%reset -f%matplotlib inline%autosave 300import sys #only needed to determine Python version numberprint('Python version '+ sys.version)import numpy as npimport matplotlib.pyplot as pltplt.rcParams.update({<span class="st">'font.size'</span>: <span class="dv">12</span>})from scipy.optimize import fsolveimport sympy as symsym.init_printing()
Autosaving every 300 seconds
Python version 3.12.3 (main, Feb 4 2025, 14:48:35) [GCC 13.3.0]
1 Exercice : Estimation de l’Ordre de Convergence des Schémas Numériques
🎯 Objectif : compléter l’implémentation des schémas numériques indiqués et estimer l’ordre de convergence de chaque schéma sur le problème de Cauchy
\(
\begin{cases}
y'(t) = y(t), &\forall t \in I = [0,1], \\
y(0) = 1.
\end{cases}
\)
dont la solution exacte est \(y(t) = e^{t}\).
🛠️ Résultats attendus :
Méthodes multi-pas explicites à \(q\) pas (\(\text{AB}_q\) et \(\text{N}_q\)) : convergence à l’ordre \(q\).
Méthodes multi-pas implicites à \(q\) pas (\(\text{AM}_q\) et \(\text{MS}_q\)) : convergence à l’ordre …
\(q + 1\) si \(q\) est impair,
\(q + 2\) si \(q\) est pair.
Méthodes multi-pas implicites à \(q\) pas (\(\text{BDF}_q\)) : convergence à l’ordre \(q\).
Méthodes predictor-corrector : convergence à l’ordre \(\min(\omega_E + 1, \omega_I)\).
\(\omega_E\) : ordre du schéma predictor (explicite),
\(\omega_I\) : ordre du schéma corrector (implicite).
Méthodes de Runge-Kutta à \(s\) étages : convergence à l’ordre …
\(\le s\) si elles sont explicites,
\(\le 2s\) si elles sont implicites.
🔎 Remarque :
Puisque la fonction \(\varphi(t, y) = y\) est linéaire, toute méthode implicite peut être rendue explicite par un calcul élémentaire.
Cela consiste à expliciter directement, pour chaque schéma, l’expression de \(u_{n+1}\). Cependant, nous pouvons utiliser le module SciPy pour résoudre ces équations sans modifier l’implémentation des schémas. Attention : l’utilisation de fsolve peut réduire l’ordre de convergence global au même ordre que celui de fsolve lui-même. Dans notre exemple ce n’est pas le cas car la fonction \(\varphi\) est linéaire, mais il est important de le garder à l’esprit.
Initialisation des schémas multi-step : les schémas multi-step nécessitent l’initialisation de plusieurs pas pour pouvoir démarrer. Plutôt que d’utiliser un schéma d’ordre inférieur pour l’initialisation (ce qui dégraderait l’ordre de précision global), nous utiliserons la solution exacte.
Comme d’habitude, on notera \(\varphi_j = \varphi(t_j, u_j)\).
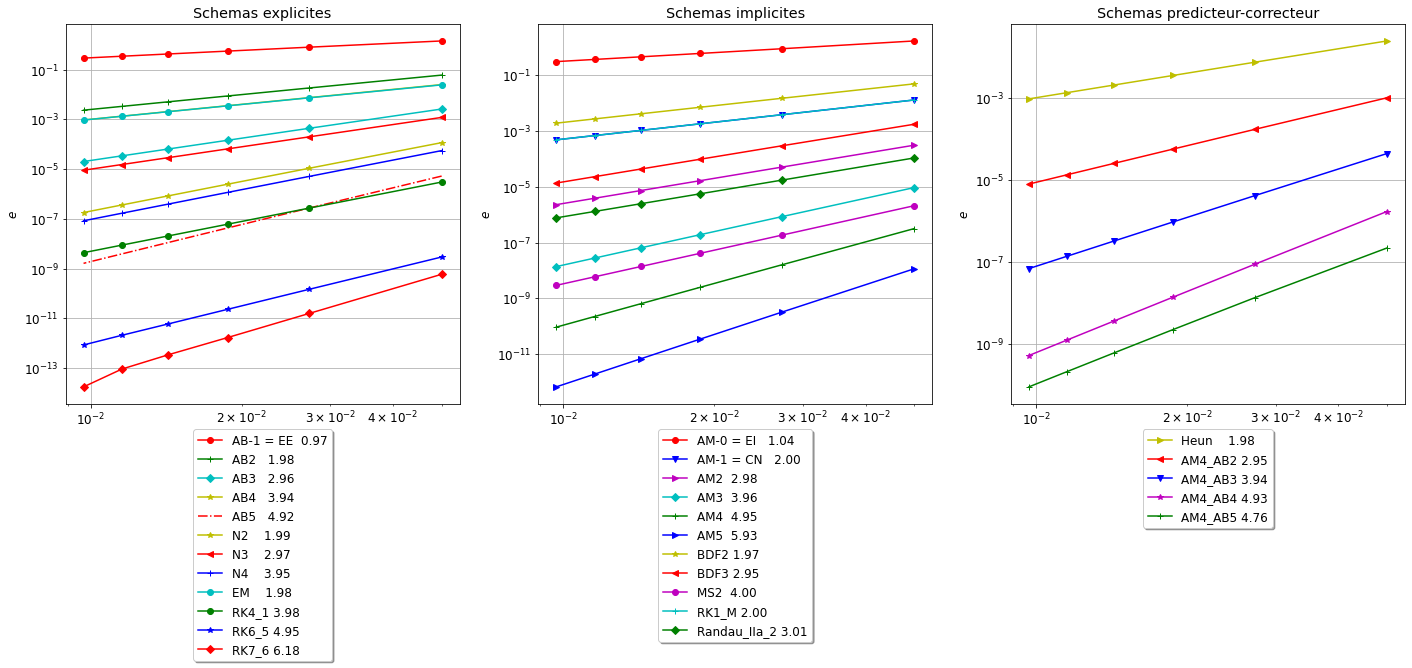
Rappels de la démarche pour le calcul de l’orde de convergence.
On écrit les schémas numériques :
les nœuds d’intégration \([t_0,t_1,\dots,t_{N}]\) sont contenus dans le vecteur tt (qui change en fonction de h)
les valeurs \([u_0,u_1,\dots,u_{N}]\) pour chaque méthode sont contenues dans le vecteur uu.
Pour chaque schéma, on calcule la solution approchée avec différentes valeurs de \(h_k=1/N_k\). On sauvegarde les valeurs de \(h_k\) dans le vecteur H.
Pour chaque valeur de \(h_k\), on calcule le maximum de la valeur absolue de l’erreur et on sauvegarde toutes ces erreurs dans le vecteur err_schema de sort que err_schema[k] contient \(e_k=\max_{i=0,\dots,N_k}|y(t_i)-u_{i}|\).
Pour afficher l’ordre de convergence on utilise une échelle logarithmique, i.e. on représente \(\ln(h)\) sur l’axe des abscisses et \(\ln(\text{err})\) sur l’axe des ordonnées.
En effet, si \(\text{err}=Ch^p\) alors \(\ln(\text{err})=\ln(C)+p\ln(h)\).
En échelle logarithmique, \(p\) représente donc la pente de la ligne droite \(\ln(\text{err})\).
2 Schémas explicites
2.1 Schéma de Adam-Bashforth à 1 pas = schéma d’Euler progressif
Le schéma de Heun est à la fois un schéma prédicteur-correcteur et un schéma de Runge-Kutta.
Comme predictor-corrector, il utilise le schéma d’Euler explicite pour prédire la valeur de \(u_{n+1}\) et le schéma de Crank-Nicolson pour corriger cette valeur.
Comme schéma de Runge-Kutta, il s’écrit comme \(
\begin{cases}
u_0 = y_0,\\
k_1 = \varphi_n ,\\
k_2 = \varphi(t_{n+1},u_n+hk_1)\\
u_{n+1}=u_n+\frac{h}{2}\Bigl(k_1+k_2\Bigr)& n=0,1,2,\dots N-1
\end{cases}
\) dont la matrice de Buthcher est \(
\begin{array}{c|cc}
0 & 0 & 0\\
1 & 1 & 0\\
\hline
& \frac{1}{2} & \frac{1}{2}
\end{array}
\)
On initialise le problème de Cauchy, on définit l’équation différentielle (phi est une fonction python qui contient la fonction mathématique \(\varphi(t, y)\) dépendant des variables \(t\) et \(y\)) et enfin on définit la solution exacte:
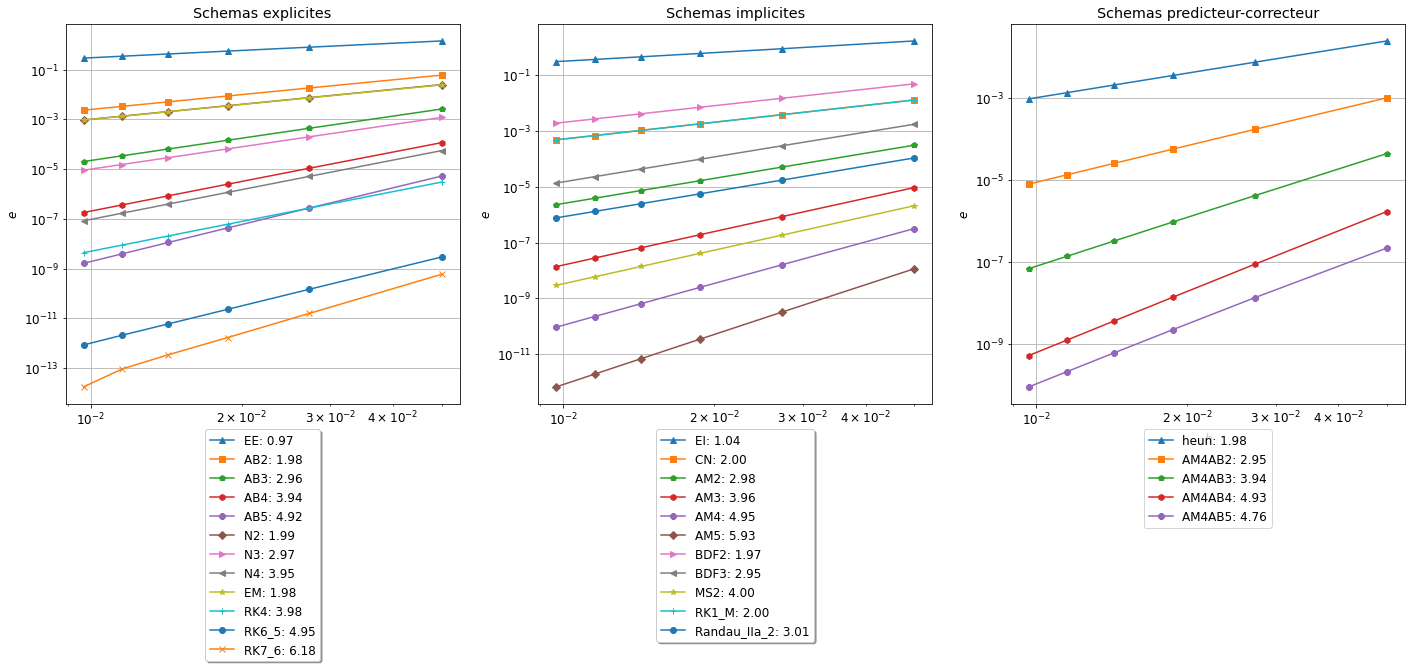
Pour chaque schéma, on calcule la solution approchée avec différentes valeurs de \(h_k=1/N_k\); on sauvegarde les valeurs de \(h_k\) dans le vecteur H.
Pour chaque valeur de \(h_k\), on calcule le maximum de la valeur absolue de l’erreur et on sauvegarde toutes ces erreurs dans le vecteur err_schema de sort que err_schema[k] contient \(e_k=\max_{i=0,...,N_k}|y(t_i)-u_{i}|\).
Nous pouvons utiliser deux méthodes différentes pour stocker ces informations.
5.1 Méthode 1
La première méthode est celle utilisée lors des deux premiers TP: on crée autant de listes que de solutions approchées.
Pour estimer l’ordre de convergence on estime la pente de la droite qui relie l’erreur au pas \(k\) à l’erreur au pas \(k+1\) en echelle logarithmique en utilisant la fonction polyfit basée sur la régression linéaire.
Pour afficher l’ordre de convergence on utilise une échelle logarithmique : on représente \(\ln(h)\) sur l’axe des abscisses et \(\ln(\text{err})\) sur l’axe des ordonnées. Le but de cette représentation est clair: si \(\text{err}=Ch^p\) alors \(\ln(\text{err})=\ln(C)+p\ln(h)\). En échelle logarithmique, \(p\) représente donc la pente de la ligne droite \(\ln(\text{err})\).
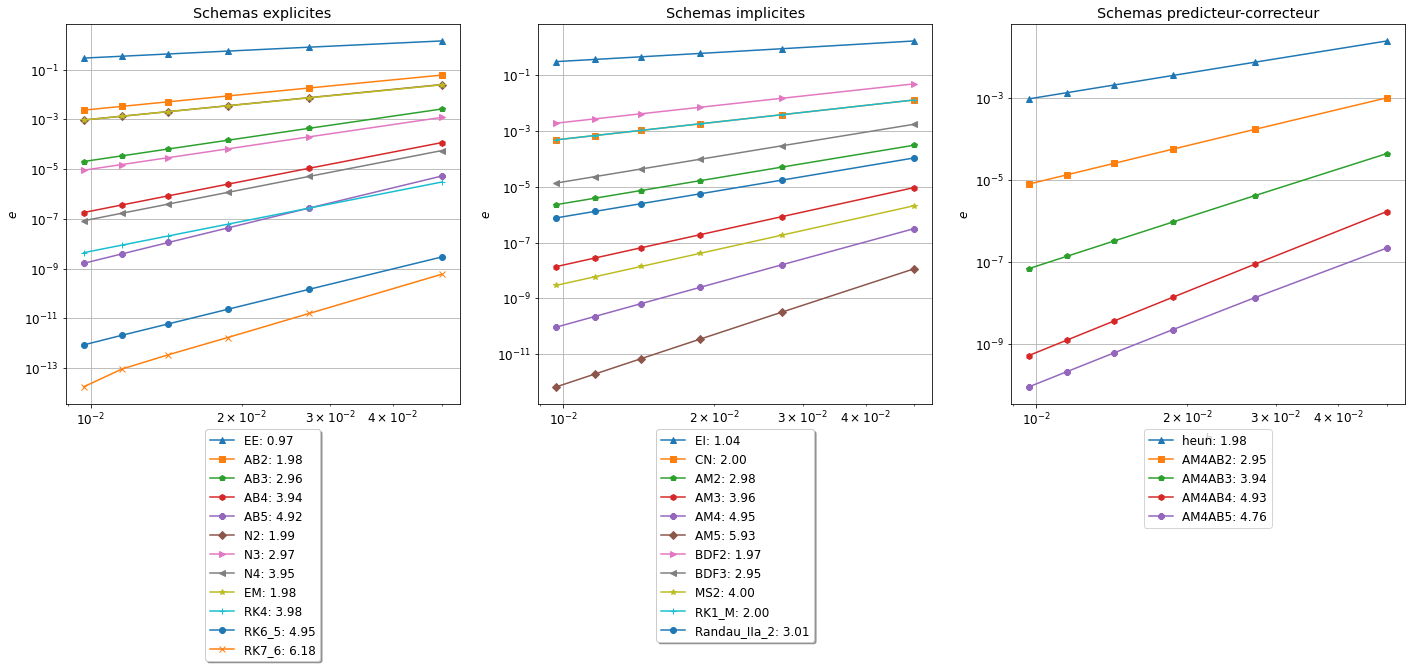
\(\omega_{[C]}\) l’ordre du corrector (schéma implicite)
\(\omega_{[P]}\) l’ordre du predictor (schéma explicite)
alors l’ordre du schéma predictor-corrector est \(\omega_{[PC]}=\min\{\omega_{[C]},\omega_{[P]}+1\}\)
Pour les schémas AM4-ABx, le schéma corrector est d’ordre \(p=5\), pour ne pas perdre en ordre convergence il faut choisir un schéma predictor d’ordre \(p-1\) (ici AB4).
5.2 Méthode 2 : version compacte
De manière compacte en utilisant une liste des noms des schémas et des dictionnaires: