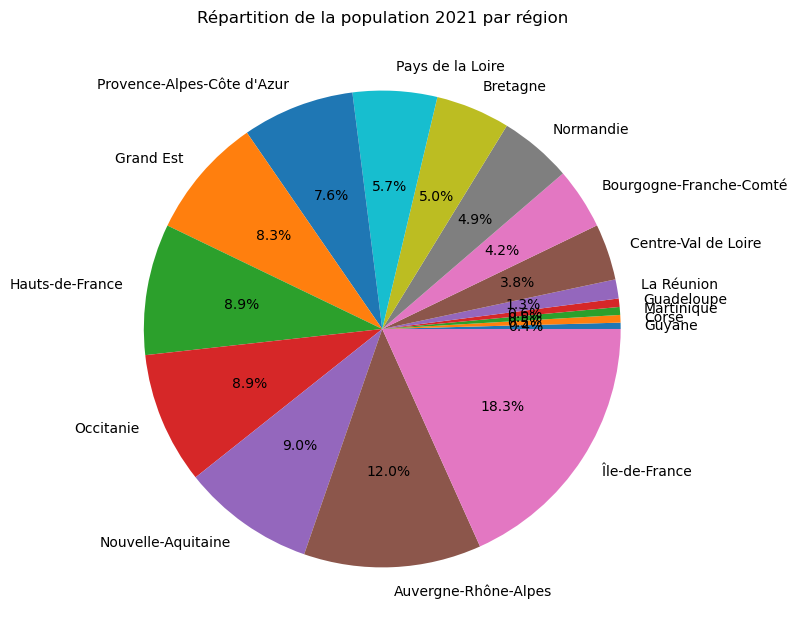
Bonus : afficher la population totale par région dans une carte choroplèthe.
# Préparer les données de population par région
df_sum_2021_by_region_reset = df_sum_2021_by_region_plot.reset_index()
df_sum_2021_by_region_reset.columns = ['REG', 'Population']
# Ajouter les noms des régions
df_sum_2021_by_region_reset['Nom_Region'] = df_sum_2021_by_region_reset['REG'].map(region_dict)
# Créer la carte choroplèth avec plotly
fig = px.choropleth(
df_sum_2021_by_region_reset,
geojson=france_regions_geo,
locations='REG', # doit correspondre à "properties.nom" dans le GeoJSON
featureidkey='properties.nom',
color='Population',
color_continuous_scale='YlOrRd',
labels={'Population': 'Nombre d\'habitants'},
title='Population par région en France (2021)',
hover_data={'Nom_Region': True, 'Population': ':,'},
projection="mercator",
)
# Ajuster la vue sur la France et n'afficher que la France
fig.update_geos( fitbounds="locations", visible=False )
# fig.update_layout(height=600, width=800)
fig.update_layout(margin={"r":0,"t":0,"l":0,"b":0})
fig.show()1.4 Étude de la région PACA
Dans la suite nous considérérons les données de la région Provence-Alpes-Côte d’Azur que nous sauvons dans un DataFrame df_PACA.
# Méthode 1
# mask = (df['REG'] == 93)
# df_PACA = df[mask]
# Méthode 2
df_grbyREG = df.groupby('REG')
df_PACA = df_grbyREG.get_group(name=93)
df_IdF = df_grbyREG.get_group(name=11)
# Affichage
df_PACA| REG | DEP | LIBGEO | 2021 | 2020 | 2019 | 2018 | 2017 | 2016 | 2015 | ... | 1926 | 1921 | 1911 | 1906 | 1901 | 1896 | 1891 | 1886 | 1881 | 1876 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 13 | 93 | 04 | Majastres | 5 | 4 | 4 | 4 | 4 | 4 | 3 | ... | 61 | 76 | 150 | 183 | 211 | 221 | 259 | 273 | 276 | 303 |
| 21 | 93 | 05 | La Haute-Beaume | 8 | 8 | 8 | 8 | 9 | 9 | 9 | ... | 41 | 41 | 47 | 52 | 49 | 47 | 45 | 59 | 59 | 64 |
| 25 | 93 | 83 | Vérignon | 9 | 9 | 9 | 9 | 10 | 10 | 10 | ... | 60 | 60 | 66 | 70 | 85 | 77 | 94 | 88 | 81 | 88 |
| 26 | 93 | 04 | Saint-Martin-lès-Seyne | 10 | 12 | 13 | 13 | 14 | 13 | 13 | ... | 86 | 96 | 108 | 110 | 109 | 113 | 132 | 138 | 150 | 145 |
| 34 | 93 | 05 | Nossage-et-Bénévent | 12 | 14 | 15 | 16 | 15 | 15 | 14 | ... | 32 | 34 | 48 | 51 | 57 | 46 | 53 | 67 | 66 | 54 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 34890 | 93 | 84 | Avignon | 90330 | 90597 | 91143 | 91729 | 91921 | 92378 | 92130 | ... | 51685 | 46033 | 47110 | 46162 | 44809 | 43100 | 41519 | 39182 | 35981 | 36317 |
| 34919 | 93 | 13 | Aix-en-Provence | 147478 | 147122 | 145133 | 143097 | 142482 | 143006 | 142668 | ... | 35106 | 29983 | 29836 | 29829 | 29418 | 28913 | 28357 | 29057 | 29257 | 28693 |
| 34932 | 93 | 83 | Toulon | 180452 | 179659 | 178745 | 176198 | 171953 | 169634 | 167479 | ... | 115120 | 106331 | 104582 | 103549 | 101602 | 95276 | 77747 | 70122 | 70103 | 70509 |
| 34943 | 93 | 06 | Nice | 348085 | 343477 | 342669 | 341032 | 340017 | 342637 | 342522 | ... | 184441 | 155839 | 142940 | 134232 | 105109 | 93760 | 88273 | 77478 | 66279 | 53397 |
| 34946 | 93 | 13 | Marseille | 873076 | 870321 | 870731 | 868277 | 863310 | 862211 | 861635 | ... | 652196 | 586341 | 550619 | 517498 | 491161 | 442239 | 403749 | 376143 | 360099 | 318868 |
946 rows × 38 columns
1.4.1 Combien de départements dans la région PACA ?
1.4.2 Combien de communes dans la région PACA ?
1.4.3 Combien de commune dans chaque département de la région PACA ?
| LIBGEO | |
|---|---|
| DEP | |
| 04 | 198 |
| 05 | 162 |
| 06 | 163 |
| 13 | 119 |
| 83 | 153 |
| 84 | 151 |
| All | 946 |
Est-ce qu’il existe des communes avec le même nom dans la région Provence-Alpes-Côte d’Azur ?
Il y a bien 12 communes avec le même nom dans la région Provence-Alpes-Côte d’Azur (mais pas le même CODGEO). Lesquelles ?
duplicated_names = df_PACA['LIBGEO'].duplicated(keep=False) # c'est un masque, l'option keep=False signifie que chaque valeur de la colonne qui apparaît plus d'une fois sera marquée comme True. Les valeurs uniques (apparaissant une seule fois) seront marquées comme False.
communes_duplicated_sorted = df_PACA[duplicated_names].sort_values(by='LIBGEO')
communes_duplicated_sorted| REG | DEP | LIBGEO | 2021 | 2020 | 2019 | 2018 | 2017 | 2016 | 2015 | ... | 1926 | 1921 | 1911 | 1906 | 1901 | 1896 | 1891 | 1886 | 1881 | 1876 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 27562 | 93 | 04 | Aiglun | 1413 | 1420 | 1432 | 1432 | 1440 | 1412 | 1384 | ... | 174 | 187 | 218 | 220 | 239 | 231 | 259 | 268 | 293 | 298 |
| 3063 | 93 | 06 | Aiglun | 93 | 93 | 94 | 93 | 91 | 89 | 86 | ... | 115 | 100 | 142 | 152 | 150 | 175 | 241 | 187 | 218 | 268 |
| 30188 | 93 | 06 | Aspremont | 2300 | 2271 | 2272 | 2230 | 2187 | 2144 | 2139 | ... | 424 | 510 | 591 | 611 | 579 | 615 | 711 | 512 | 727 | 513 |
| 15215 | 93 | 05 | Aspremont | 366 | 369 | 369 | 363 | 358 | 350 | 341 | ... | 300 | 330 | 376 | 396 | 421 | 451 | 453 | 507 | 512 | 501 |
| 19004 | 93 | 05 | Châteauvieux | 528 | 519 | 506 | 496 | 490 | 488 | 485 | ... | 127 | 141 | 173 | 165 | 177 | 179 | 178 | 201 | 202 | 231 |
| 2072 | 93 | 83 | Châteauvieux | 75 | 77 | 79 | 81 | 83 | 87 | 85 | ... | 66 | 66 | 76 | 80 | 89 | 82 | 93 | 92 | 104 | 109 |
| 15388 | 93 | 83 | Esparron | 371 | 370 | 371 | 364 | 356 | 349 | 345 | ... | 265 | 267 | 284 | 310 | 346 | 367 | 364 | 371 | 416 | 410 |
| 1254 | 93 | 05 | Esparron | 58 | 58 | 57 | 56 | 51 | 45 | 40 | ... | 112 | 107 | 143 | 128 | 132 | 162 | 166 | 172 | 190 | 213 |
| 34587 | 93 | 83 | La Garde | 25912 | 25563 | 25505 | 25380 | 25126 | 25236 | 25047 | ... | 3048 | 2827 | 3037 | 2961 | 2791 | 2398 | 2171 | 1971 | 1819 | 1896 |
| 4874 | 93 | 04 | La Garde | 124 | 121 | 118 | 104 | 89 | 75 | 77 | ... | 119 | 116 | 122 | 156 | 180 | 211 | 218 | 238 | 237 | 246 |
| 17862 | 93 | 05 | La Rochette | 475 | 473 | 474 | 470 | 466 | 469 | 472 | ... | 265 | 261 | 280 | 274 | 260 | 271 | 267 | 302 | 382 | 276 |
| 1915 | 93 | 04 | La Rochette | 72 | 74 | 75 | 72 | 70 | 67 | 66 | ... | 168 | 190 | 241 | 258 | 259 | 272 | 276 | 286 | 282 | 310 |
| 32836 | 93 | 83 | Le Castellet | 5285 | 4578 | 3873 | 3887 | 3886 | 3875 | 3947 | ... | 1324 | 1232 | 1314 | 1242 | 1332 | 1353 | 1293 | 1295 | 1384 | 1744 |
| 13105 | 93 | 04 | Le Castellet | 301 | 298 | 299 | 296 | 293 | 289 | 292 | ... | 177 | 181 | 198 | 186 | 206 | 218 | 220 | 250 | 246 | 228 |
| 27587 | 93 | 84 | Mirabeau | 1419 | 1389 | 1344 | 1324 | 1288 | 1253 | 1218 | ... | 302 | 315 | 408 | 420 | 450 | 493 | 484 | 549 | 505 | 558 |
| 18559 | 93 | 04 | Mirabeau | 509 | 512 | 511 | 511 | 511 | 511 | 510 | ... | 220 | 255 | 314 | 355 | 374 | 388 | 404 | 411 | 481 | 507 |
| 7468 | 93 | 05 | Rousset | 172 | 177 | 181 | 182 | 183 | 179 | 171 | ... | 189 | 163 | 176 | 166 | 177 | 197 | 208 | 211 | 224 | 225 |
| 32814 | 93 | 13 | Rousset | 5209 | 4977 | 4918 | 4881 | 4844 | 4811 | 4768 | ... | 705 | 862 | 713 | 683 | 668 | 684 | 693 | 730 | 777 | 853 |
| 32350 | 93 | 06 | Saint-Jeannet | 4303 | 4317 | 4246 | 4157 | 4128 | 4099 | 4071 | ... | 857 | 834 | 981 | 939 | 965 | 1061 | 1377 | 1113 | 1062 | 1027 |
| 798 | 93 | 04 | Saint-Jeannet | 47 | 48 | 48 | 50 | 54 | 59 | 63 | ... | 116 | 112 | 162 | 183 | 225 | 201 | 238 | 251 | 264 | 242 |
| 3310 | 93 | 04 | Sigoyer | 98 | 101 | 103 | 104 | 107 | 105 | 104 | ... | 120 | 128 | 150 | 151 | 162 | 161 | 161 | 190 | 206 | 218 |
| 22301 | 93 | 05 | Sigoyer | 730 | 727 | 708 | 688 | 665 | 664 | 664 | ... | 472 | 467 | 526 | 555 | 561 | 591 | 623 | 668 | 674 | 712 |
| 9567 | 93 | 05 | Vitrolles | 214 | 210 | 209 | 204 | 204 | 205 | 206 | ... | 206 | 196 | 211 | 236 | 237 | 268 | 298 | 319 | 350 | 343 |
| 34709 | 93 | 13 | Vitrolles | 35532 | 34418 | 33333 | 33101 | 33310 | 33880 | 34089 | ... | 812 | 794 | 819 | 875 | 892 | 910 | 910 | 1007 | 1010 | 1082 |
24 rows × 38 columns
1.4.4 Combien de personnes habitaient en PACA en 2021 ?
1.4.5 Combien de personnes habitaient dans chaque département de la région PACA en 2021 ?
PACA_DEP_2021 = df_PACA.pivot_table(index='DEP', values='2021', aggfunc='sum', margins=True)
PACA_DEP_2021| 2021 | |
|---|---|
| DEP | |
| 04 | 166077.0 |
| 05 | 140976.0 |
| 06 | 1103941.0 |
| 13 | 2056943.0 |
| 83 | 1095337.0 |
| 84 | 564566.0 |
| All | 5127840.0 |
# margins=True ajoute une ligne "All" qu'on doit retirer avant de tracer
PACA_DEP_2021_plot = PACA_DEP_2021.drop(index="All")
PACA_DEP_2021_plot.index = ( PACA_DEP_2021_plot.index.map(dep_PACA))
PACA_DEP_2021_plot.plot(
kind='bar',
figsize=(8, 5)
)
plt.title("Nombre d'habitants en 2021 par département (PACA)")
plt.xlabel("Département")
plt.ylabel("Nombre d'habitants")
plt.xticks(rotation=45, ha='right')
plt.show()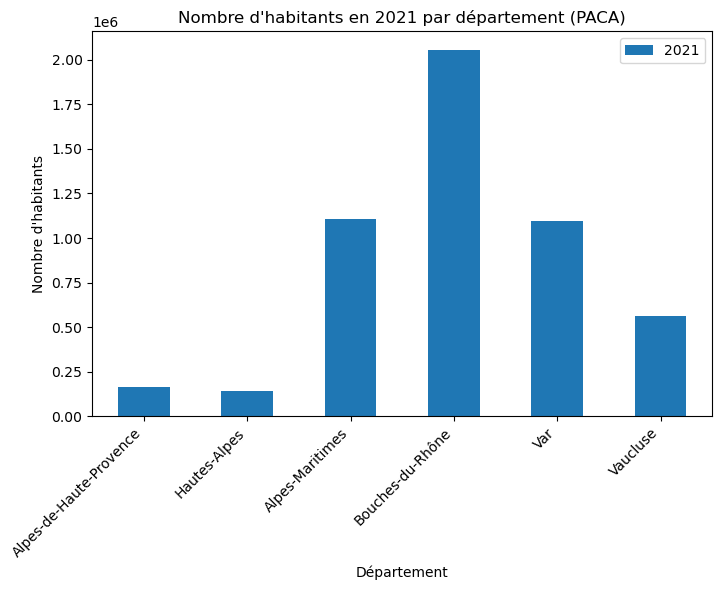

1.5 Étude du département VAR
Dans la suite nous allons considérer les données du département du Var que nous sauvons dans un DataFrame df_83.
# Methode 1
# df_83 = df[ df['DEP'] == '83' ]
# df_83 = df_PACA[ df_PACA['DEP'] == '83' ]
# Methode 2
df_83 = df_PACA.groupby('DEP').get_group(name='83')
# Affichage
df_83| REG | DEP | LIBGEO | 2021 | 2020 | 2019 | 2018 | 2017 | 2016 | 2015 | ... | 1926 | 1921 | 1911 | 1906 | 1901 | 1896 | 1891 | 1886 | 1881 | 1876 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 25 | 93 | 83 | Vérignon | 9 | 9 | 9 | 9 | 10 | 10 | 10 | ... | 60 | 60 | 66 | 70 | 85 | 77 | 94 | 88 | 81 | 88 |
| 119 | 93 | 83 | Brenon | 22 | 23 | 25 | 27 | 29 | 31 | 30 | ... | 25 | 26 | 45 | 33 | 56 | 63 | 67 | 75 | 78 | 81 |
| 748 | 93 | 83 | Le Bourguet | 45 | 42 | 41 | 38 | 35 | 31 | 30 | ... | 56 | 78 | 124 | 118 | 121 | 151 | 139 | 149 | 154 | 146 |
| 975 | 93 | 83 | Riboux | 51 | 51 | 49 | 48 | 46 | 44 | 42 | ... | 21 | 16 | 21 | 34 | 42 | 39 | 36 | 35 | 40 | 47 |
| 2072 | 93 | 83 | Châteauvieux | 75 | 77 | 79 | 81 | 83 | 87 | 85 | ... | 66 | 66 | 76 | 80 | 89 | 82 | 93 | 92 | 104 | 109 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 34739 | 93 | 83 | Draguignan | 39745 | 39434 | 39433 | 39106 | 39340 | 40053 | 40278 | ... | 9441 | 9199 | 9974 | 9770 | 9671 | 9963 | 9816 | 9753 | 9133 | 9223 |
| 34828 | 93 | 83 | Hyères | 55103 | 54615 | 54821 | 55069 | 55588 | 55772 | 56478 | ... | 19816 | 17476 | 21339 | 17790 | 17659 | 14978 | 11752 | 10577 | 10863 | 9639 |
| 34833 | 93 | 83 | Fréjus | 57082 | 55750 | 54458 | 53786 | 52672 | 53168 | 52897 | ... | 9091 | 9451 | 4022 | 4190 | 4156 | 3510 | 3139 | 3540 | 3135 | 3478 |
| 34847 | 93 | 83 | La Seyne-sur-Mer | 62763 | 62232 | 62987 | 62888 | 63936 | 64620 | 64903 | ... | 23504 | 22066 | 21042 | 18808 | 20003 | 15564 | 13650 | 12540 | 11498 | 10148 |
| 34932 | 93 | 83 | Toulon | 180452 | 179659 | 178745 | 176198 | 171953 | 169634 | 167479 | ... | 115120 | 106331 | 104582 | 103549 | 101602 | 95276 | 77747 | 70122 | 70103 | 70509 |
153 rows × 38 columns
Combien de communes sont présentes dans le département du Var ?
Est-ce qu’il existe des communes avec le même nom dans le département du VAR ?
Pour choisir une commune, on va d’abord afficher toutes les communes du département du Var (pour vérifier l’orthographe) :
# première idée : on affiche toutes les communes mais elles sont trop nombreuses
sorted(df_83['LIBGEO'].tolist())['Aiguines',
'Ampus',
'Artignosc-sur-Verdon',
'Artigues',
'Aups',
'Bagnols-en-Forêt',
'Bandol',
'Bargemon',
'Bargème',
'Barjols',
'Baudinard-sur-Verdon',
'Bauduen',
'Belgentier',
'Besse-sur-Issole',
'Bormes-les-Mimosas',
'Bras',
'Brenon',
'Brignoles',
'Brue-Auriac',
'Cabasse',
'Callas',
'Callian',
'Camps-la-Source',
'Carcès',
'Carnoules',
'Carqueiranne',
'Cavalaire-sur-Mer',
'Châteaudouble',
'Châteauvert',
'Châteauvieux',
'Claviers',
'Cogolin',
'Collobrières',
'Comps-sur-Artuby',
'Correns',
'Cotignac',
'Cuers',
'Draguignan',
'Entrecasteaux',
'Esparron',
'Fayence',
'Figanières',
'Flassans-sur-Issole',
'Flayosc',
'Forcalqueiret',
'Fox-Amphoux',
'Fréjus',
'Garéoult',
'Gassin',
'Ginasservis',
'Gonfaron',
'Grimaud',
'Hyères',
'La Bastide',
"La Cadière-d'Azur",
'La Celle',
'La Crau',
'La Croix-Valmer',
'La Farlède',
'La Garde',
'La Garde-Freinet',
'La Londe-les-Maures',
'La Martre',
'La Motte',
'La Môle',
'La Roque-Esclapon',
'La Roquebrussanne',
'La Seyne-sur-Mer',
'La Valette-du-Var',
'La Verdière',
'Le Beausset',
'Le Bourguet',
'Le Cannet-des-Maures',
'Le Castellet',
'Le Lavandou',
'Le Luc',
'Le Muy',
'Le Plan-de-la-Tour',
'Le Pradet',
'Le Revest-les-Eaux',
'Le Thoronet',
'Le Val',
"Les Adrets-de-l'Estérel",
'Les Arcs',
'Les Mayons',
'Les Salles-sur-Verdon',
'Lorgues',
'Mazaugues',
'Moissac-Bellevue',
'Mons',
'Montauroux',
'Montferrat',
'Montfort-sur-Argens',
'Montmeyan',
'Méounes-lès-Montrieux',
'Nans-les-Pins',
'Néoules',
'Ollioules',
'Ollières',
'Pierrefeu-du-Var',
'Pignans',
"Plan-d'Aups-Sainte-Baume",
'Pontevès',
'Pourcieux',
'Pourrières',
'Puget-Ville',
'Puget-sur-Argens',
'Ramatuelle',
'Rayol-Canadel-sur-Mer',
'Rians',
'Riboux',
'Rocbaron',
'Roquebrune-sur-Argens',
'Rougiers',
'Régusse',
'Saint-Antonin-du-Var',
'Saint-Cyr-sur-Mer',
'Saint-Julien',
'Saint-Mandrier-sur-Mer',
'Saint-Martin-de-Pallières',
'Saint-Maximin-la-Sainte-Baume',
'Saint-Paul-en-Forêt',
'Saint-Raphaël',
'Saint-Tropez',
'Saint-Zacharie',
'Sainte-Anastasie-sur-Issole',
'Sainte-Maxime',
'Salernes',
'Sanary-sur-Mer',
'Seillans',
"Seillons-Source-d'Argens",
'Signes',
'Sillans-la-Cascade',
'Six-Fours-les-Plages',
'Solliès-Pont',
'Solliès-Toucas',
'Solliès-Ville',
'Tanneron',
'Taradeau',
'Tavernes',
'Toulon',
'Tourrettes',
'Tourtour',
'Tourves',
'Trans-en-Provence',
'Trigance',
'Varages',
'Vidauban',
'Villecroze',
'Vinon-sur-Verdon',
'Vins-sur-Caramy',
'Vérignon',
'Évenos']On cherche alors une commune en particulier avec un filtre sur le nom de la commune avec la méthode str.contains() :
commune_recherchee = 'Sol'
mask = df_83['LIBGEO'].str.contains(commune_recherchee, case=True, na=False)
# case = False pour ne pas tenir compte de la casse,
# na = False pour ne pas tenir compte des valeurs manquantes
df_83[ mask ]| REG | DEP | LIBGEO | 2021 | 2020 | 2019 | 2018 | 2017 | 2016 | 2015 | ... | 1926 | 1921 | 1911 | 1906 | 1901 | 1896 | 1891 | 1886 | 1881 | 1876 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 30591 | 93 | 83 | Solliès-Ville | 2529 | 2523 | 2526 | 2488 | 2450 | 2412 | 2391 | ... | 479 | 376 | 488 | 492 | 486 | 575 | 536 | 610 | 653 | 712 |
| 33075 | 93 | 83 | Solliès-Toucas | 5912 | 5867 | 5753 | 5696 | 5719 | 5741 | 5756 | ... | 799 | 777 | 882 | 900 | 933 | 1017 | 1043 | 1054 | 1171 | 1227 |
| 34110 | 93 | 83 | Solliès-Pont | 12080 | 11974 | 11762 | 11496 | 11149 | 11056 | 10951 | ... | 2666 | 2689 | 2757 | 2867 | 2784 | 2701 | 2705 | 2662 | 2891 | 2905 |
3 rows × 38 columns
Choisissons une commune et affichons la ligne correspondant à cette commune :
Commune = 'Solliès-Toucas'
# Commune = 'Toulon'
mask = df_83['LIBGEO'] == Commune
df_Commune = df_83[mask]
df_Commune| REG | DEP | LIBGEO | 2021 | 2020 | 2019 | 2018 | 2017 | 2016 | 2015 | ... | 1926 | 1921 | 1911 | 1906 | 1901 | 1896 | 1891 | 1886 | 1881 | 1876 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 33075 | 93 | 83 | Solliès-Toucas | 5912 | 5867 | 5753 | 5696 | 5719 | 5741 | 5756 | ... | 799 | 777 | 882 | 900 | 933 | 1017 | 1043 | 1054 | 1171 | 1227 |
1 rows × 38 columns
Nous allons afficher l’évolution de la population d’une commune de 1876 à 2021:
# xx = [int(col[-4:]) for col in df_Commune.columns[3:]] # les années
# yy = [int(val.replace('\xa0', '')) for val in df_Commune.values[0][3:]]
# xx = df_Commune.columns[3:].map(int) # les années, on utilise map pour appliquer int à chaque label de colonne
xx = np.array([int(col) for col in df_Commune.columns[3:]]) # les années
yy = df_Commune.values[0][3:] # les valeurs de l'unique ligne correspondant à la commune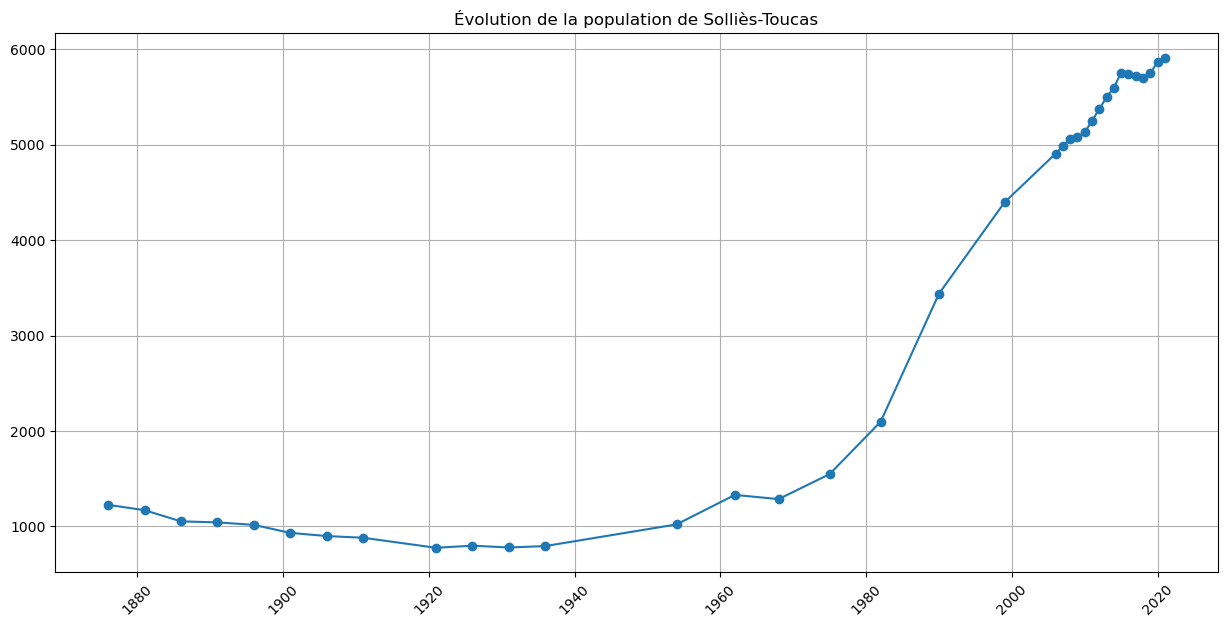
1.6 Affichages divers
Pour afficher l’évolution de la population de la France métropolitaine de 1876 à 2021, il faut sommer les colonnes.
# Copie du DataFrame sans la première ligne
df2 = df.iloc[1:].copy()
xx = df2.columns[3:].map(int)
# Nettoyage des valeurs en supprimant les caractères '\xa0' et conversion en entier dans la copie
#df2[df2.columns[3:]] = df2[df2.columns[3:]].applymap(lambda x: int(x.replace('\xa0', '')) if isinstance(x, str) else x)
# Calcul de la somme des valeurs dans chaque colonne de la copie
yy = df2[df2.columns[3:]].sum()
# Le résulta est une Series : la première colonne est l'indice (les années), la seconde les valeurs
# Vérifions que la somme est correcte : selon l'INSEE, en 2021 en France la population totale était de 67,76 millions d'habitants
print(f"En {yy.index[0]}, la population totale de France était de {yy.iloc[0]:e} habitants.")En 2021, la population totale de France était de 6.740805e+07 habitants.import matplotlib.pyplot as plt
import numpy as np
plt.figure(figsize=(15, 7))
plt.plot(xx,yy, 'o-')
plt.xticks(rotation=45) # Incline les labels des colonnes de 45 degrés
plt.grid()
plt.title(f'Évolution de la population de France');
On affiche l’évolution de la population de la France métropolitaine de 1876 à 2021 par région :
import matplotlib.pyplot as plt
# Colonnes des années (de 2021 à 1876)
year_columns = df.columns[3:].map(int)
# Groupement des données par région
df_grbyREG = df.groupby('REG')
# Tracé de l'évolution
plt.figure(figsize=(15, 7))
# Liste des marqueurs
markers = ['o', 's', 'D', '*', '^', 'v', 'p', 'H'] # Ajouter plus si nécessaire
num_markers = len(markers) # Nombre total de marqueurs
for i, reg in enumerate(df_grbyREG.groups.keys()):
yy = df_grbyREG.get_group(reg).iloc[:, 3:].sum()
marker = markers[i % num_markers] # Sélectionner un marqueur cycliquement
plt.plot(year_columns,yy, marker=marker, label=f"Région {reg} ({region_dict[reg]})")
# Personnalisation du graphique
plt.xticks(rotation=45) # Incliner les années
plt.grid()
plt.title("Évolution de la population de France par région")
plt.xlabel("Année")
plt.ylabel("Population")
plt.legend(title="Régions", loc='upper left', bbox_to_anchor=(1, 1))
plt.show()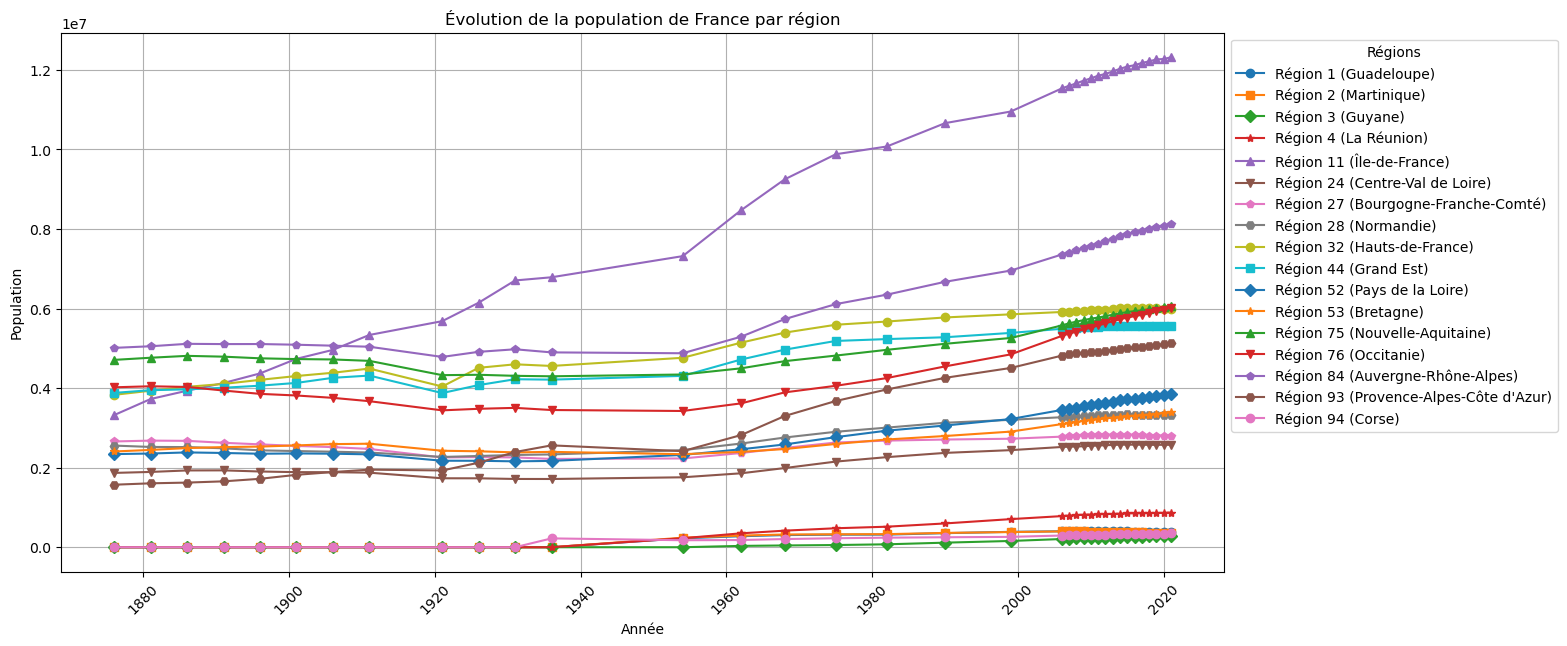
# Colonnes des années (de 2021 à 1876)
year_columns_PACA = df_PACA.columns[3:].map(int)
# Groupement des données par région
df_PACA_grbyDEP = df_PACA.groupby('DEP')
# Tracé de l'évolution
plt.figure(figsize=(15, 7))
# Liste des marqueurs
markers = ['o', 's', 'D', '*', '^', 'v', 'p', 'H'] # Ajouter plus si nécessaire
num_markers = len(markers) # Nombre total de marqueurs
for i, dep in enumerate(df_PACA_grbyDEP.groups.keys()):
yy = df_PACA_grbyDEP.get_group(dep).iloc[:, 3:].sum()
marker = markers[i % num_markers] # Sélectionner un marqueur cycliquement
plt.plot(year_columns_PACA,yy, marker=marker, label=f"Département {dep} ({dep_PACA[dep]})")
# Personnalisation du graphique
plt.xticks(rotation=45) # Incliner les années
plt.grid()
plt.title("Évolution de la population par département dans la région PACA")
plt.xlabel("Année")
plt.ylabel("Population")
plt.legend(title="Départements", loc='upper left', bbox_to_anchor=(1, 1))
plt.show()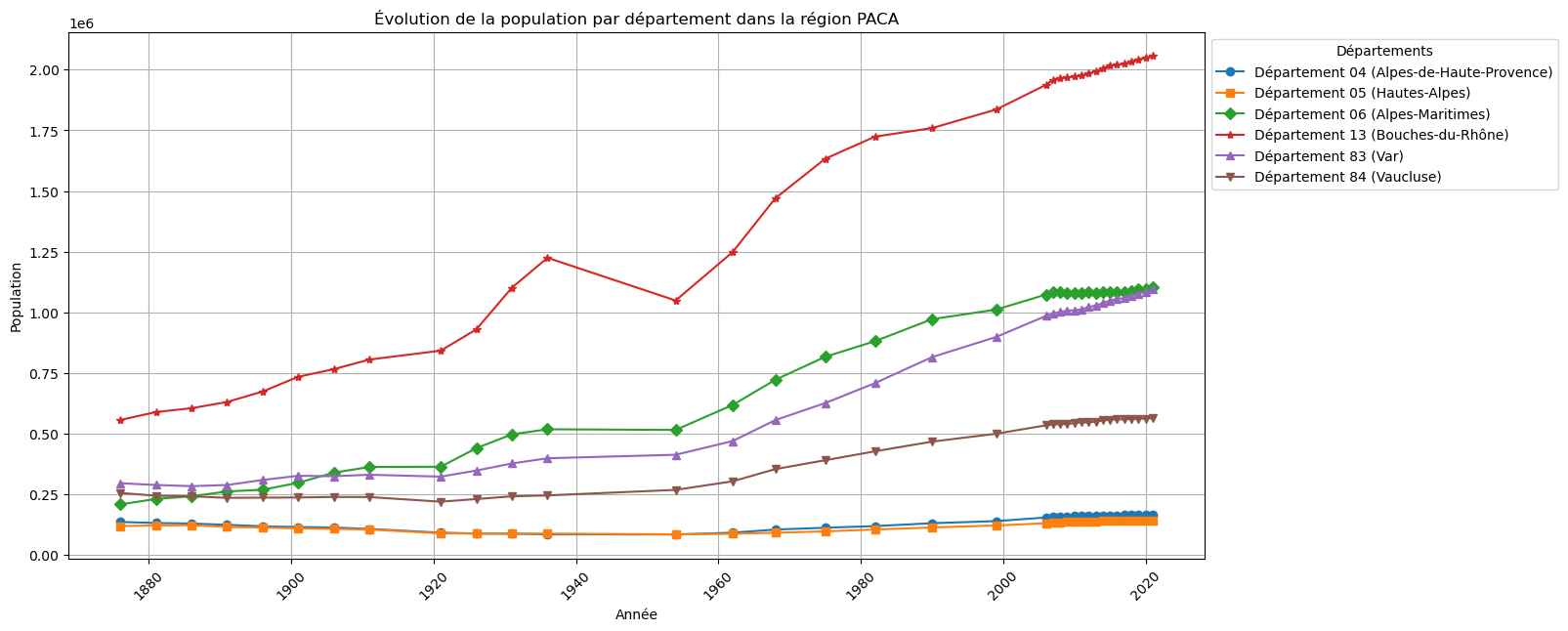
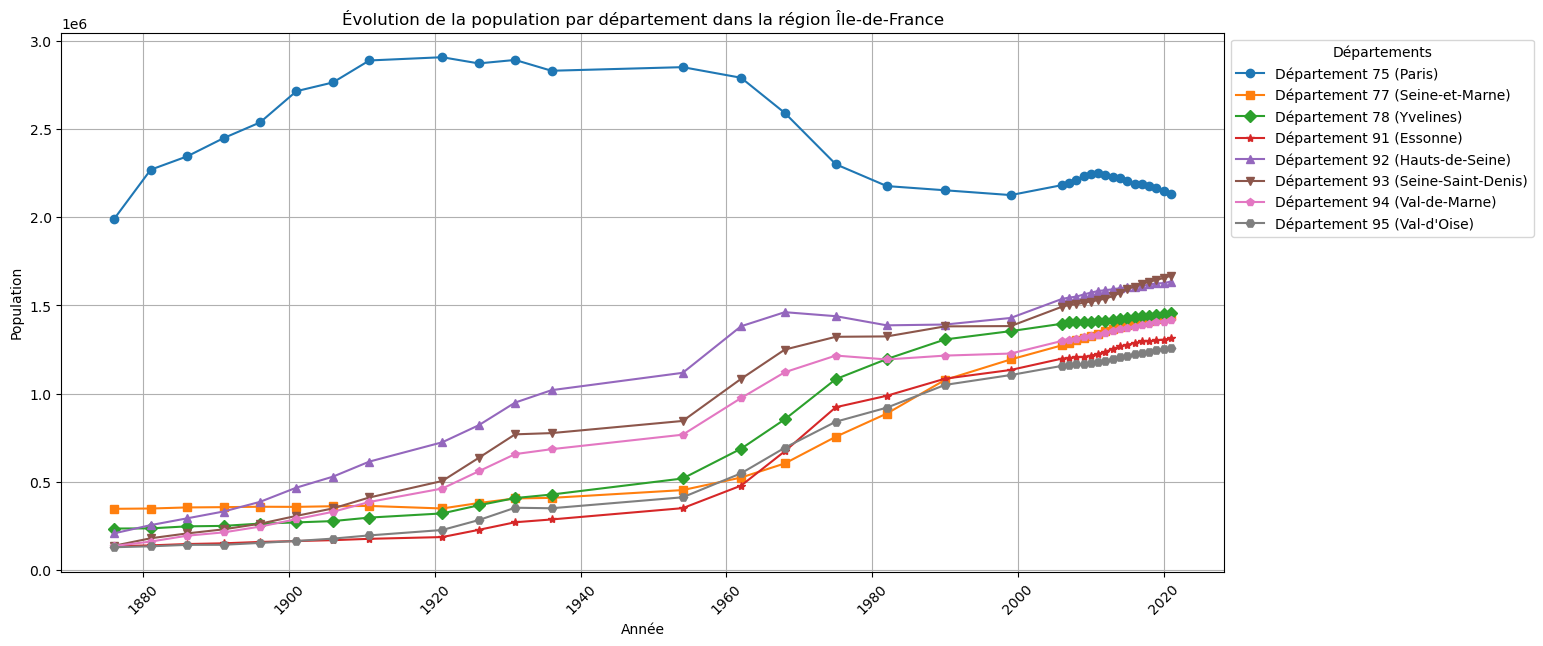
dep_IdF = {
'75': 'Paris',
'77': 'Seine-et-Marne',
'78': 'Yvelines',
'91': 'Essonne',
'92': 'Hauts-de-Seine',
'93': 'Seine-Saint-Denis',
'94': 'Val-de-Marne',
'95': "Val-d'Oise"
}
# Colonnes des années (de 2021 à 1876)
year_columns_IdF = df_IdF.columns[3:].map(int)
# Groupement des données par région
df_IdF_grbyDEP = df_IdF.groupby('DEP')
# Tracé de l'évolution
plt.figure(figsize=(15, 7))
# Liste des marqueurs
markers = ['o', 's', 'D', '*', '^', 'v', 'p', 'H'] # Ajouter plus si nécessaire
num_markers = len(markers) # Nombre total de marqueurs
for i, dep in enumerate(df_IdF_grbyDEP.groups.keys()):
yy = df_IdF_grbyDEP.get_group(dep).iloc[:, 3:].sum()
marker = markers[i % num_markers] # Sélectionner un marqueur cycliquement
plt.plot(year_columns_IdF,yy, marker=marker, label=f"Département {dep} ({dep_IdF[dep]})")
# Personnalisation du graphique
plt.xticks(rotation=45) # Incliner les années
plt.grid()
plt.title("Évolution de la population par département dans la région Île-de-France")
plt.xlabel("Année")
plt.ylabel("Population")
plt.legend(title="Départements", loc='upper left', bbox_to_anchor=(1, 1))
plt.show()