Code
import numpy as np
import matplotlib.pyplot as plt
import sympy as sp
from scipy.optimize import fsolve
from IPython.display import display, Math, Markdown

Comme nous l’avons vu au chapitre précédent, les barrières sur l’ordre de convergence des méthodes multi-pas linéaires sont de plus en plus sévères. Nous allons alors étudier une autre famille de méthodes, à savoir les méthodes de Runge-Kutta. La stratégie est nouvelle par rapport à celle des méthodes multi-pas : en effet, on construit des méthodes à un seul pas, mais nous passons à une stratégie multi-étages s’appuyant sur l’information en quelques points supplémentaires, situés à l’intérieur de chaque sous-intervalle de la discrétisation du domaine.
import numpy as np
import matplotlib.pyplot as plt
import sympy as sp
from scipy.optimize import fsolve
from IPython.display import display, Math, MarkdownLes schémas de Runge-Kutta sont des méthodes à un pas permettant d’approcher l’intégrale
\(
\int_{t_n}^{t_{n+1}} \varphi(t,y(t))\mathrm{d}t
\)
par une formule de quadrature en des points situés à l’intérieur de l’intervalle \([t_n,t_{n+1}]\) :
\(
t_{n,i} \stackrel{\text{déf}}{=} t_n + c_i h, \quad \text{avec } c_i \in [0,1],
\) \(
\int_{t_n}^{t_{n+1}} \varphi(t,y(t))\mathrm{d}t
\approx
h\sum_{i=1}^{s}b_i\varphi(t_{n,i},y(t_{n,i})).
\) Cependant, si \(c_i\neq0\) et \(c_i\neq1\), alors \(t_{n,i}\) ne correspond pas à un point de discrétisation, ce qui signifie que \(y(t_{n,i})\) est inconnu.
Pour contourner ce problème, l’évaluation de \(\varphi(t_{n,i},y(t_{n,i}))\) en ces points intermédiaires est approchée à l’aide d’une autre formule de quadrature :
\(
y(t_{n,i})
\approx
y_n+h\sum_{j=1}^{s}a_{ij}\varphi(t_{n,j},y(t_{n,j})).
\) On en déduit alors l’approximation suivante :
\(
y_{n+1}
\approx
y_n
+
h
\sum_{i=1}^{s}b_i\varphi\left(t_{n,i},y_n+h\sum_{j=1}^{s}a_{ij}\varphi(t_{n,j},y_{n,j})\right).
\)
Remarque 1 : si \(c_s=1\) et \(a_{sj}=b_j\) pour tout \(j=1,\dots,s\), alors \(K_s=\varphi(t_{n+1},u_{n+1})\).
Remarque 2 : on verra des exemples où \(c_i<0\).
Une méthode de Runge-Kutta à \(s\ge1\) étages contient \(s^2+2s\) paramètres et s’écrit: \(\begin{cases} u_0=y(t_0)=y_0,\\ K_i=\displaystyle\varphi\left( t_n+hc_i,u_n+h\sum_{j=1}^{s}a_{ij}K_j \right), & i=1,\dots s\\ u_{n+1}=u_{n}+h \displaystyle\sum_{i=1}^sb_iK_i& \end{cases}\qquad n=0,1,\dots N-1.\)
NB C’est un schéma à un pas, car \(u_{n+1}\) ne dépend que de \(u_n\) et pas de \(u_{n-1},u_{n-2},\dots\)
.jpeg)
Les coefficients sont généralement organisés en deux vecteurs \(\mathbf{b}=(b_1,\dots,b_s)^T\), \(\mathbf{c}=(c_1,\dots,c_s)^T\) et une matrice \(\mathbb{A}=(a_{ij})_{1\le i,j\le s}\).
Le tableau
\( \begin{array}{c|c} \mathbf{c} & \mathbb{A}\\ \hline &\mathbf{b}^T \end{array} \)
est appelé matrice de Butcher de la méthode de Runge-Kutta considérée.
Méthode explicite. Si \(a_{ij}=0\) pour \(j\ge i\) (i.e. la matrice \(\mathbb{A}\) est triangulaire inférieure stricte), alors chaque \(K_i\) peut être calculé explicitement en fonction des \(i-1\) coefficients \(K_1,\dots,K_{i-1}\) déjà connus.
Méthode semi-implicite (ou diagonalement implicite, DIRK). Si \(a_{ij}=0\) pour \(j> i\) (i.e. la matrice \(\mathbb{A}\) est triangulaire inférieure), alors chaque \(K_i\) est solution de l’équation non linéaire
\(
\boxed{K_i}=\varphi\left(t_n+c_ih, u_n+ha_{ii}\boxed{K_i}+h\sum_{j=1}^{i-1}a_{ij}K_j\right)
\)
Un schéma semi-implicite implique donc la résolution de \(s\) équations non linéaires indépendantes.
Si, de plus, tous les termes diagonaux sont égaux (\(a_{ii}=\gamma\) pour \(i=1,\dots,s\)), on parle de singly diagonal implicit method (SDIRK).
Méthode implicite. Dans tous les autres cas, la méthode est implicite, ce qui signifie qu’il faut résoudre un système non linéaire de dimension \(s\) pour obtenir les \(K_i\).
Bien noter que la méthode est implicite non pas parce que \(u_{n+1}\) dépend de lui-même, mais parce qu’au moins un \(K_i\) dépend de lui-même.
L’augmentation du coût de calcul pour les schémas implicites peut rendre leur utilisation onéreuse. Un compromis souvent adopté consiste à utiliser des méthodes semi-implicites.
L’étude de l’ordre des méthodes de Runge-Kutta utilise la théorie de Butcher. Elle repose sur des outils qui combinent l’analyse numérique, la théorie des graphes et la différenciation des champs vectoriels. Plus tard, des relations avec la théorie des groupes et la théorie quantique des champs ont été découvertes. Une monographie de référence sur la théorie de l’ordre de Butcher et les problèmes connexes est rédigée par John C. Butcher lui-même :
Butcher, J. C. (2016). Numerical methods for ordinary differential equations. John Wiley & Sons.
L’outil de base qui relie tous les domaines susmentionnés est la notion d’arbres racinés. Nous n’énoncerons ici que les résultats.
Soit \(\omega\) l’ordre de la méthode (la méthode est dite consistante si \(\omega\ge1\)).
Théorème de Lax-Richtmyer (consistance + zéro-stabilité \(\iff\) convergence)
Le schéma est convergent (d’ordre \(\omega\ge1\)) ssi il est zéro-stable et consistante (d’ordre \(\omega\)).
Proposition (Zéro-stabilité)
Les méthodes de Runge-Kutta sont zéro-stables.
Proposition (Consistance)
La méthode de Runge-Kutta est consistante (i.e. \(\omega\ge1\)) ssi
\(
\begin{cases}
\displaystyle\sum_{j=1}^s b_{j}=1&
\\
\displaystyle c_i=\sum_{j=1}^s a_{ij}, & i=1,\dots,s
\end{cases}
\)
Remarque 1 : une méthode à \(s\) étages consistante a alors \(s^2+2s-(s+1)=s^2+s-1\) degrés de liberté.
Remarque 2 : une méthode explicite consistante vérifie
Interprétation : un bon schéma doit au moins être exact pour les équations très simples. Imposons donc à ce que le schéma reproduise correctement l’EDO la plus simple, \(y'(t)=1\), dont la solution est \(y(t)=t+C\). Comme \(\varphi(t,y)=1\), alors pour tout \(i=1,\dots,s\), on a \(K_i=1\). Le schéma devient alors \( u_{n+1}=u_n+h\sum_{i=1}^s b_i. \) Or la solution exacte vérifie \(y(t_{n+1})=y(t_n)+h\). Pour que le schéma coïncide avec cette évolution pour tout \(h\), il faut nécessairement \( \sum_{i=1}^s b_i=1. \) Par ailleurs, \( K_i = \varphi\left(t_n + hc_i, \text{approx de } y(t_n + hc_i)\right), \) autrement dit \( u_n+h\sum_{j=1}^s a_{ij}K_j \approx y(t_n + hc_i). \) Comme \(K_i=1\) et \(y(t_n+hc_i)=y(t_n)+hc_i\), la cohérence au premier ordre impose \( c_i=\sum_{j=1}^s a_{ij},\quad i=1,\dots,s. \)
Preuve. On notera \(y_n = y(t_n)\) la solution exacte au temps \(t_n\), \(\varphi_n = \varphi(t_n, y(t_n))\) et \(y'_n = y'(t_n)\) pour alléger l’écriture.
On note \(K_i^*\) les valeurs de stages obtenues en remplaçant \(u_n\) par \(y_n\) dans les équations de stage, c’est-à-dire les solutions de \( K_i^* = \varphi\left(t_n + hc_i, y_n + h\sum_{j=1}^s a_{ij} K_j^*\right), \quad i=1,\dots,s, \) et on pose \( u_{n+1}^* = y_n + h\sum_{i=1}^s b_i K_i^*. \)
Développement de Taylor des stages. Lorsque \(h \to 0\), le deuxième argument de \(\varphi\) dans la définition de \(K_i^*\) tend vers \(y_n\). Par continuité de \(\varphi\) et par le théorème du point fixe de Banach, les \(K_i^*\) convergent tous vers \(\varphi(t_n, y_n) = \varphi_n\). On peut donc écrire \( K_i^* = \varphi_n + O(h), \quad i=1,\dots,s. \) En substituant \(K_j^* = \varphi_n + O(h)\) dans l’argument interne de \(\varphi\), on obtient plus précisément \( y_n + h\sum_{j=1}^s a_{ij} K_j^* = y_n + h\!\left(\sum_{j=1}^s a_{ij}\right)\varphi_n + O(h^2). \) D’autre part, par développement de Taylor, \( y(t_n + hc_i) = y_n + h c_i \varphi_n + O(h^2). \)
Substitution dans \(u_{n+1}^*\). On utilise \(K_i^* = \varphi_n + O(h)\) : \( \sum_{i=1}^s b_i K_i^* = \left(\sum_{i=1}^s b_i\right) \varphi_n + O(h), \) d’où \( u_{n+1}^* = y_n + h\left(\sum_{i=1}^s b_i\right) \varphi_n + O(h^2). \) Par développement de Taylor, on a par ailleurs \( y_{n+1} = y_n + h \varphi_n + O(h^2). \)
Erreur de troncature locale. En substituant les expressions obtenues : \( \begin{aligned} \tau_{n+1}(h) = \frac{y_{n+1} - u_{n+1}^*}{h} &= \frac{\left(y_n + h \varphi_n + O(h^2)\right) - \left(y_n + h\left(\displaystyle\sum_{i=1}^s b_i\right)\varphi_n + O(h^2)\right)}{h}\\(6pt] &= \left(1 - \sum_{i=1}^s b_i\right)\varphi_n + O(h). \end{aligned} \) On a \(\tau_{n+1}(h) = O(h)\) pour tout \(n\) et toute EDO si et seulement si le coefficient de \(\varphi_n\) s’annule, ce qui donne la première condition de consistance : \( \sum_{i=1}^s b_i = 1. \)
Cohérence interne des stages. Pour que le schéma soit consistant, il faut de plus que le deuxième argument de \(\varphi\) dans \(K_i^*\) soit une approximation consistante de \(y(t_n + hc_i)\) à l’ordre \(O(h)\). En comparant terme à terme les deux développements de Taylor en \(h\) : \( y_n + h\!\left(\sum_{j=1}^s a_{ij}\right)\varphi_n + O(h^2) \quad \text{et} \quad y(t_n + hc_i) = y_n + h c_i \varphi_n + O(h^2), \) on identifie les termes en \(h\varphi_n\) (valable pour tout \(\varphi_n\) et tout \(i\)), ce qui donne la deuxième condition de consistance : \( c_i = \sum_{j=1}^s a_{ij}, \quad i=1,\dots,s. \)
On conclut que le schéma de Runge–Kutta implicite à \(s\) étages est consistant (d’ordre au moins 1) si et seulement si \( \sum_{i=1}^s b_i = 1 \qquad \text{et} \qquad c_i = \sum_{j=1}^s a_{ij},\quad i=1,\dots,s. \)
Proposition (Ordre de consistance)
Une méthode de Runge-Kutta est consistante d’ordre \(\omega\ge1\) si elle satisfait les conditions suivantes :
| Ordre minimum | Conditions à satisfaire |
|---|---|
| \(\omega \geq 1\) | \(\begin{cases} \displaystyle 1 = \sum_{j=1}^s b_j \\ \displaystyle c_i = \sum_{j=1}^s a_{ij}, \quad i=1,\dots,s \end{cases}\) |
| \(\omega \geq 2\) | Les conditions pour \(\omega \geq 1\) et \(\displaystyle\sum_{j=1}^s b_j c_j = \frac{1}{2}\) |
| \(\omega \geq 3\) | Les conditions pour \(\omega \geq 2\) et \(\begin{cases} \displaystyle\sum_{j=1}^s b_j c_j^2 = \frac{1}{3} \\ \displaystyle\sum_{i=1}^s\sum_{j=1}^s b_i a_{ij} c_j = \frac{1}{6} \end{cases}\) |
| \(\omega \geq 4\) | Les conditions pour \(\omega \geq 3\) et \(\begin{cases} \displaystyle\sum_{j=1}^s b_j c_j^3 = \frac{1}{4} \\ \displaystyle\sum_{i=1}^s\sum_{j=1}^s b_i c_i a_{ij} c_j = \frac{1}{8} \\ \displaystyle\sum_{i=1}^s\sum_{j=1}^s b_i a_{ij} c_j^2 = \frac{1}{12} \\ \displaystyle\sum_{i=1}^s\sum_{j=1}^s\sum_{k=1}^s b_i a_{ij}a_{jk} c_k = \frac{1}{24} \end{cases}\) |
| \(\omega \geq 5\) | Les conditions pour \(\omega \geq 4\) et \(\begin{cases} \displaystyle\sum_{j=1}^s b_j c_j^4 = \frac{1}{5} \\ \displaystyle\sum_{i,j=1}^s b_i c_i^2 a_{ij} c_j = \frac{1}{10} \\ \displaystyle\sum_{i=1}^s b_i \!\left(\sum_{j=1}^s a_{ij} c_j\right)^{2} = \frac{1}{20} \\ \displaystyle\sum_{i,j=1}^s b_i a_{ij} c_j^3 = \frac{1}{20} \\ \displaystyle\sum_{i,j=1}^s b_i c_i a_{ij} c_j^2 = \frac{1}{15} \\ \displaystyle\sum_{i,j,k=1}^s b_i c_i a_{ij}a_{jk} c_k = \frac{1}{30} \\ \displaystyle\sum_{i,j,k=1}^s b_i a_{ij} c_j a_{jk} c_k = \frac{1}{40} \\ \displaystyle\sum_{i,j,k=1}^s b_i a_{ij}a_{jk} c_k^2 = \frac{1}{60} \\ \displaystyle\sum_{i,j,k,\ell=1}^s b_i a_{ij}a_{jk}a_{k\ell} c_\ell = \frac{1}{120}\end{cases}\) |
Barrière de Butcher
L’ordre \(\omega \geq 1\) d’une méthode de Runge-Kutta à \(s \geq 1\) étapes convergente satisfait les inégalités suivantes :
\( \omega \leq \begin{cases} 2s, & \text{si la méthode est implicite}, \\ s, & \text{si la méthode est explicite et } s < 5, \\ s - 1, & \text{si la méthode est explicite et } s \geq 5. \end{cases} \)
Exemples de méthodes
On verra plus bas que les méthodes classiques sont des exemples de méthodes de Runge-Kutta. On peut alors vérifier que les ordres de convergence de ces méthodes respectent les barrières de Butcher.
| Schéma | Type de méthode RK | Nombre d’étages \(s\) | Ordre \(\omega\) | Remarque |
|---|---|---|---|---|
| Schéma d’Euler explicite | Explicite | 1 | 1 | \(s<5\) et \(\omega = s\) |
| Schéma d’Euler implicite | Implicite | 1 | 1 | \(\omega < 2s\) donc sub-optimale |
| Schéma d’Euler modifié | Explicite | 2 | 2 | \(s<5\) et \(\omega = s\) |
| Schéma de Heun | Explicite | 2 | 2 | \(s<5\) et \(\omega = s\) |
| Schéma de Crank-Nicholson | Implicite | 2 | 2 | \(\omega < 2s\) donc sub-optimale |
Les résultats ci-dessus permettent de comprendre la relation entre \(s\) le nombre d’étages d’une méthode de Runge-Kutta et son ordre de convergence \(\omega\).
Méthode implicite : l’ordre maximal est \(2s\), ce qui permet d’obtenir un meilleur ordre de convergence avec moins d’étages, mais au coût d’une complexité supplémentaire (résolution d’un système non-linéaire).
Méthode explicite : si \(s< 5\), l’ordre maximal est \(s\); si \(s\geq 5\), l’ordre est limité à \(s-1\) (strictement inférieur au nombre d’étages donc). Autrement dit, un schéma RK explicite à \(s\) étages est au mieux d’ordre \(s\), mais cela seulement si \(s < 5\). Si \(s\ge5\), alors il sera au mieux d’ordre \(s-1\), mais ce n’est même pas garanti. En effet, les travaux de Butcher démontrent que pour des méthodes d’ordre 7 et 8, un minimum de 9 et 11 étages, respectivement, est requis. En général, le nombre minimum précis d’étages pour qu’une méthode explicite de Runge-Kutta ait l’ordre \(\omega\) reste un problème ouvert. Certaines valeurs sont connues :
\( \begin{array}{c|cccccccc} \omega & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 \\ \hline s \text{ minimal} & 1 & 2 & 3 & 4 & 6 & 7 & 9 & 11\\ \end{array} \)
Remarque (le cas des systèmes) Une méthode de Runge-Kutta peut être aisément étendue aux systèmes d’équations différentielles ordinaires. Néanmoins, l’ordre d’une méthode RK dans le cas scalaire ne coı̈ncide pas nécessairement avec celui de la méthode analogue dans le cas vectoriel. En particulier, pour \(p \ge 4\), une méthode d’ordre \(p\) dans le cas du système autonome \(\mathbf{y}'(t)=\boldsymbol{\varphi}(t,\mathbf{y})\), avec \(\boldsymbol{\varphi}\colon \mathbb{R}^m\to\mathbb{R}^n\) est encore d’ordre \(p\) quand on l’applique à l’équation scalaire autonome \(\mathbf{y}'(t)=\boldsymbol{\varphi}(\mathbf{y})\), mais la réciproque n’est pas vraie.
La fonction ordre_RK sert à analyser l’ordre de consistance d’une méthode de Runge-Kutta donnée. Elle prend en entrée :
s : le nombre d’étages de la méthode Runge-Kutta (RK),type : le type de la méthode RK, soit “explicite”, soit “implicite” (optionnel)A, b, c (optionnels) : les coefficients de la matrice de Butcher. Si ces coefficients ne sont pas fournis, ils sont remplacés par des variables symboliquesordre_max (optionnel) : l’ordre maximum à vérifier. Par défaut, il est égal à \(s\) pour les méthodes explicites et à \(2s\) pour les méthodes implicites.La fonction affiche successivement : la matrice de Butcher, qui résume les coefficients de la méthode RK, et les conditions nécessaires pour que la méthode soit d’un certain ordre (de 1 à 4).
ordre_RK(s=2, type="explicite", ordre_max = 3)A = sp.Matrix([[0, 0], [sp.Rational(1, 2), 0]])
b = sp.Matrix([sp.Rational(1, 2), sp.Rational(1, 2)])
c = sp.Matrix([0, 1])
s = len(c)
ordre_RK(s, A, b, c, ordre_max=3)# =============================================================================
# Fonctions pour calculer les conditions de consistance pour un schéma RK.
#
# La fonction ordre_RK calcule les conditions pour les ordres 1, 2, 3 et 4 (même si théoriquement cela n'est pas possible)
# - affiche la matrice de Butcher
# - affiche les conditions de consistance obtenues pour chaque ordre par la fonction ordre_i
# - renvoie une liste d'équations pour une éventuelle résolution
#
# Chaque fonction ordre_i calcule les conditions pour être d'ordre i
# - peut afficher les conditions de consistance [actuellement en commentaire]
# - renvoie la liste d'équations
#+++
# =============================================================================
# =============================================================================
# Calcul des conditions de consistance pour un schéma RK
# On doit indiquer
# le nombre d'étages s
# le type de schéma parmi implicite, semi-implicite ou explicite
# éventuellement les coefficients A, b et c
# =============================================================================
def ordre_RK(s, type="implicite", A=None, b=None, c=None, ordre_max = None):
j = sp.symbols('j')
if ordre_max is None :
if type == "explicite" and s<5: ordre_max = s
else : ordre_max = 2*s
if c is None: c = sp.symbols(f'c_0:{s}')
if b is None: b = sp.symbols(f'b_0:{s}')
if A is None:
if type == "implicite": A = sp.MatrixSymbol('a', s, s)
elif type=="semi-implicite": A = sp.Matrix(s, s, lambda i,j: sp.Symbol('a{}{}'.format(i, j)) if i >= j else 0)
elif type=="explicite": A = sp.Matrix(s, s, lambda i,j: sp.Symbol('a{}{}'.format(i, j)) if i > j else 0)
else:
A = sp.Matrix(A)
display(Markdown("**Matrice de Butcher**"))
But = matrice_Butcher(s, A, b, c)
Eqs = []
display(Markdown(f"**On a {s+1} conditions pour avoir consistance (= pour être d'ordre 1)**"))
Eq_1 = ordre_1(s, A, b, c, j)
Eqs.append(Eq_1)
display(*Eq_1)
if ordre_max >=2:
display(Markdown("**On doit ajouter 1 condition pour être d'ordre 2**"))
Eq_2 = ordre_2(s, A, b, c, j)
Eqs.append([Eq_2])
display(Eq_2)
if ordre_max >=3:
display(Markdown("**On doit ajouter 2 conditions pour être d'ordre 3**"))
Eq_3 = ordre_3(s, A, b, c, j)
Eqs.append(Eq_3)
display(*Eq_3)
if ordre_max >=4:
display(Markdown("**On doit ajouter 4 conditions pour être d'ordre 4**"))
Eq_4 = ordre_4(s, A, b, c, j)
Eqs.append(Eq_4)
display(*Eq_4)
return Eqs
def matrice_Butcher(s, A, b, c):
But = sp.Matrix(A)
But = But.col_insert(0, sp.Matrix(c))
last = [sp.Symbol(" ")]
last.extend(b)
But = But.row_insert(s,sp.Matrix(last).T)
display(Math(sp.latex(sp.Matrix(But))))
return But
def ordre_1(s, A, b, c, j):
texte = r"\sum_{j=1}^s b_j =" + f"{sum(b).simplify()}"
texte += r"\text{ doit être égale à }1"
# display(Math(texte))
Eq_1 = [sp.Eq( sum(b).simplify(), 1 )]
for i in range(s):
somma = sp.summation(A[i,j],(j,0,s-1)).simplify()
texte = r'\sum_{j=1}^s a_{'+str(i)+r'j}=' + sp.latex( somma )
texte += r"\text{ doit être égale à }"+sp.latex(c[i])
# display(Math( texte ))
Eq_1.append(sp.Eq( somma, c[i] ))
return Eq_1
def ordre_2(s, A, b, c, j):
texte = r'\sum_{j=1}^s b_j c_j=' +sp.latex(sum([b[i]*c[i] for i in range(s)]).simplify())
texte += r"\text{ doit être égale à }\frac{1}{2}"
# display(Math(texte))
Eq_2 = sp.Eq( sum([b[i]*c[i] for i in range(s)]).simplify(), sp.Rational(1,2) )
return Eq_2
def ordre_3(s, A, b, c, j):
texte = r'\sum_{j=1}^s b_j c_j^2='
texte += sp.latex( sum([b[i]*c[i]**2 for i in range(s)]).simplify() )
texte += r"\text{ doit être égale à }\frac{1}{3}"
# display(Math(texte))
Eq_3_1 = sp.Eq( sum([b[i]*c[i]**2 for i in range(s)]).simplify(), sp.Rational(1,3) )
texte = r'\sum_{i,j=1}^s b_i a_{ij} c_j='
somma = sum([b[i]*A[i,j]*c[j] for j in range(s) for i in range(s)]).simplify()
texte = texte + sp.latex(somma)
texte += r"\text{ doit être égale à }\frac{1}{6}"
# display(Math(texte))
Eq_3_2 = sp.Eq( sum([b[i]*A[i,j]*c[j] for j in range(s) for i in range(s)]).simplify(), sp.Rational(1,6) )
return [Eq_3_1, Eq_3_2]
def ordre_4(s, A, b, c, j):
texte = r'\sum_{j=1}^s b_j c_j^3='
texte += sp.latex( sum([b[i]*c[i]**3 for i in range(s)]).simplify() )
texte += r"\text{ doit être égale à }\frac{1}{4}"
# display(Math(texte))
Eq_4_1 = sp.Eq( sum([b[i]*c[i]**3 for i in range(s)]).simplify(), sp.Rational(1,4) )
texte = r'\sum_{i,j=1}^s b_i c_i a_{ij} c_j='
somma = sum([b[i]*c[i]*A[i,j]*c[j] for j in range(s) for i in range(s)]).simplify()
texte = texte + sp.latex(somma)
texte += r"\text{ doit être égale à }\frac{1}{8}"
# display(Math(texte))
Eq_4_2 = sp.Eq( sum([b[i]*c[i]*A[i,j]*c[j] for j in range(s) for i in range(s)]).simplify(), sp.Rational(1,8) )
texte = r'\sum_{i,j=1}^s b_i a_{ij} c_j^2='
somma = sum([b[i]*A[i,j]*c[j]**2 for j in range(s) for i in range(s)]).simplify()
texte = texte + sp.latex(somma)
texte += r"\text{ doit être égale à }\frac{1}{12}"
# display(Math(texte))
Eq_4_3 = sp.Eq( sum([b[i]*A[i,j]*c[j]**2 for j in range(s) for i in range(s)]).simplify(), sp.Rational(1,12) )
texte = r'\sum_{i,j,k=1}^s b_i a_{ij} a_{jk} c_k='
somma = sum([b[i]*A[i,j]*A[j,k]*c[k] for k in range(s) for j in range(s) for i in range(s)]).simplify()
texte = texte + sp.latex(somma)
texte += r"\text{ doit être égale à }\frac{1}{24}"
# display(Math(texte))
Eq_4_4 = sp.Eq( sum([b[i]*A[i,j]*A[j,k]*c[k] for k in range(s) for j in range(s) for i in range(s)]).simplify(), sp.Rational(1,24) )
return [Eq_4_1, Eq_4_2, Eq_4_3, Eq_4_4]
# Exemple sans paramètres
s = 2
type = "implicite"
display(Markdown(f"<mark>Conditions pour un schéma {type} avec s = {s} étages</mark>"))
ordre_RK( s = s, type = type );Conditions pour un schéma implicite avec s = 2 étages
Matrice de Butcher
\(\displaystyle \left[\begin{matrix}c_{0} & a_{0, 0} & a_{0, 1}\\c_{1} & a_{1, 0} & a_{1, 1}\\ & b_{0} & b_{1}\end{matrix}\right]\)
On a 3 conditions pour avoir consistance (= pour être d’ordre 1)
\(\displaystyle b_{0} + b_{1} = 1\)
\(\displaystyle a_{0, 0} + a_{0, 1} = c_{0}\)
\(\displaystyle a_{1, 0} + a_{1, 1} = c_{1}\)
On doit ajouter 1 condition pour être d’ordre 2
\(\displaystyle b_{0} c_{0} + b_{1} c_{1} = \frac{1}{2}\)
On doit ajouter 2 conditions pour être d’ordre 3
\(\displaystyle b_{0} c_{0}^{2} + b_{1} c_{1}^{2} = \frac{1}{3}\)
\(\displaystyle b_{0} c_{0} a_{0, 0} + b_{0} c_{1} a_{0, 1} + b_{1} c_{0} a_{1, 0} + b_{1} c_{1} a_{1, 1} = \frac{1}{6}\)
On doit ajouter 4 conditions pour être d’ordre 4
\(\displaystyle b_{0} c_{0}^{3} + b_{1} c_{1}^{3} = \frac{1}{4}\)
\(\displaystyle b_{0} c_{0}^{2} a_{0, 0} + b_{0} c_{0} c_{1} a_{0, 1} + b_{1} c_{0} c_{1} a_{1, 0} + b_{1} c_{1}^{2} a_{1, 1} = \frac{1}{8}\)
\(\displaystyle b_{0} c_{0}^{2} a_{0, 0} + b_{0} c_{1}^{2} a_{0, 1} + b_{1} c_{0}^{2} a_{1, 0} + b_{1} c_{1}^{2} a_{1, 1} = \frac{1}{12}\)
\(\displaystyle b_{0} c_{0} a_{0, 0}^{2} + b_{0} c_{0} a_{0, 1} a_{1, 0} + b_{0} c_{1} a_{0, 0} a_{0, 1} + b_{0} c_{1} a_{0, 1} a_{1, 1} + b_{1} c_{0} a_{0, 0} a_{1, 0} + b_{1} c_{0} a_{1, 0} a_{1, 1} + b_{1} c_{1} a_{0, 1} a_{1, 0} + b_{1} c_{1} a_{1, 1}^{2} = \frac{1}{24}\)
# Exemple : méthode à 2 étages, correspondant à Crank-Nicolson
A = [ [sp.S(0) , sp.S(0)],
[sp.Rational(1,2) , sp.Rational(1,2)]
]
b = [sp.Rational(1,2), sp.Rational(1,2)]
c = [sp.S(0), sp.S(1)]
s = len(c)
display(Markdown(f"<mark>Exemple de méthode de Runge-Kutta à {s} étages (Crank-Nicolson)</mark>"))
ordre_RK(s, A=A, b=b, c=c);
Exemple de méthode de Runge-Kutta à 2 étages (Crank-Nicolson)
Matrice de Butcher
\(\displaystyle \left[\begin{matrix}0 & 0 & 0\\1 & \frac{1}{2} & \frac{1}{2}\\ & \frac{1}{2} & \frac{1}{2}\end{matrix}\right]\)
On a 3 conditions pour avoir consistance (= pour être d’ordre 1)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 1 condition pour être d’ordre 2
\(\displaystyle \text{True}\)
On doit ajouter 2 conditions pour être d’ordre 3
\(\displaystyle \text{False}\)
\(\displaystyle \text{False}\)
On doit ajouter 4 conditions pour être d’ordre 4
\(\displaystyle \text{False}\)
\(\displaystyle \text{False}\)
\(\displaystyle \text{False}\)
\(\displaystyle \text{False}\)
Rappel : définition de A-stabilité dans \(\mathbb{C}\)
Soit \(\lambda \in \mathbb{C}\) avec \(\Re(\lambda) = -\beta\) où \(\beta \ge 0\). Considérons l’équation test \(y'(t) = \lambda y(t)\). Sa solution générale est \(y(t) = y_0 e^{\lambda t}\), ce qui implique \(\lim_{t \to +\infty} |y(t)| = 0\).
Soit \(h > 0\) le pas de temps et \(u_n \approx y(t_n)\) l’approximation numérique. On dit que le schéma est A-stable si, sous d’éventuelles conditions sur \(h\), on a \(\lim_{n \to +\infty} | u_n | = 0\).
Les méthodes de Runge-Kutta étant des méthodes à un pas, lorsqu’on les applique à l’équation test \(y'(t) = \lambda y(t)\), on obtient une relation de récurrence de la forme \(u_{n+1} = q(h\lambda) u_n\) pour une certaine fonction \(q\). Par conséquent, la condition de A-stabilité se traduit par \(|q(h\lambda)| < 1\).
Proposition (A-stabilité sur l’axe réel négatif pour un schéma RK).
Considérons l’équation test \(
y'(t)=-\beta y(t),\qquad \beta\in\mathbb{R}^+_*
\) et un schéma de Runge-Kutta à \(s\) étages, de matrice de Butcher \(\mathbb A\) et de poids \(\mathbf b\). Posons \(x=\beta h>0\) et \(\mathbf{1}_s = (1, \dots, 1)^T\) le vecteur de dimension \(s\) dont tous les éléments sont égaux à 1. Notons \(
q(x)=1-x\,\mathbf b^{T}(\mathbb I_s+x\mathbb A)^{-1}\mathbf 1_s,
\) pour tout \(x\) tel que \(\mathbb I_s+x\mathbb A\) soit inversible (i.e. \(-1/x\notin\sigma(\mathbb A)\)).
Alors la suite numérique vérifie \(u_{n+1}=q(x) u_n\) et, par conséquent, le schéma est A-stable (sous des eventuelles conditions sur \(h\)) ssi \(\left| q(x) \right| < 1\).
Preuve. La méthode de Runge-Kutta à \(s\) étages pour l’équation test s’écrit : \( \begin{cases} K_i = -\beta \left( u_n + h \sum_{j=1}^{s} a_{ij} K_j \right), & i = 1, \dots, s. \\ u_{n+1} = u_n + h \sum_{i=1}^{s} b_i K_i, \end{cases} \)
En introduisant les notations vectorielles \(\mathbf{K} = (K_1, \dots, K_s)^T\), le système se réécrit de manière compacte : \( \mathbf K=-\beta u_n\mathbf 1-\beta h\,\mathbb A\mathbf K, \qquad u_{n+1}=u_n+h\,\mathbf b^T\mathbf K. \)
En isolant \(\mathbf{K}\) dans la première équation : \( (\mathbb{I}_s + \beta h \mathbb{A}) \mathbf{K} = -\beta u_n \mathbf{1}_s \leadsto \mathbf{K} = (\mathbb{I}_s + \beta h \mathbb{A})^{-1} (-\beta u_n \mathbf{1}_s). \)
Si la matrice \(\mathbb I_s+\beta h\mathbb A\) est inversible (c’est-à-dire si \(-1/(\beta h)\) n’est pas une valeur propre de la matrice de Butcher \(\mathbb{A}\)), alors \( \mathbf K=(\mathbb I_s+\beta h\mathbb A)^{-1}(-\beta u_n\mathbf 1_s). \)
En substituant ce résultat dans l’expression de \(u_{n+1}\), nous obtenons la relation de récurrence : \( u_{n+1} = u_n-\beta h\,\mathbf b^T(\mathbb I_s+\beta h\mathbb A)^{-1}\mathbf 1_s\,u_n = u_n \underbrace{\left( 1 - \beta h \mathbf{b}^T (\mathbb{I}_s + \beta h \mathbb{A})^{-1} \mathbf{1}_s \right)}_{q(h\beta)} = q(\beta h)\,u_n. \)
Avec \(x=\beta h\), on obtient bien \(u_{n+1}=q(x)u_n\), donc par récurrence \(u_n=q^n(x) u_0\). Ainsi, \(u_n\to 0\) ssi \(q^n(x)\to 0\) ssi \(|q(x)|<1\).
def calculer_q_rk_general(s, A=None, b=None):
x = sp.symbols('x')
# beta, h = sp.symbols('beta h')
# x = beta * h
if A is None: A = sp.Matrix(s, s, lambda i, j: sp.symbols(f'a_{i+1}{j+1}'))
if b is None: b = sp.Matrix(s, 1, lambda i, j: sp.symbols(f'b_{i+1}'))
ones = sp.Matrix.ones(s, 1)
I = sp.eye(s)
mat_res = x * b.T * (I + x * A).inv() * ones
# On extrait le contenu avec [0, 0] pour obtenir un scalaire SymPy
produit_scalaire = mat_res[0, 0]
q = 1 - produit_scalaire
return sp.simplify(q)
# test de la fonction pour s = 2
q = calculer_q_rk_general(2)
display(Markdown(f"\(q(x) = {sp.latex(q)}\)"))\(q(x) = \frac{a_{11} a_{22} x^{2} + a_{11} x - a_{12} a_{21} x^{2} + a_{12} b_{1} x^{2} + a_{21} b_{2} x^{2} + a_{22} x - b_{1} x \left(a_{22} x + 1\right) - b_{2} x \left(a_{11} x + 1\right) + 1}{a_{11} a_{22} x^{2} + a_{11} x - a_{12} a_{21} x^{2} + a_{22} x + 1}\)
# test de la fonction pour s = 2 et des coefficients donnés
s = 2
A = sp.Matrix(s, s, lambda i, j: sp.symbols(f'a_{i+1}{j+1}'))
b = sp.Matrix(s, 1, lambda i, j: sp.symbols(f'b_{i+1}'))
A[0, 0] = A[0, 1] = A[1,1] = sp.S(0)
b[0] = 1-b[1]
display(Markdown(f"\(A = {sp.latex(A)},\\qquad b^T = {sp.latex(b.T)}\)"))
q = calculer_q_rk_general(s, A, b)
display(Markdown(f"\(q(x) = {sp.latex(q)}\)"))\(A = \left[\begin{matrix}0 & 0\\a_{21} & 0\end{matrix}\right],\qquad b^T = \left[\begin{matrix}1 - b_{2} & b_{2}\end{matrix}\right]\)
\(q(x) = a_{21} b_{2} x^{2} - x + 1\)
Le facteur de stabilité \(q\) est une fonction rationnelle de \(x=\beta h\) dont les coefficients dépendent de la matrice de Butcher. En particulier, \(q(0)=1\) et \(q'(0)=-1\).
Proposition (Formule de Butcher pour le facteur de stabilité)
Le facteur de stabilité \(q\) défini par \( q(x)=1-x\,\mathbf b^{T}(\mathbb{I}_s+x\mathbb A)^{-1}\mathbf{1}_s \) se réécrit aussi sous la forme \( q(x) = \frac{\det(\mathbb{I}_s+x\mathbb{A}-x\mathbf{1}_s\mathbf{b}^T)}{\det(\mathbb{I}_s+x\mathbb{A})}. \)
Autrement dit, \(q(x)\) est une fraction rationnelle.
Preuve. Le lemme du déterminant de Sylvester affirme que, pour toute matrice \(\mathbb{M}\) inversible et tous vecteurs \(\mathbf{u}\) et \(\mathbf{v}\) de \(\mathbb{R}^s\), on a \( \det(\mathbb{M} - \mathbf{u} \mathbf{v}^T) = \det(\mathbb{M}) \left( \mathbb{I}_s - \mathbf{v}^T \mathbb{M}^{-1} \mathbf{u} \right). \)
Soit \(\mathbb{M} = \mathbb{I}_s + x \mathbb{A}\), \(\mathbf{v} = x\mathbf{b}\) et \(\mathbf{u} = \mathbf{1}_s\). Alors, on trouve que \( \begin{aligned} \det(\mathbb{I}_s + x \mathbb{A} - x \mathbf{1}_s \mathbf{b}^T) &= \det(\mathbb{M} - \mathbf{u} \mathbf{v}^T) \\ &= \det(\mathbb{M}) \left( \mathbb{I}_s - \mathbf{v}^T \mathbb{M}^{-1} \mathbf{u} \right) \\ &= \det(\mathbb{I}_s + x \mathbb{A}) \left( \mathbb{I}_s - x \mathbf{b}^T (\mathbb{I}_s + x \mathbb{A})^{-1} \mathbf{1}_s \right) \\ &= \det(\mathbb{I}_s + x \mathbb{A}) q(x). \end{aligned} \)
def calculer_q_rk_general_v2(s, A=None, b=None):
x = sp.symbols('x')
# beta, h = sp.symbols('beta h')
# x = beta * h
if A is None: A = sp.Matrix(s, s, lambda i, j: sp.symbols(f'a_{i+1}{j+1}'))
if b is None: b = sp.Matrix(s, 1, lambda i, j: sp.symbols(f'b_{i+1}'))
ones = sp.Matrix.ones(s, 1)
I = sp.eye(s)
q = sp.det(I + x * A - x * ones * b.T) / sp.det(I + x * A)
return sp.simplify(q)
# test de la fonction pour s = 2
# q = calculer_q_rk_general(2)
# display(Markdown(f"\(q(x) = {sp.latex(q)}\)"))
q = calculer_q_rk_general_v2(2)
display(Markdown(f"\(q(x) = {sp.latex(q)}\)"))\(q(x) = \frac{a_{11} a_{22} x^{2} - a_{11} b_{2} x^{2} + a_{11} x - a_{12} a_{21} x^{2} + a_{12} b_{1} x^{2} + a_{21} b_{2} x^{2} - a_{22} b_{1} x^{2} + a_{22} x - b_{1} x - b_{2} x + 1}{a_{11} a_{22} x^{2} + a_{11} x - a_{12} a_{21} x^{2} + a_{22} x + 1}\)
# test de la fonction pour s = 2 et des coefficients donnés
s = 2
A = sp.Matrix(s, s, lambda i, j: sp.symbols(f'a_{i+1}{j+1}'))
b = sp.Matrix(s, 1, lambda i, j: sp.symbols(f'b_{i+1}'))
A[0, 0] = A[0, 1] = A[1,1] = sp.S(0)
b[0] = 1-b[1]
display(Markdown(f"\(A = {sp.latex(A)},\\qquad b^T = {sp.latex(b.T)}\)"))
# q = calculer_q_rk_general(s, A, b)
# display(Markdown(f"\(q(x) = {sp.latex(q)}\)"))
q = calculer_q_rk_general_v2(s, A, b)
display(Markdown(f"\(q(x) = {sp.latex(q)}\)"))\(A = \left[\begin{matrix}0 & 0\\a_{21} & 0\end{matrix}\right],\qquad b^T = \left[\begin{matrix}1 - b_{2} & b_{2}\end{matrix}\right]\)
\(q(x) = a_{21} b_{2} x^{2} - x + 1\)
Proposition (Inexistence de la A-stabilité inconditionnelle pour les schémas explicites)
Toute méthode de Runge-Kutta explicite à \(s\) étages possède un facteur de stabilité \(q(x)\) polynomial. Par conséquent, aucune de ces méthodes ne peut être inconditionnellement A-stable.
Preuve. Soit une méthode de Runge-Kutta explicite à \(s\) étages définie par sa matrice de Butcher \(\mathbb{A} \in \mathcal{M}_s(\mathbb{R})\) et son vecteur de poids \(\mathbf{b} \in \mathbb{R}^s\). On considère la variable réelle \(x = \beta h \ge 0\).
Méthode 1 : Dans un schéma explicite, \(\mathbb{A}\) est une matrice triangulaire inférieure stricte (\(a_{ij} = 0\) pour \(j \ge i\)). Une propriété fondamentale de ces matrices est qu’elles sont nilpotentes d’indice \(s\), i.e. \(\mathbb{A}^s = \mathbb{O}\), ce qui implique que les puissances de \(\mathbb{A}\) au-delà de \(s-1\) sont nulles.
Le facteur de stabilité est donné par l’expression matricielle \(q(x) = 1 - x \mathbf{b}^T (\mathbb{I}_s + x \mathbb{A})^{-1} \mathbf{1}_s\). Puisque la matrice \(x\mathbb{A}\) est nilpotente, son inverse s’exprime par une somme finie (série de Neumann tronquée) : \((\mathbb{I}_s + x\mathbb{A})^{-1} = \mathbb{I}_s - x\mathbb{A} + x^2\mathbb{A}^2 - \dots + (-x)^{s-1}\mathbb{A}^{s-1} = \sum_{k=0}^{s-1} (-x\mathbb{A})^k.\)
En substituant ce développement dans l’expression de \(q(x)\), nous obtenons : \(q(x) = 1 - x \mathbf{b}^T \left( \sum_{k=0}^{s-1} (-x \mathbb{A})^k \right) \mathbf{1}_s.\) En distribuant le produit, on identifie un polynôme en \(x\) de degré au plus \(s\) : \(q(x) = 1 + \sum_{k=1}^{s} (-x)^k (\mathbf{b}^T \mathbb{A}^{k-1} \mathbf{1}_s).\) Pour tout polynôme \(q(x)\) de degré non nul, on a \(\lim_{x \to +\infty} |q(x)| = +\infty.\) Il existe donc nécessairement une valeur critique \(x^*\) telle que pour tout \(x > x^*\), \(|q(x)| > 1\). La région de stabilité est donc bornée sur l’axe réel, ce qui exclut la A-stabilité inconditionnelle.
Méthode 2 : En utilisant la formule de Butcher pour le facteur de stabilité, on trouve que \(q(x) = \frac{\det(\mathbb{I}_s + x\mathbb{A} - x\mathbf{1}_s \mathbf{b}^T)}{\det(\mathbb{I}_s + x\mathbb{A})}.\) Puisque \(\mathbb{A}\) est une matrice triangulaire inférieure stricte, \(\det(\mathbb{I}_s + x\mathbb{A}) = 1\) pour tout \(x\). Par conséquent, \(q(x)\) est égal au déterminant du numérateur, qui est un polynôme de degré au plus \(s\) en \(x\).
Comme dans la méthode 1, cela implique que \(\lim_{x \to +\infty} |q(x)| = +\infty\), et donc que la région de stabilité est bornée sur l’axe réel, excluant ainsi la A-stabilité inconditionnelle.
Remarque. Si le schéma explicite est d’ordre maximal avec \(s<5\) (c’est-à-dire \(\omega = s\)), alors les conditions d’ordre imposent que : \(\mathbf{b}^T \mathbb{A}^{k-1} \mathbf{1}_s = \frac{1}{k!}, \quad \text{pour } k=1,\dots,s.\)
Le facteur de stabilité \(q(x)\) s’écrit alors comme le polynôme de Taylor de l’exponentielle : \(q(x) = 1 + \sum_{k=1}^{s} \frac{(-x)^k}{k!} = \sum_{k=0}^{s} \frac{(-x)^k}{k!}.\)
On retrouve bien que pour \(s \to \infty\), \(q(x)\) converge vers \(e^{-x}\) pour tout \(x\). réel.
# Polynômes de A-stabilité pour s = 1 à 4 (supposés d'ordre maximal omega=s)
# q(x) = \sum_{k=0}^s \frac{(-x)^k}{k!}
s_max = 4
# 1. Pré-calcul des factorielles
# On stocke 1/k! pour transformer la division en multiplication (plus rapide)
from math import factorial
inv_fact = [1 / factorial(k) for k in range(s_max+1)]
# 2. Fonction optimisée utilisant les coefficients pré-calculés
def q_omega_max_opti(x, s):
# On calcule la somme : 1 - x/1! + x^2/2! - x^3/3! ...
# polyval de numpy est aussi une option, mais une compréhension de liste suffit ici
return sum([inv_fact[k] * (-x)**k for k in range(s+1)])
plt.figure(figsize=(10, 4))
xx = np.linspace(0, 4, 500)
linestyles = ['-', '--', '-.', ':']
# Tracé des courbes avec changement de style et de couleur
for s in range(1, s_max+1):
plt.plot(xx, q_omega_max_opti(xx, s),
label=f'$s = \\omega = {s}$',
linestyle=linestyles[(s-1)%len(linestyles)],
linewidth=2)
# Tracé des limites de stabilité (|q(x)| = 1)
plt.axhline(y=1, color='black', linestyle='-', alpha=0.5)
plt.axhline(y=-1, color='black', linestyle='-', alpha=0.5)
plt.fill_between(xx, -1, 1, color='gray', alpha=0.1, label='Zone de A-Stabilité')
# Configuration des axes
plt.title("Polynômes de A-Stabilité des RK Explicites d'ordre maximal")
plt.xlabel(r'$x = \beta h$')
plt.ylabel(r'$q(x)$')
plt.ylim(-2, 2) # On zoome sur la zone intéressante [-1, 1]
plt.xlim(xx.min(), xx.max())
plt.grid(True, which='both', linestyle='--', linewidth=0.5)
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left');
plt.tight_layout()
plt.show()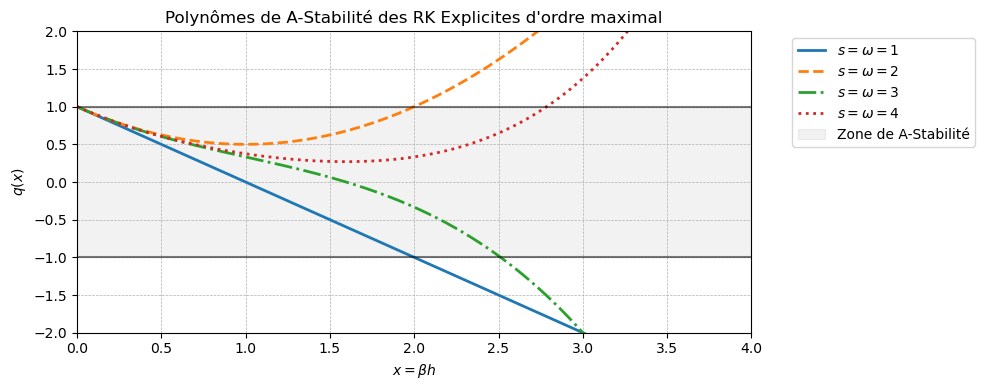
On constate que, contrairement aux méthodes multi-pas, la taille des régions de stabilité absolue des méthodes RK augmente quand l’ordre augmente.
Étudier les méthodes RK avec \(s=1\) consistants :
Un schéma de Runge-Kutta à un étage est défini par les coefficients \(a_{11}\), \(b_1\) et \(c_1\). En ajoutant les conditions de consistance, on trouve que \(c_1=a_{11}\) et \(b_1=1\).
Ces méthodes ont pour matrice de Butcher \( \begin{array}{c|cc} c_1 & a_{11}\\ \hline & b_1 \end{array} \text{ avec } \begin{cases} c_1=a_{11}\\ b_1=1 \end{cases} \quad \leadsto \boxed{ \begin{array}{c|cc} c_1 & c_1\\ \hline & 1 \end{array} \quad \leadsto \begin{cases} u_0 = y_0 \\ K_1 = \varphi\left(t_n+hc_1,u_n+h c_{1}K_1\right)\\ u_{n+1} = u_n + h K_1 & n=0,1,\dots N-1 \end{cases} } \)
⚙️ Exemple
Si on choisit \(c_1=1\) on trouve le schéma implicite \(
\begin{array}{c|cc}
1 & 1\\
\hline
& 1
\end{array}
\quad
\implies
\begin{cases}
u_0 = y_0 \\
K_1 = \varphi\left(t_{n+1},u_n+h K_1\right)\\
u_{n+1} = u_n + h K_1 & n=0,1,\dots N-1
\end{cases}
\) Ce schéma n’est rien d’autre que le schéma d’Euler implicite. En effet, \(
K_1
= \varphi\left(t_{n+1},u_n+h K_1\right)
= \varphi\left(t_{n+1},u_{n+1}\right)
\quad\leadsto\quad
u_{n+1} = u_n + h K_1=u_n + h \varphi\left(t_{n+1},u_{n+1}\right)
\)
Plus généralement, si \(c_s=1\) et \(a_{sj}=b_j\) pour tout \(j=1,\dots,s\) alors \(K_s=\varphi(t_{n+1},u_{n+1})\).
Selon le théorème de Butcher :
Les conditions sont les suivantes :
ordre_RK(s=1);Matrice de Butcher
\(\displaystyle \left[\begin{matrix}c_{0} & a_{0, 0}\\ & b_{0}\end{matrix}\right]\)
On a 2 conditions pour avoir consistance (= pour être d’ordre 1)
\(\displaystyle b_{0} = 1\)
\(\displaystyle a_{0, 0} = c_{0}\)
On doit ajouter 1 condition pour être d’ordre 2
\(\displaystyle b_{0} c_{0} = \frac{1}{2}\)
Pour que la méthode soit d’ordre \(2\) il faut que \(1\times c_1=\frac{1}{2}\) : il existe une seule méthode d’ordre 2, elle est implicite et sa matrice de Butcher est
\( \begin{array}{c|cc} \frac{1}{2} & \frac{1}{2}\\ \hline & 1 \end{array} \quad \implies \begin{cases} u_0 = y_0 \\ K_1 = \varphi\left(t_n+\frac{h}{2},u_n+\frac{h}{2}K_1\right)\\ u_{n+1} = u_n + h K_1 & n=0,1,\dots N-1 \end{cases} \)
Notons que \(u_{n+1} = u_n+h K_1\), donc \(hK_1=u_{n+1}-u_n\). Si on remplace le \(hK_1\) dans la définition de \(K_1\) ou trouve \(K_1 = \varphi\left(t_n+\frac{h}{2},u_n+\frac{h}{2}K_1\right)=\varphi\left(t_n+\frac{h}{2},u_n+\frac{h}{2}u_{n+1}-\frac{h}{2}u_n\right)=\varphi\left(t_n+\frac{h}{2},h\frac{(u_{n+1}+u_n)}{2}\right)\): on obtient le schéma RK1_M
\(
K_1
= \varphi\left(t_{n}+\frac{h}{2},\frac{u_n+u_{n+1}}{2}\right)
\quad\implies\quad
u_{n+1} = u_n + h K_1=u_n + h \varphi\left(\frac{t_n+t_{n+1}}{2},\frac{u_n+u_{n+1}}{2}\right)
\)
Il existe un seul schéma explicite RK à un étage obtenu avec \(c_1=0\) : \( \begin{array}{c|cc} 0 & 0\\ \hline & 1 \end{array} \quad \implies \begin{cases} u_0 = y_0 \\ K_1 = \varphi\left(t_{n},u_n\right)\\ u_{n+1} = u_n + h K_1 & n=0,1,\dots N-1 \end{cases} \) Ce schéma n’est rien d’autre que le schéma d’Euler explicite.
Si le schéma est explicite, alors il est forcément d’ordre 1.
Une méthode de Runge-Kutta à 1 étage pour \(\varphi(t,y)=-\beta y\) s’écrit :
\(
\begin{cases}
u_0=y_0,\\
u_{n+1}=u_{n}+h K_1& n=0,1,\dots N-1\\
K_1=-\beta \left( u_n+hc_1K_1 \right).
\end{cases}
\)
On trouve donc \((1+\beta hc_1)K_1=-\beta u_n\) ainsi
\(
\begin{cases}
u_0 = y_0 \\
u_{n+1} = \left(1-\frac{(\beta h)}{1+c_1(\beta h)}\right)u_n & n=0,1,\dots N-1
\end{cases}
\)
Remarque : si on utilise directement la relation de récurrence \( q(h\beta) = 1 - \beta h \mathbf{b}^T (\mathbb{I} + \beta h \mathbb{A})^{-1} \mathbf{1} = 1-\beta h b_1 (1+\beta h a_{11})^{-1} = 1-\beta h (1+\beta h c_1)^{-1} = 1 - \frac{\beta h}{1+c_1\beta h} , \) ce qui correspond au résultat trouvé précédemment.
Par conséquent, \(\lim\limits_{n\to+\infty}u_n=0\) si et seulement si
\(
\left|1-\frac{\beta h}{1+c_1\beta h}\right|<1.
\)
Notons \(x\) le produit \(\beta h>0\) (donc \(x>0\)) et \(q\) la fonction \(q(x)=1-\frac{x}{1+c_1x}\) (avec \(c_1\in[0;1]\)).
\( \begin{aligned} |q(x)|<1 &\quad\iff\quad -1<1-\frac{x}{1+c_1x}<1 \quad\iff\quad \begin{cases} \frac{x}{1+c_1x}<2\\ \frac{x}{1+c_1x}>0 \end{cases} \\ &\quad\stackrel{\substack{x>0\\c_1\ge0}}{\iff}\quad \frac{x}{1+c_1x}<2 \quad\stackrel{c_1x\ge0}{\iff}\quad x<2(1+c_1x) \\ &\quad\iff\quad (1-2c_1)x<2 \quad\iff\quad \begin{cases} x<\frac{2}{1-2c_1}&\text{si }1-2c_1>0\\ \forall x&\text{sinon.} \end{cases} \end{aligned} \)
Conclusion :
Pour nos exemples, on obtient :
# Vérifions que pour s=1, on retrouve bien la formule de q
q = calculer_q_rk_general(1) # implicite
display(Markdown(f"\(q(x) = {sp.latex(q)}\)"))\(q(x) = \frac{a_{11} x - b_{1} x + 1}{a_{11} x + 1}\)
Étudier les méthodes RK avec \(s=2\) consistantes :
Les méthodes avec \(s=2\) consistantes ont pour matrice de Butcher
\( \begin{array}{c|cc} c_1 & a_{11} & a_{12}\\ c_2 & a_{21} & a_{22}\\ \hline & b_1 & b_2 \end{array} \quad \text{ avec } \quad \begin{cases} c_1=a_{11}+a_{12}\\ c_2=a_{21}+a_{22}\\ 1 = b_1+b_2 \end{cases} \) ce qui nous donne les schémas suivants : \( \boxed{ \begin{array}{c|cc} c_1 & c_1-a_{12} & a_{12}\\ c_2 & c_2-a_{22} & a_{22}\\ \hline & 1-b_2 & b_2 \end{array} \quad \leadsto \begin{cases} u_0 = y_0 \\ K_1 = \varphi\left(t_n+hc_1,u_n+h((c_1-a_{12})a_{11}K_1+ a_{12}K_2)\right)\\ K_2 = \varphi\left(t_n+hc_2,u_n+h(a_{21}K_1+ (c_2-a_{22})K_2)\right)\\ u_{n+1} = u_n + h\left((1-b_2)K_1+b_2K_2\right) & n=0,1,\dots N-1 \end{cases} } \)
Donc, on a bien \(s^2+2s-(s+1)=5\) degrés de liberté.
Pour l’implémentation, il s’agit de résoudre un système non linéaire de dimension 2 pour trouver les \(K_i\). Les inconnues étant des évaluations de \(\varphi\), lorsqu’on utilise une méthode de point fixe pour trouver les \(K_i\) il faut indiquer comme point de départ une évaluation de \(\varphi\) en des points connus, par exemple \(\varphi(t_n,u_n)\).
def RK(tt,phi,y0):
h = tt[1]-tt[0]
uu = np.empty_like(tt)
uu[0] = y0
for n in range(len(tt)-1):
# X = [K1,K2]
sys = lambda X : [ -X[0]+phi( tt[n]+h*c1 , uu[n]+h*(a11*X[0]+a12*X[1]) ) ,
-X[1]+phi( tt[n]+h*c2 , uu[n]+h*(a21*X[0]+a22*X[1]) )
]
K_start = phi(tt[n],uu[n])
K1, K2 = fsolve( sys , [K_start,K_start ] )
uu[n+1] = uu[n]+h*(b1*K1+b2*K2)
return uuVoici un exemple, appelé méthode de Gauss: \( \begin{array}{c|cc} \frac{1}{2}-\gamma & \frac{1}{4} & \frac{1}{4}-\gamma\\ \frac{1}{2}+\gamma & \frac{1}{4}+\gamma & \frac{1}{4}\\ \hline & \frac{1}{2} & \frac{1}{2} \end{array} \qquad\text{avec }\gamma=\frac{\sqrt{3}}{6}=\frac{1}{2\sqrt{3}}. \)
Cette méthode est d’ordre 4 et on peut monter que c’est la seule méthode d’ordre 4 à deux étages.
gamma = sp.sqrt(3)/6
c = [ sp.Rational(1,2)-gamma, sp.Rational(1,2)+gamma ]
b = [ sp.Rational(1,2), sp.Rational(1,2) ]
A = [ [ sp.Rational(1,4), sp.Rational(1,4)-gamma ] ,
[ sp.Rational(1,4)+gamma, sp.Rational(1,4) ] ]
s = len(c)
# ordre_RK(s=s)
ordre_RK(s=s,type="implicite",A=A,b=b,c=c);Matrice de Butcher
\(\displaystyle \left[\begin{matrix}\frac{1}{2} - \frac{\sqrt{3}}{6} & \frac{1}{4} & \frac{1}{4} - \frac{\sqrt{3}}{6}\\\frac{\sqrt{3}}{6} + \frac{1}{2} & \frac{1}{4} + \frac{\sqrt{3}}{6} & \frac{1}{4}\\ & \frac{1}{2} & \frac{1}{2}\end{matrix}\right]\)
On a 3 conditions pour avoir consistance (= pour être d’ordre 1)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 1 condition pour être d’ordre 2
\(\displaystyle \text{True}\)
On doit ajouter 2 conditions pour être d’ordre 3
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 4 conditions pour être d’ordre 4
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
Les méthodes semi-implicites vérifient, de plus, \(a_{12}=0\) ainsi la matrice de Butcher est \( \begin{array}{c|cc} c_1 & c_1 & 0\\ c_2 & c_2-a_{22} & a_{22}\\ \hline & 1-b_2 & b_2 \end{array} \quad \implies \begin{cases} u_0 = y_0 \\ K_1 = \varphi\left(t_n+hc_1,u_n+hc_{1}K_1\right)\\ K_2 = \varphi\left(t_n+hc_2,u_n+h\big((c_2-a_{22})K_1+ a_{22}K_2\big)\right)\\ u_{n+1} = u_n + h\left((1-b_2)K_1+b_2K_2\right) & n=0,1,\dots N-1 \end{cases} \)
Pour l’implémentation, il s’agit de résoudre des équations non linéaires séparément pour trouver les \(K_i\). Les inconnues étant des évaluations de \(\varphi\), lorsqu’on utilise une méthode de point fixe pour trouver les \(K_i\) il faut indiquer comme point de départ une évaluation de \(\varphi\) en des points connus, par exemple \(\varphi(t_n,u_n)\).
def RK(tt,phi,y0):
h = tt[1]-tt[0]
uu = np.empty_like(tt)
uu[0] = y0
for n in range(len(tt)-1):
# X = [K1,K2]
K_start = phi(tt[n],uu[n])
K1 = fsolve( lambda x : -x+phi( tt[n]+h*c1 , uu[n]+h*(a11*x) ) , K_start ) [0]
K2 = fsolve( lambda x : -x+phi( tt[n]+h*c2 , uu[n]+h*(a21*K1+a22*x) ) , K_start ) [0]
uu[n+1] = uu[n]+h*(b1*K1+b2*K2)
return uuPar exemple, si on choisit \(c_1=0\), \(c_2=1\) et \(a_{22}=b_2=\frac{1}{2}\) on trouve le schéma semi-implicite \( \begin{array}{c|cc} 0 & 0 & 0\\ 1 & \frac{1}{2} & \frac{1}{2}\\ \hline & \frac{1}{2} & \frac{1}{2} \end{array} \quad \implies \begin{cases} u_0 = y_0 \\ K_1 = \varphi\left(t_{n},u_n\right)\\ K_2 = \varphi\left(t_{n+1},u_n+\frac{h}{2}(K_1+K_2)\right)\\ u_{n+1} = u_n + \frac{h}{2}(K_1+K_2) & n=0,1,\dots N-1 \end{cases} \)
Notons que ce schéma n’est rien d’autre que le schéma de Crank-Nicolson car \(u_{n+1} = u_n+\frac{h}{2}(K_1+K_2)\), donc si on remplace le \(u_n+\frac{h}{2}(K_1+K_2)\) dans la définition de \(K_2\) par \(u_{n+1}\) on obtient \( K_2 = \varphi\left(t_{n+1},u_n+\frac{h}{2}(K_1+K_2)\right) = \varphi\left(t_{n+1},u_{n+1}\right) \) ainsi \( u_{n+1} = u_n+\frac{h}{2}(K_1+K_2)=u_n + \frac{h}{2}(\varphi\left(t_{n},u_n\right)+\varphi\left(t_{n+1},u_{n+1}\right)) \)
Il s’agit donc d’un schéma d’ordre 2.
c = [0, 1]
b = [sp.Rational(1,2), sp.Rational(1,2)]
A = [[0, 0], [sp.Rational(1,2), sp.Rational(1,2)]]
s = len(c)
# ordre_RK(s=s)
ordre_RK( s=s, type="implicite", A=A, b=b, c=c );Matrice de Butcher
\(\displaystyle \left[\begin{matrix}0 & 0 & 0\\1 & \frac{1}{2} & \frac{1}{2}\\ & \frac{1}{2} & \frac{1}{2}\end{matrix}\right]\)
On a 3 conditions pour avoir consistance (= pour être d’ordre 1)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 1 condition pour être d’ordre 2
\(\displaystyle \text{True}\)
On doit ajouter 2 conditions pour être d’ordre 3
\(\displaystyle \text{False}\)
\(\displaystyle \text{False}\)
On doit ajouter 4 conditions pour être d’ordre 4
\(\displaystyle \text{False}\)
\(\displaystyle \text{False}\)
\(\displaystyle \text{False}\)
\(\displaystyle \text{False}\)
Un autre exemple est la méthode dite DIRK (Diagonally Implicit Runge-Kutta) qui est d’ordre 3: \( \begin{array}{c|cc} \frac{1}{3} & \frac{1}{3} & 0\\ 1 & 1 & 0\\ \hline & \frac{3}{4} & \frac{1}{4} \end{array} \quad \implies \begin{cases} u_0 = y_0 \\ K_1 = \varphi\left(t_{n}+\frac{1}{3}h,u_n+\frac{1}{3}hK_1\right)\\ K_2 = \varphi\left(t_{n+1},u_n+hK_1\right)\\ u_{n+1} = u_n + \frac{h}{4}(3K_1+K_2) & n=0,1,\dots N-1 \end{cases} \)
c = [sp.Rational(1,3), 1]
b = [sp.Rational(3,4), sp.Rational(1,4)]
A = [[sp.Rational(1,3),0],[1,0]]
ss = len(c)
# ordre_RK(s=s)
ordre_RK( s=s, A=A, b=b, c=c );Matrice de Butcher
\(\displaystyle \left[\begin{matrix}\frac{1}{3} & \frac{1}{3} & 0\\1 & 1 & 0\\ & \frac{3}{4} & \frac{1}{4}\end{matrix}\right]\)
On a 3 conditions pour avoir consistance (= pour être d’ordre 1)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 1 condition pour être d’ordre 2
\(\displaystyle \text{True}\)
On doit ajouter 2 conditions pour être d’ordre 3
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 4 conditions pour être d’ordre 4
\(\displaystyle \text{False}\)
\(\displaystyle \text{False}\)
\(\displaystyle \text{False}\)
\(\displaystyle \text{False}\)
Les méthodes avec \(s=2\) explicites ont pour matrice de Butcher \( \begin{array}{c|cc} 0 & 0 & 0\\ c_2 & c_{2} & 0\\ \hline & 1-b_2 & b_2 \end{array} \quad \implies \begin{cases} u_0 = y_0 \\ K_1 = \varphi\left(t_n,u_n\right)\\ K_2 = \varphi\left(t_n+hc_2,u_n+hc_2K_1\right)\\ u_{n+1} = u_n + h\left((1-b_2)K_1+b_2K_2\right) & n=0,1,\dots N-1 \end{cases} \)
def RK(tt,phi,y0):
h = tt[1]-tt[0]
uu = np.empty_like(tt)
uu[0] = y0
for n in range(len(tt)-1):
K1 = phi( tt[n], uu[n] )
K2 = phi( tt[n]+h*c2 , uu[n]+h*(c2*K1) )
uu[n+1] = uu[n]+h*(b1*K1+b2*K2)
return uuUn schéma RK à deux étage explicite est au mieux d’ordre 2. Pour avoir l’ordre 2 il faut que \(b_2c_2=\frac{1}{2}\) ainsi il s’écrit \( \begin{array}{c|cc} 0 & 0 & 0\\ \frac{1}{2\alpha} & \frac{1}{2\alpha} & 0\\ \hline & 1-\alpha & \alpha \end{array} \quad \implies \begin{cases} u_0 = y_0 \\ K_1 = \varphi\left(t_n,u_n\right)\\ K_2 = \varphi\left(t_n+\frac{h}{2}\alpha,u_n+\frac{h}{2}\alpha K_1\right)\\ u_{n+1} = u_n + h\left((1-\alpha)K_1+\alpha K_2\right) & n=0,1,\dots N-1 \end{cases} \)
Voici quelques cas particuliers :
\(\alpha=\frac{1}{2}\): schéma de Heun \( \begin{array}{c|cc} 0 & 0 & 0\\ 1 & 1 & 0\\ \hline & \frac{1}{2} & \frac{1}{2} \end{array} \quad \implies \begin{cases} u_0 = y_0 \\ K_1 = \varphi(t_n,u_n)\\ K_2 = \varphi(t_{n+1},u_{n}+hK_1)\\ u_{n+1} = u_n + h\left(\frac{1}{2}K_1+\frac{1}{2}K_2\right) & n=0,1,\dots N-1 \end{cases} \)
\(\alpha=1\): schéma d’Euler Modifié (ou du point milieu) \( \begin{array}{c|cc} 0 & 0 & 0\\ \frac{1}{2} & \frac{1}{2} & 0\\ \hline & 0 & 1 \end{array} \quad \implies \begin{cases} u_0 = y_0 \\ K_1 = \varphi(t_n,u_n)\\ K_2 = \varphi(t_{n}+\frac{1}{2}h,u_{n}+\frac{1}{2}hK_1)\\ u_{n+1} = u_n + h K_2 & n=0,1,\dots N-1 \end{cases} \)
\(\alpha=\frac{2}{3}\): schéma de Ralston \( \begin{array}{c|cc} 0 & 0 & 0\\ \frac{3}{4} & \frac{3}{4} & 0\\ \hline & \frac{1}{3} & \frac{2}{3} \end{array} \quad \implies \begin{cases} u_0 = y_0 \\ K_1 = \varphi(t_n,u_n)\\ K_2 = \varphi(t_{n}+\frac{3}{4}h,u_{n}+\frac{3}{4}hK_1)\\ u_{n+1} = u_n + \frac{h}{3} (K_1+2K_2) & n=0,1,\dots N-1 \end{cases} \)
Notons \(x\) le produit \(\beta h>0\) (donc \(x>0\)).
Le schéma RK explicite à 2 étages appliqué à cette équation devient \( \begin{cases} u_0 = y_0 \\ K_1 = -\beta u_n\\ K_2 = -\beta (u_n+hc_2K_1)\\ u_{n+1} = u_n + h\left((1-b_2)K_1+b_2K_2\right) & n=0,1,\dots N-1 \end{cases} \) ainsi \( K_2 = -\beta u_n-\beta h c_2K_1 = K_1 -\beta h c_2K_1 \) et \( \begin{aligned} u_{n+1} &= u_n + h (1-b_2)K_1 + h b_2K_2 \\ &= u_n + h (1-b_2)K_1 + h b_2 (K_1 -\beta h c_2K_1) \\ &= u_n + h K_1 -\beta h^2 b_2c_2K_1 \\ &= u_n + (1 -\beta h b_2c_2) h K_1 \\ &= u_n + (1 -\beta h b_2c_2) h (-\beta u_n) \\ &= (1 -\beta h + (\beta h)^2 b_2c_2) u_n \end{aligned} \) et enfin \(\begin{cases} u_0 = y_0 \\ u_{n+1} = \left(1-(\beta h)+c_2b_2(\beta h)^2\right)u_n & n=0,1,\dots N-1 \end{cases}\)
Par conséquent, \(\lim\limits_{n\to+\infty}u_n=0\) si et seulement si \( \left|1-(\beta h)+c_2b_2(\beta h)^2\right|<1. \)
Remarque : pour trouver cette relation de récurrence, on peut aussi utiliser directement la formule générale \(q(x) = 1 - x \mathbf{b}^T (\mathbb{I} + x \mathbb{A})^{-1} \mathbf{1}\) ayant posé \(x = \beta h\). La matrice \((\mathbb{I} + x \mathbb{A})\) est \( \mathbb{I} + x \mathbb{A} = \begin{pmatrix} 1 & 0 \\ x c_2 & 1 \end{pmatrix}. \) Puisque c’est une matrice triangulaire avec des 1 sur la diagonale, son déterminant est 1 et son inverse est immédiat : \( (\mathbb{I} + x \mathbb{A})^{-1} = \begin{pmatrix} 1 & 0 \\ -x c_2 & 1 \end{pmatrix}. \) On développe le produit matriciel dans la formule \(q(x) = 1 - x \mathbf{b}^T (\mathbb{I} + x \mathbb{A})^{-1} \mathbf{1}\) : \( \begin{aligned} q(x) &= 1 - x \begin{pmatrix} b_1 & b_2 \end{pmatrix} \begin{pmatrix} 1 & 0 \\ -x c_2 & 1 \end{pmatrix} \begin{pmatrix} 1 \\ 1 \end{pmatrix} \\ &= 1 - x \begin{pmatrix} b_1 & b_2 \end{pmatrix} \begin{pmatrix} 1 \\ 1 - x c_2 \end{pmatrix} \\ &= 1 - x \left( b_1 + b_2(1 - x c_2) \right) \\ &= 1 - x(b_1 + b_2) + x^2(b_2 c_2)\\ &= 1 - x + x^2(b_2 c_2). \end{aligned} \)
Notons \(q\) le polynôme \(q(x)=1-x+c_2b_2x^2\).
Si \(c_2b_2=0\), le schéma se réduit au schéma d’Euler explicite.
Si \(c_2b_2>0\), c’est une parabole convexe et le sommet est situé en \(\left(\frac{1}{2c_2b_2}>0,1-\frac{1}{4c_2b_2}\right)\). \( |q(x)|<1 \quad\iff\quad x<\frac{1}{c_2b_2}. \) En particulier, lorsque le schéma est d’ordre 2 on a \(b_2c_2=\frac{1}{2}\) et le schéma est A-stable ssi \(h<\frac{2}{\beta}\).
Si \(c_2b_2<0\), c’est une parabole concave et le sommet est situé en \(\left(\frac{1}{2c_2b_2}<0,1-\frac{1}{4c_2b_2}\right)\). \( |q(x)|<1 \quad\iff\quad x<\frac{1-\sqrt{1-8b_2c_2}}{2b_2c_2}. \)
# q = calculer_q_rk_general(2) # implicite
# explicite
c_2, b_2 = sp.symbols('c_2 b_2')
A = sp.Matrix([[0, 0], [c_2, 0]])
b = sp.Matrix([1 - b_2, b_2])
display(Markdown(f"\(A = {sp.latex(A)},\\qquad b^T = {sp.latex(b.T)}\)"))
q = calculer_q_rk_general(2, A=A, b=b)
display(Markdown(f"\(q(x) = {sp.latex(q)}\)"))\(A = \left[\begin{matrix}0 & 0\\c_{2} & 0\end{matrix}\right],\qquad b^T = \left[\begin{matrix}1 - b_{2} & b_{2}\end{matrix}\right]\)
\(q(x) = b_{2} c_{2} x^{2} - x + 1\)
Un schéma RK à \(3\) étages explicite a pour matrice de Butcher \( \begin{array}{c|ccc} 0 & 0 & 0 & 0 \\ c_2 & a_{21} & 0&0\\ c_3 & a_{31} &a_{32}&0\\ \hline & b_1 & b_2 & b_3 \end{array} \text{ avec } \begin{cases} c_2=a_{21}\\ c_3=a_{31}+a_{32}\\ b_1+b_2+b_3=1 \end{cases} \quad \implies \begin{cases} u_0 = y_0 \\ K_1 = \varphi\left(t_n,u_n\right)\\ K_2 = \varphi\left(t_n+hc_2,u_n+hc_2K_1\right)\\ K_3 = \varphi\left(t_n+hc_3,u_n+h(a_{31}K_1+ a_{32}K_2)\right)\\ u_{n+1} = u_n + h\left(b_1K_1+b_2K_2+b_3K_3\right) & n=0,1,\dots N-1 \end{cases} \)
Voici trois exemples:
schéma de Heun à trois étages \( \begin{array}{c|ccc} 0 & 0 & 0 & 0 \\ \frac{1}{3} & \frac{1}{3} & 0&0\\ \frac{2}{3} & 0 &\frac{2}{3}&0\\ \hline & \frac{1}{4} & 0 & \frac{3}{4} \end{array} \quad \implies \begin{cases} u_0 = y_0 \\ K_1 = \varphi\left(t_n,u_n\right)\\ K_2 = \varphi\left(t_n+\frac{h}{3},u_n+\frac{h}{3}K_1\right)\\ K_3 = \varphi\left(t_n+\frac{2}{3}h,u_n+\frac{2}{3}hK_2\right)\\ u_{n+1} = u_n + \frac{h}{4}\left(K_1+3K_3\right) & n=0,1,\dots N-1 \end{cases} \)
Étant une méthode explicite à 3 étapes, elle est au mieux d’ordre 3. Vérifions qu’elle est effectivement d’ordre 3:
c = [0, sp.Rational(1,3), sp.Rational(2,3)]
b = [sp.Rational(1,4), 0, sp.Rational(3,4)]
A = [[0, 0, 0],
[sp.Rational(1,3), 0, 0],
[0, sp.Rational(2,3), 0]]
s = len(c)
# ordre_RK(s=s)
ordre_RK(s=s,type="explicite",A=A,b=b,c=c);Matrice de Butcher
\(\displaystyle \left[\begin{matrix}0 & 0 & 0 & 0\\\frac{1}{3} & \frac{1}{3} & 0 & 0\\\frac{2}{3} & 0 & \frac{2}{3} & 0\\ & \frac{1}{4} & 0 & \frac{3}{4}\end{matrix}\right]\)
On a 4 conditions pour avoir consistance (= pour être d’ordre 1)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 1 condition pour être d’ordre 2
\(\displaystyle \text{True}\)
On doit ajouter 2 conditions pour être d’ordre 3
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
# Calculons le facteur q(beta h)
b = sp.Matrix(b)
A = sp.Matrix(A)
q = calculer_q_rk_general(s=s,A=A,b=b)
display(Markdown(f"\(q(x) = {sp.latex(q)}\)"))\(q(x) = - \frac{x^{3}}{6} + \frac{x^{2}}{2} - x + 1\)
schéma de Kutta \( \begin{array}{c|ccc} 0 & 0 & 0 & 0 \\ \frac{1}{2} & \frac{1}{2} & 0&0\\ 1 & -1 &2&0\\ \hline & \frac{1}{6} & \frac{2}{3} & \frac{1}{6} \end{array} \quad \implies \begin{cases} u_0 = y_0 \\ K_1 = \varphi\left(t_n,u_n\right)\\ K_2 = \varphi\left(t_n+\frac{h}{2},u_n+\frac{h}{2}K_1\right)\\ K_3 = \varphi\left(t_{n+1},u_n+h(-K_1+2K_2)\right)\\ u_{n+1} = u_n + \frac{h}{6}\left(K_1+4K_2+K_3\right) & n=0,1,\dots N-1 \end{cases} \)
Étant une méthode explicite à 3 étages, elle a au mieux d’ordre 3. On vérifie ci-dessous qu’elle est d’ordre 3 :
c = [0, sp.S(1)/2, 1]
b = [sp.S(1)/6, sp.S(2)/3, sp.S(1)/6]
A = [[0, 0, 0],
[sp.S(1)/2, 0, 0],
[-1, 2, 0]]
s = len(c)
# ordre_RK(s=s)
ordre_RK(s=s,A=A,b=b,c=c);Matrice de Butcher
\(\displaystyle \left[\begin{matrix}0 & 0 & 0 & 0\\\frac{1}{2} & \frac{1}{2} & 0 & 0\\1 & -1 & 2 & 0\\ & \frac{1}{6} & \frac{2}{3} & \frac{1}{6}\end{matrix}\right]\)
On a 4 conditions pour avoir consistance (= pour être d’ordre 1)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 1 condition pour être d’ordre 2
\(\displaystyle \text{True}\)
On doit ajouter 2 conditions pour être d’ordre 3
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 4 conditions pour être d’ordre 4
\(\displaystyle \text{True}\)
\(\displaystyle \text{False}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{False}\)
# Calculons le facteur q(beta h)
b = sp.Matrix(b)
A = sp.Matrix(A)
q = calculer_q_rk_general(s=s,A=A,b=b)
display(Markdown(f"\(q(x) = {sp.latex(q)}\)"))\(q(x) = - \frac{x^{3}}{6} + \frac{x^{2}}{2} - x + 1\)
schéma \( \begin{array}{c|ccc} 0 & 0 & 0 & 0 \\ \frac{1}{2} & \frac{1}{2} & 0&0\\ 1 & -1 &2&0\\ \hline & -\frac{1}{6} & \frac{4}{3} & -\frac{1}{6} \end{array} \quad \implies \begin{cases} u_0 = y_0 \\ K_1 = \varphi\left(t_n,u_n\right)\\ K_2 = \varphi\left(t_n+\frac{h}{2},u_n+\frac{h}{2}K_1\right)\\ K_3 = \varphi\left(t_{n+1},u_n+h(-K_1+2K_2)\right)\\ u_{n+1} = u_n + \frac{h}{6}\left(-K_1+8K_2-K_3\right) & n=0,1,\dots N-1 \end{cases} \)
Étant une méthode explicite à 3 étages, elle a au mieux d’ordre 3. On vérifie ci-dessous qu’elle n’est que d’ordre 2 :
c = [0, sp.Rational(1,2), 1]
b = [-sp.Rational(1,6), sp.Rational(4,3), -sp.Rational(1,6)]
A = [[0, 0, 0], [sp.Rational(1,2), 0, 0], [-1, 2, 0]]
s = len(c)
# ordre_RK(s=s)
ordre_RK(s=s,A=A,b=b,c=c);Matrice de Butcher
\(\displaystyle \left[\begin{matrix}0 & 0 & 0 & 0\\\frac{1}{2} & \frac{1}{2} & 0 & 0\\1 & -1 & 2 & 0\\ & - \frac{1}{6} & \frac{4}{3} & - \frac{1}{6}\end{matrix}\right]\)
On a 4 conditions pour avoir consistance (= pour être d’ordre 1)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 1 condition pour être d’ordre 2
\(\displaystyle \text{True}\)
On doit ajouter 2 conditions pour être d’ordre 3
\(\displaystyle \text{False}\)
\(\displaystyle \text{False}\)
On doit ajouter 4 conditions pour être d’ordre 4
\(\displaystyle \text{False}\)
\(\displaystyle \text{False}\)
\(\displaystyle \text{False}\)
\(\displaystyle \text{False}\)
# Calculons le facteur q(beta h)
b = sp.Matrix(b)
A = sp.Matrix(A)
q = calculer_q_rk_general(s=s,A=A,b=b)
display(Markdown(f"\(q(x) = {sp.latex(q)}\)"))\(q(x) = \frac{x^{3}}{6} + \frac{x^{2}}{2} - x + 1\)
Un schéma RK à \(4\) étages explicite a pour matrice de Butcher \( \begin{array}{c|cccc} 0 & 0 & 0 & 0 & 0\\ c_2 & a_{21} & 0&0&0\\ c_3 & a_{31} &a_{32}&0&0\\ c_4 & a_{41} &a_{42}&a_{43}&0\\ \hline & b_1 & b_2 & b_3 & b_4 \end{array} \text{ avec } \begin{cases} c_2=a_{21}\\ c_3=a_{31}+a_{32}\\ c_4=a_{41}+a_{42}+a_{43}\\ b_1+b_2+b_3+b_4=1 \end{cases} \quad \implies \begin{cases} u_0 = y_0 \\ K_1 = \varphi\left(t_n,u_n\right)\\ K_2 = \varphi\left(t_n+hc_2,u_n+h(a_{21}K_1)\right)\\ K_3 = \varphi\left(t_n+hc_3,u_n+h(a_{31}K_1+ a_{32}K_2)\right)\\ K_4 = \varphi\left(t_n+hc_4,u_n+h(a_{41}K_1+ a_{42}K_2+ a_{43}K_3)\right)\\ u_{n+1} = u_n + h\left(b_1K_1+b_2K_2+b_3K_3+b_4K_4\right) & n=0,1,\dots N-1 \end{cases} \)
Voici deux exemples (le premier est le plus connus):
c = [0, sp.Rational(1,2), sp.Rational(1,2), 1]
b = [sp.Rational(1,6), sp.Rational(1,3), sp.Rational(1,3), sp.Rational(1,6)]
A = [[0, 0, 0, 0],
[sp.Rational(1,2), 0, 0, 0],
[0, sp.Rational(1,2), 0, 0],
[0, 0, 1, 0]]
s = len(c)
# ordre_RK(s=s)
ordre_RK(s=s,A=A,b=b,c=c);Matrice de Butcher
\(\displaystyle \left[\begin{matrix}0 & 0 & 0 & 0 & 0\\\frac{1}{2} & \frac{1}{2} & 0 & 0 & 0\\\frac{1}{2} & 0 & \frac{1}{2} & 0 & 0\\1 & 0 & 0 & 1 & 0\\ & \frac{1}{6} & \frac{1}{3} & \frac{1}{3} & \frac{1}{6}\end{matrix}\right]\)
On a 5 conditions pour avoir consistance (= pour être d’ordre 1)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 1 condition pour être d’ordre 2
\(\displaystyle \text{True}\)
On doit ajouter 2 conditions pour être d’ordre 3
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 4 conditions pour être d’ordre 4
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
# Calculons le facteur q(beta h)
b = sp.Matrix(b)
A = sp.Matrix(A)
q = calculer_q_rk_general(s=s,A=A,b=b)
display(Markdown(f"\(q(x) = {sp.latex(q)}\)"))\(q(x) = \frac{x^{4}}{24} - \frac{x^{3}}{6} + \frac{x^{2}}{2} - x + 1\)
c = [0, sp.Rational(1,4), sp.Rational(1,2), 1]
b = [sp.Rational(1,6), 0, sp.Rational(2,3), sp.Rational(1,6)]
A = [ [0, 0, 0, 0],
[sp.Rational(1,4), 0, 0, 0],
[0, sp.Rational(1,2), 0, 0],
[1, -2, 2, 0] ]
s = len(c)
# ordre_RK(s=s)
ordre_RK(s=s,A=A,b=b,c=c);Matrice de Butcher
\(\displaystyle \left[\begin{matrix}0 & 0 & 0 & 0 & 0\\\frac{1}{4} & \frac{1}{4} & 0 & 0 & 0\\\frac{1}{2} & 0 & \frac{1}{2} & 0 & 0\\1 & 1 & -2 & 2 & 0\\ & \frac{1}{6} & 0 & \frac{2}{3} & \frac{1}{6}\end{matrix}\right]\)
On a 5 conditions pour avoir consistance (= pour être d’ordre 1)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 1 condition pour être d’ordre 2
\(\displaystyle \text{True}\)
On doit ajouter 2 conditions pour être d’ordre 3
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 4 conditions pour être d’ordre 4
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
# Calculons le facteur q(beta h)
b = sp.Matrix(b)
A = sp.Matrix(A)
q = calculer_q_rk_general(s=s,A=A,b=b)
display(Markdown(f"\(q(x) = {sp.latex(q)}\)"))\(q(x) = \frac{x^{4}}{24} - \frac{x^{3}}{6} + \frac{x^{2}}{2} - x + 1\)
c = [0, sp.Rational(1,3), sp.Rational(2,3), 1]
b = [sp.Rational(1,8), sp.Rational(3,8), sp.Rational(3,8), sp.Rational(1,8)]
A = [ [0, 0, 0, 0],
[sp.Rational(1,3), 0, 0, 0],
[-sp.Rational(1,3), 1, 0, 0],
[1, -1, 1, 0] ]
s = len(c)
# ordre_RK(s=s)
ordre_RK(s=s,A=A,b=b,c=c);Matrice de Butcher
\(\displaystyle \left[\begin{matrix}0 & 0 & 0 & 0 & 0\\\frac{1}{3} & \frac{1}{3} & 0 & 0 & 0\\\frac{2}{3} & - \frac{1}{3} & 1 & 0 & 0\\1 & 1 & -1 & 1 & 0\\ & \frac{1}{8} & \frac{3}{8} & \frac{3}{8} & \frac{1}{8}\end{matrix}\right]\)
On a 5 conditions pour avoir consistance (= pour être d’ordre 1)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 1 condition pour être d’ordre 2
\(\displaystyle \text{True}\)
On doit ajouter 2 conditions pour être d’ordre 3
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 4 conditions pour être d’ordre 4
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
# Calculons le facteur q(beta h)
b = sp.Matrix(b)
A = sp.Matrix(A)
q = calculer_q_rk_general(s=s,A=A,b=b)
display(display(Markdown(f"\(q(x) = {sp.latex(q)}\)")))
\(q(x) = \frac{x^{4}}{24} - \frac{x^{3}}{6} + \frac{x^{2}}{2} - x + 1\)
NoneUn schéma RK à \(5\) étages explicite a pour matrice de Butcher \( \begin{array}{c|ccccc} 0 & 0 & 0 & 0 & 0 &0 \\ c_2 & a_{21} & 0&0&0&0\\ c_3 & a_{31} &a_{32}&0&0&0\\ c_4 & a_{41} &a_{42}&a_{43}&0&0\\ c_5 & a_{51} &a_{52}&a_{53}&a_{54}&0\\ \hline & b_1 & b_2 & b_3 & b_4 & b_5 \end{array} \quad \implies \begin{cases} u_0 = y_0 \\ K_1 = \varphi\left(t_n,u_n\right)\\ K_2 = \varphi\left(t_n+hc_2,u_n+h(a_{21}K_1)\right)\\ K_3 = \varphi\left(t_n+hc_3,u_n+h(a_{31}K_1+ a_{32}K_2\right)\\ K_4 = \varphi\left(t_n+hc_4,u_n+h(a_{41}K_1+ a_{42}K_2+ a_{43}K_3)\right)\\ K_5 = \varphi\left(t_n+hc_5,u_n+h(a_{51}K_1+ a_{52}K_2+ a_{53}K_3+ a_{54}K_4)\right)\\ u_{n+1} = u_n + h\left(b_1K_1+b_2K_2+b_3K_3+b_4K_4+b_5K_5\right) & n=0,1,\dots N-1 \end{cases} \) avec \( \begin{cases} c_2=a_{21}\\ c_3=a_{31}+a_{32}\\ c_4=a_{41}+a_{42}+a_{43}\\ c_5=a_{51}+a_{52}+a_{53}+a_{54}\\ b_1+b_2+b_3+b_4+b_5=1 \end{cases} \)
Voici un exemple:
c = [0, sp.Rational(1,3), sp.Rational(1,3), sp.Rational(1,2), 1]
b = [sp.Rational(1,6), 0, 0, sp.Rational(2,3), sp.Rational(1,6)]
A = [[0, 0, 0, 0, 0], [sp.Rational(1,3), 0, 0, 0, 0], [sp.Rational(1,6), sp.Rational(1,6), 0, 0, 0], [sp.Rational(1,8), 0, sp.Rational(3,8), 0, 0], [sp.Rational(1,2), 0, -sp.Rational(3,2), 2, 0]]
s = len(c)
# ordre_RK(s=s)
ordre_RK(s=s,A=A,b=b,c=c);Matrice de Butcher
\(\displaystyle \left[\begin{matrix}0 & 0 & 0 & 0 & 0 & 0\\\frac{1}{3} & \frac{1}{3} & 0 & 0 & 0 & 0\\\frac{1}{3} & \frac{1}{6} & \frac{1}{6} & 0 & 0 & 0\\\frac{1}{2} & \frac{1}{8} & 0 & \frac{3}{8} & 0 & 0\\1 & \frac{1}{2} & 0 & - \frac{3}{2} & 2 & 0\\ & \frac{1}{6} & 0 & 0 & \frac{2}{3} & \frac{1}{6}\end{matrix}\right]\)
On a 6 conditions pour avoir consistance (= pour être d’ordre 1)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 1 condition pour être d’ordre 2
\(\displaystyle \text{True}\)
On doit ajouter 2 conditions pour être d’ordre 3
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 4 conditions pour être d’ordre 4
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
# Calculons le facteur q(beta h)
b = sp.Matrix(b)
A = sp.Matrix(A)
q = calculer_q_rk_general(s=s,A=A,b=b)
display(Markdown(f"\(q(x) = {sp.latex(q)}\)"))\(q(x) = - \frac{x^{5}}{144} + \frac{x^{4}}{24} - \frac{x^{3}}{6} + \frac{x^{2}}{2} - x + 1\)
Un schéma RK à \(6\) étages explicite a pour matrice de Butcher \( \begin{array}{c|cccccc} 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ c_2 & a_{21} & 0 & 0 & 0 & 0 & 0\\ c_3 & a_{31} & a_{32} & 0 & 0 & 0 & 0\\ c_4 & a_{41} & a_{42} & a_{43} & 0 & 0 & 0\\ c_5 & a_{51} & a_{52} & a_{53} & a_{54} & 0 & 0\\ c_6 & a_{61} & a_{62} & a_{63} & a_{64} & a_{65} & 0\\ \hline & b_1 & b_2 & b_3 & b_4 & b_5 & b_6 \end{array} \quad \implies \begin{cases} u_0 = y_0 \\ K_1 = \varphi\left(t_n,u_n\right)\\ K_2 = \varphi\left(t_n+hc_2,u_n+h(a_{21}K_1)\right)\\ K_3 = \varphi\left(t_n+hc_3,u_n+h(a_{31}K_1+ a_{32}K_2\right)\\ K_4 = \varphi\left(t_n+hc_4,u_n+h(a_{41}K_1+ a_{42}K_2+ a_{43}K_3)\right)\\ K_5 = \varphi\left(t_n+hc_5,u_n+h(a_{51}K_1+ a_{52}K_2+ a_{53}K_3+ a_{54}K_4)\right)\\ K_6 = \varphi\left(t_n+hc_6,u_n+h(a_{61}K_1+ a_{62}K_2+ a_{63}K_3+ a_{64}K_4+ a_{65}K_5)\right)\\ u_{n+1} = u_n + h\left(b_1K_1+b_2K_2+b_3K_3+b_4K_4+b_5K_5+b_6K_6\right) & n=0,1,\dots N-1 \end{cases} \) avec \( \begin{cases} c_2=a_{21}\\ c_3=a_{31}+a_{32}\\ c_4=a_{41}+a_{42}+a_{43}\\ c_5=a_{51}+a_{52}+a_{53}+a_{54}\\ c_6=a_{61}+a_{62}+a_{63}+a_{64}+a_{65}\\ b_1+b_2+b_3+b_4+b_5+b_6=1 \end{cases} \)
Voici un exemple:
c = [0, sp.Rational(1,4), sp.Rational(1,4), sp.Rational(1,2), sp.Rational(3,4), 1]
b = [sp.Rational(7,90), 0, sp.Rational(32,90), sp.Rational(12,90), sp.Rational(32,90), sp.Rational(7,90)]
A = [[0, 0, 0, 0, 0, 0],
[sp.Rational(1,4), 0, 0, 0, 0, 0],
[sp.Rational(1,8), sp.Rational(1,8), 0, 0, 0, 0],
[0, sp.Rational(-1,2), 1, 0, 0, 0],
[sp.Rational(3,16), 0, 0, sp.Rational(9,16), 0, 0],
[sp.Rational(-3,7), sp.Rational(2,7), sp.Rational(12,7), sp.Rational(-12,7), sp.Rational(8,7), 0]]
s = len(c)
# ordre_RK(s=s)
ordre_RK(s=s,A=A,b=b,c=c);Matrice de Butcher
\(\displaystyle \left[\begin{matrix}0 & 0 & 0 & 0 & 0 & 0 & 0\\\frac{1}{4} & \frac{1}{4} & 0 & 0 & 0 & 0 & 0\\\frac{1}{4} & \frac{1}{8} & \frac{1}{8} & 0 & 0 & 0 & 0\\\frac{1}{2} & 0 & - \frac{1}{2} & 1 & 0 & 0 & 0\\\frac{3}{4} & \frac{3}{16} & 0 & 0 & \frac{9}{16} & 0 & 0\\1 & - \frac{3}{7} & \frac{2}{7} & \frac{12}{7} & - \frac{12}{7} & \frac{8}{7} & 0\\ & \frac{7}{90} & 0 & \frac{16}{45} & \frac{2}{15} & \frac{16}{45} & \frac{7}{90}\end{matrix}\right]\)
On a 7 conditions pour avoir consistance (= pour être d’ordre 1)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 1 condition pour être d’ordre 2
\(\displaystyle \text{True}\)
On doit ajouter 2 conditions pour être d’ordre 3
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
On doit ajouter 4 conditions pour être d’ordre 4
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
\(\displaystyle \text{True}\)
# Calculons le facteur q(beta h)
b = sp.Matrix(b)
A = sp.Matrix(A)
q = calculer_q_rk_general(s=s,A=A,b=b)
display(Markdown(f"\(q(x) = {sp.latex(q)}\)"))\(q(x) = \frac{x^{6}}{640} - \frac{x^{5}}{120} + \frac{x^{4}}{24} - \frac{x^{3}}{6} + \frac{x^{2}}{2} - x + 1\)
La manière la plus simple pour appliquer une méthode de résolution numérique consiste à utiliser un pas \(h\) constant. La principale difficulté est alors de choisir a priori la valeur optimale de ce pas \(h\) : il faut qu’il soit suffisamment petit pour garantir une précision suffisante, mais pas trop petit pour éviter de surcharger inutilement le calcul. Par ailleurs, la solution que l’on cherche à approcher peut nécessiter un pas \(h\) petit à certains endroits et plus grand à d’autres. Ainsi, si l’on accepte l’idée d’utiliser une discrétisation non uniforme, on peut décider de construire une méthode qui choisit à chaque itération \(n\) la taille du pas d’intégration \(h\), potentiellement différents à chaque itération. Pour ce faire, on a besoin d’estimer l’erreur \(\varepsilon_{n}\) que l’on commet lorsque l’on effectue une itération du schéma, afin de le comparer à une erreur « acceptable » “tol” : si \(\varepsilon_n\le \text{tol}\), on pourra augmenter la taille du pas d’intégration (si possible), et si au contraire \(\varepsilon_n> \text{tol}\), la dernière étape effectuée n’est pas acceptable, la taille du pas est diminuée et on répète les deux calculs.
Ce procédé, appelé adaptation du pas de discrétisation, est efficace mais nécessite d’avoir un bon estimateur d’erreur locale. En général, il s’agit d’un estimateur d’erreur a posteriori, car les estimateurs d’erreur a priori sont trop compliqués en pratique. On peut construire l’estimateur d’erreur de deux manières :
Choix et ajustement du pas : dans la pratique, on impose un encadrement du pas de temps \(h_{\min} \le h_n \le h_{\max}\), où \(h_{\min}\) est fixé par les contraintes de temps de calcul et par la croissance des erreurs d’arrondi lorsque le pas devient trop petit, et \(h_{\max}\) par des considérations de stabilité et de précision globale. À chaque itération, l’erreur locale est estimée par \( \varepsilon_{n+1} = \frac{\left| u_{n+1} - \hat u_{n+1} \right|}{h_n}. \) Étant donnée une tolérance prescrite \(\text{tol} >0\), le pas est ajusté selon les règles suivantes : - si \(\varepsilon_{n+1} > \text{tol}\), le pas est jugé trop grand et l’étape est rejetée ; on diminue alors le pas, par exemple en posant \( h_{n+1} = 0.8 h_n ; \)
Une méthode courante pour garantir la précision dans la résolution d’un problème de Cauchy est de résoudre le problème deux fois en utilisant des pas \(h\) et \(h/2\), puis de comparer les approximations obtenues aux points de maillage correspondant à la grille la plus grossière. Autrement dit, à chaque étape, deux approximations différentes de la solution sont calculées
L’erreur est donc estimée par la différence entre ces deux approximations : \( \varepsilon_{n+1} = \frac{\left| u_{n+1} - \hat u_{n+1} \right|}{h}. \)
Selon la valeur de \(\varepsilon_{n+1}\), on peut alors décider d’augmenter \(h\) ou de le diminuer pour la prochaine itération.
La méthode d’Euler explicite est bien adaptée à un calcul dynamique du pas de discrétisation \(h\) tenant compte des variations de l’inconnue sur l’intervalle d’intégration. Ici, l’estimateur d’erreur peut être construit à l’aide de deux pas de discrétisation (typiquement \(h\) et \(h/2\)).
Voyons un exemple d’implémentation de la méthode d’Euler explicite à pas adaptatif.
def EE( phi, tt, y0 ):
h = tt[1]-tt[0]
uu = np.empty_like(tt)
uu[0] = y0
for n in range(len(tt)-1):
uu[n+1] = uu[n]+h*phi(tt[n],uu[n])
return uu
def Adaptatif_EE(phi, t0, tfinal, y0, tol, hinit, hmin, hmax):
tt = [t0]
uu = [y0]
h = hinit
while tt[-1] < tfinal:
t = tt[-1]
u = uu[-1]
# Un pas d'Euler (h)
u_gr = u + h * phi(t, u)
# Deux pas d'Euler (h/2)
v = u + (h/2) * phi(t, u)
u_fi = v + (h/2) * phi(t + h/2, v)
# Estimation de l'erreur
err = abs(u_gr - u_fi) / h
if err > tol:
# Solution refusée et adaptation du pas
h = max(0.8 * h, hmin)
else:
# Solution acceptée
tt.append(t + h)
uu.append(u_fi)
# Adaptation du pas
if err < tol / 3:
h = min(1.25 * h, hmax)
# sinon h inchangé
return np.array(tt), np.array(uu)
# ================================
# MAIN
# ================================
t0, tfinal = 0, 2
y0 = 0
phi = lambda t,y : 1+y
sol_exacte = lambda t : np.exp(t)-1
# ================================
# Comparaison des méthodes
# ================================
plt.figure(figsize=(15,5))
# exacte
tt_ex = np.linspace(t0,tfinal,101)
yy = sol_exacte(tt_ex)
plt.plot(tt_ex, yy, 'r',label=r'Exacte')
plt.xlabel('t')
plt.ylabel('y(t)')
# Pas fixe h
tt = np.linspace(t0,tfinal,11)
h_init = tt[1]-tt[0]
uu_EE = EE(phi, tt, y0)
plt.plot(tt,uu_EE, 'x', label='EE avec h')
# Pas fixe h/2
tt2 = np.linspace(t0,tfinal,21)
uu_EE2 = EE(phi, tt2, y0)
plt.plot(tt2,uu_EE2, 'd', label='EE avec h/2')
# Pas adaptatif
tol = h_init/2
tt_adapt, uu_adapt = Adaptatif_EE(phi, t0, tfinal, y0, tol=tol, hinit=h_init, hmin=h_init/10, hmax=4*h_init)
plt.plot(tt_adapt,uu_adapt, 'o', label='Adaptatif_EE')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0.)
plt.grid();
# ================================
# Graphe de comparaison des erreurs
# ================================
err_EE = np.abs(uu_EE - sol_exacte(tt))
err_EE2 = np.abs(uu_EE2 - sol_exacte(tt2))
err_adapt = np.abs(uu_adapt - sol_exacte(tt_adapt))
plt.figure(figsize=(15,5))
plt.plot(tt, err_EE, 'x-', label='Erreur EE (h)')
plt.plot(tt2, err_EE2, 'd-', label='Erreur EE (h/2)')
plt.plot(tt_adapt, err_adapt, 'o-', label='Erreur Adaptatif')
plt.xlabel("t_n")
plt.ylabel(r"$|u(t_n)-y(t_n)|$")
plt.title("Comparaison des erreurs en fonction du temps")
plt.grid(True, which="both")
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
plt.show()
# ================================
# Comparaison des grilles
# ================================
plt.figure(figsize=(15,5))
plt.plot(tt,np.ones_like(tt)*3,'x',label='Grille grossière')
plt.plot(tt2,np.ones_like(tt2)*2,'d',label='Grille fine')
plt.plot(tt_adapt,np.ones_like(tt_adapt),'o',label='Grille adaptative')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0.)
plt.ylim(0,4)
plt.xlabel('t')
plt.xticks(tt2)
plt.yticks([1,2,3], ['Adaptative','Fine','Grossière'])
plt.grid()
plt.show()
# ================================================================
# Évolution du pas adaptatif
# ================================================================
plt.figure(figsize=(8,5))
plt.plot(tt_adapt[1:], np.diff(tt_adapt), 'o-')
plt.xlabel("$t$")
plt.ylabel("$h$")
plt.title("Évolution du pas adaptatif")
plt.grid(True)
plt.show()
# ================================================================
# Comparaison des approximations en t=tfinal
# ================================================================
from tabulate import tabulate
tab = []
headers = ["Méthode", "t final", "|u(t final) - sol_exacte(tfinal)|", "Points de grille"]
tab.append(["EE avec h", tt[-1], abs(uu_EE[-1]-sol_exacte(tt[-1])), len(tt)])
tab.append(["EE avec h/2", tt2[-1], abs(uu_EE2[-1]-sol_exacte(tt2[-1])), len(tt2)])
idx = np.argmax(tt_adapt>tfinal)-1
tab.append(["Adaptatif_EE", tt_adapt[idx], abs(uu_adapt[idx]-sol_exacte(tt_adapt[idx])), len(tt_adapt)])
# tab.append(["Exacte", tfinal, sol_exacte(tfinal), ""])
display(tabulate(tab, headers=headers, tablefmt="html", floatfmt=".2e"))
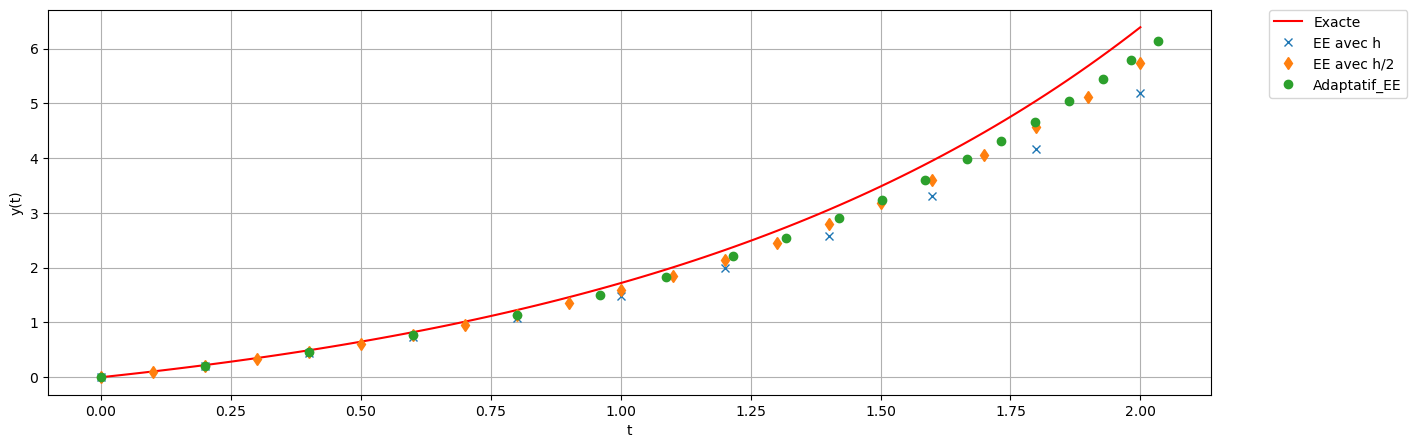
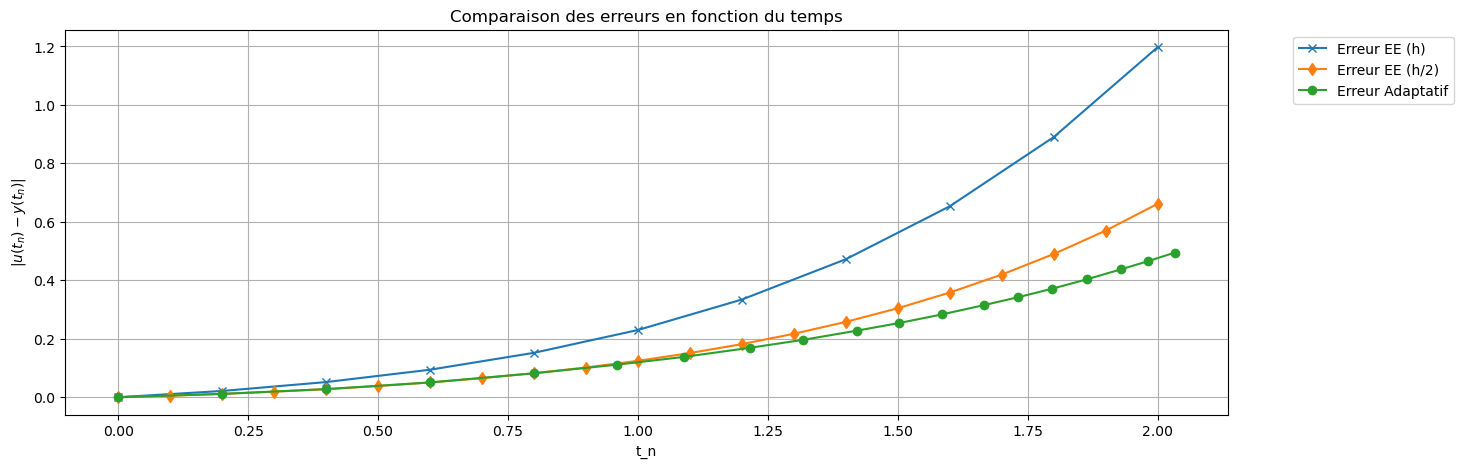
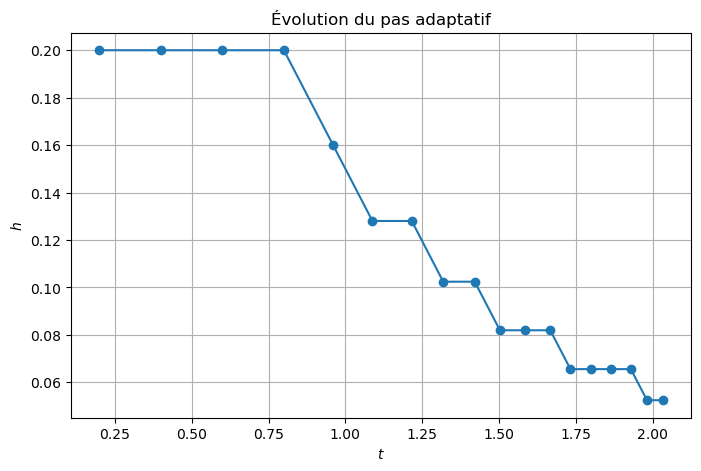
| Méthode | t final | |u(t final) - sol_exacte(tfinal)| | Points de grille |
|---|---|---|---|
| EE avec h | 2.00e+00 | 1.20e+00 | 11 |
| EE avec h/2 | 2.00e+00 | 6.62e-01 | 21 |
| Adaptatif_EE | 1.98e+00 | 4.65e-01 | 19 |
Tout comme la méthode d’Euler explicite, les méthodes RK étant à un pas se prêtent bien aux techniques d’adaptation. On peut construire leur estimateur d’erreur de deux manières :
La méthode de Runge-Kutta emboîtée utilise cette deuxième approche. L’intérêt de ces deux formules emboîtées est de permettre une estimation de l’erreur locale facilement calculable : \( \varepsilon_{n+1} = \left| u_{n+1} - \hat u_{n+1} \right| = h \left| \sum_{i=1}^s (b_i - \hat b_i) K_i \right| \)
La méthode de Runge-Kutta adaptative la plus simple implique de combiner la méthode de Heun, d’ordre 2, avec la méthode d’Euler explicite, d’ordre 1. Son tableau de Butcher étendu est le suivant : \( \begin{array}{c|cc} 0 & 0 & 0 \\ 1 & 1 & 0 \\ \hline \text{(Heun)}& \frac{1}{2} & \frac{1}{2}\\ \text{(EE)}& 1 & 0 \end{array} \)
def EE( phi, tt, y0 ):
h = tt[1]-tt[0]
uu = np.empty_like(tt)
uu[0] = y0
for n in range(len(tt)-1):
k0 = phi(tt[n],uu[n])
k1 = phi(tt[n]+h,uu[n]+h*k0)
uu[n+1] = uu[n]+h*(1*k0+0*k1)
return uu
def HEUN( phi, tt, y0 ):
h = tt[1]-tt[0]
uu = np.empty_like(tt)
uu[0] = y0
for n in range(len(tt)-1):
k0 = phi(tt[n],uu[n])
k1 = phi(tt[n]+h,uu[n]+h*k0)
uu[n+1] = uu[n]+h*(1/2*k0+1/2*k1)
return uu
def RK12( phi, t0, tfinal, y0, tol, hinit, hmin, hmax ):
tt = np.array([t0])
uu = np.array([y0])
uu[0] = y0
h = hinit
n = 0
while tt[n]<tfinal:
k0 = phi(tt[n],uu[n])
k1 = phi(tt[n]+h,uu[n]+h*k0)
# Un pas de EE
# uu_om = uu[n]+h*(1*k0+0*k1)
# Un pas de HEUN
uu_om_p1 = uu[n]+h*(1/2*k0+1/2*k1)
# choix
err = (-1/2*k0+1/2*k1)*h
if err > tol:
# Solution refusée et adaptation du pas
h = max( 0.8*h, hmin )
else:
# Solution acceptée
tt = np.append(tt,tt[n]+h)
uu = np.append(uu,uu_om_p1)
n = n+1
# Adaptation du pas
if err < tol / 3:
h = min( 1.25*h, hmax )
# sinon h inchangé
if tt[n]+h>tfinal: h = tfinal-tt[n]
return tt,uu
# ================================
# MAIN
# ================================
t0, tfinal = 0, np.pi/2-0.1
y0 = 0
phi = lambda t,y : 1+y**2
sol_exacte = lambda t : np.tan(t)
# ================================
# Comparaison des méthodes
# ================================
plt.figure(figsize=(15,5))
# exacte
tt_ex = np.linspace(t0,tfinal,101)
yy = sol_exacte(tt_ex)
plt.plot(tt_ex, yy, 'r',label=r'$\tan(t)$')
# Pas fixe h
tt = np.linspace(t0,tfinal,11)
h_init = tt[1]-tt[0]
# EE
uu_EE = EE(phi, tt, y0)
plt.plot(tt,uu_EE, 'x', label='EE')
# HEUN
uu_HEUN = HEUN(phi, tt, y0)
plt.plot(tt,uu_HEUN, 'd', label='HEUN')
# Pas adaptatif
toll = 1.e-1
h_min = h_init/10
h_max = 4*h_init
tt_adapt, uu_adapt = RK12(phi, t0, tfinal, y0, tol=toll, hinit=h_init, hmin=h_min, hmax=h_max)
plt.plot(tt_adapt,uu_adapt, 'o', label='Adaptatif_EE')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0.)
plt.xlabel('$t$')
plt.ylabel('$y(t)$')
plt.grid();
# ================================
# Graphe de comparaison des erreurs
# ================================
err_EE = np.abs(uu_EE - sol_exacte(tt))
err_HEUN = np.abs(uu_HEUN - sol_exacte(tt))
err_adapt = np.abs(uu_adapt - sol_exacte(tt_adapt))
plt.figure(figsize=(15,5))
plt.plot(tt, err_EE, 'x-', label='Erreur EE')
plt.plot(tt, err_HEUN, 'd-', label='Erreur HEUN')
plt.plot(tt_adapt, err_adapt, 'o-', label='Erreur Adaptatif')
plt.xlabel("$t_n$")
plt.ylabel(r"$|u(t_n)-y(t_n)|$")
plt.title("Comparaison des erreurs en fonction du temps")
plt.grid(True, which="both")
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
plt.show()
# ================================
# Comparaison des grilles
# ================================
plt.figure(figsize=(15,5))
plt.plot(tt,np.ones_like(tt)*2,'x',label='Grille fixe')
plt.plot(tt_adapt,np.ones_like(tt_adapt),'o',label='Grille adaptative')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0.)
plt.ylim(0,3)
plt.xticks(tt)
plt.xlabel('$t$')
plt.yticks([1,2], ['Adaptative','Fixe'])
plt.grid()
plt.show()
# ================================================================
# Évolution du pas adaptatif
# ================================================================
plt.figure(figsize=(8,5))
plt.plot(tt_adapt[1:], np.diff(tt_adapt), 'o-')
plt.xlabel("$t$")
plt.ylabel("$h$")
plt.title("Évolution du pas adaptatif")
plt.grid(True)
plt.show()
# ================================================================
# Comparaison des approximations en t=tfinal
# ================================================================
from tabulate import tabulate
tab = []
headers = ["Méthode", "t final", "|u(t final)-exacte(tfinal)|", "Points de grille"]
tab.append(["EE", tt[-1], abs(uu_EE[-1]-sol_exacte(tfinal)), len(tt)])
tab.append(["HEUN", tt[-1], abs(uu_HEUN[-1]-sol_exacte(tfinal)), len(tt)])
idx = np.argmax(tt_adapt>tfinal)-1
tab.append(["RK12", tt_adapt[idx], abs(uu_adapt[idx]-sol_exacte(tfinal)), len(tt_adapt)])
display(tabulate(tab, headers=headers, tablefmt="html", floatfmt=".2e"))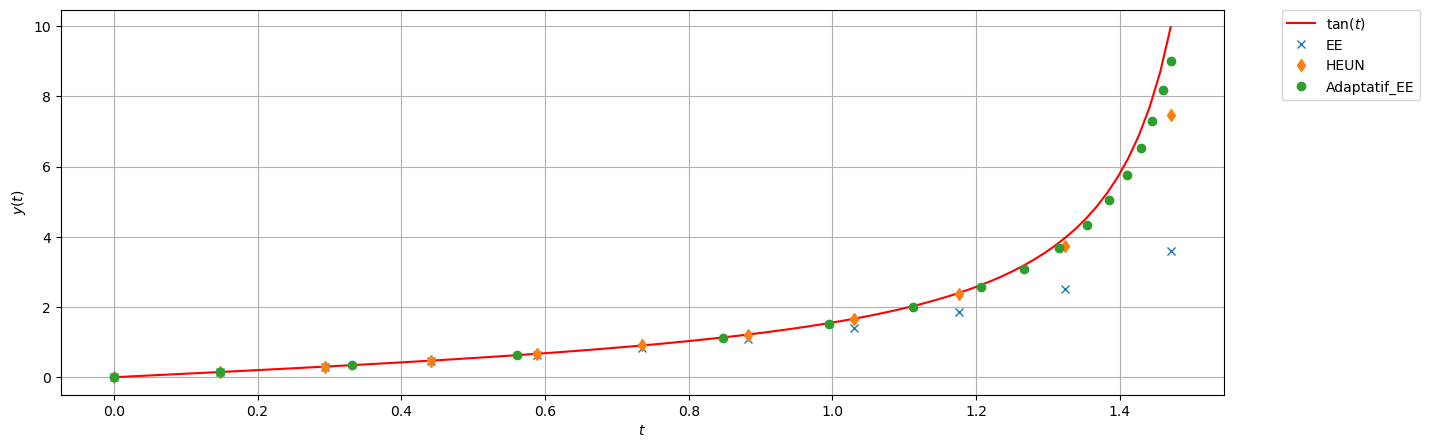
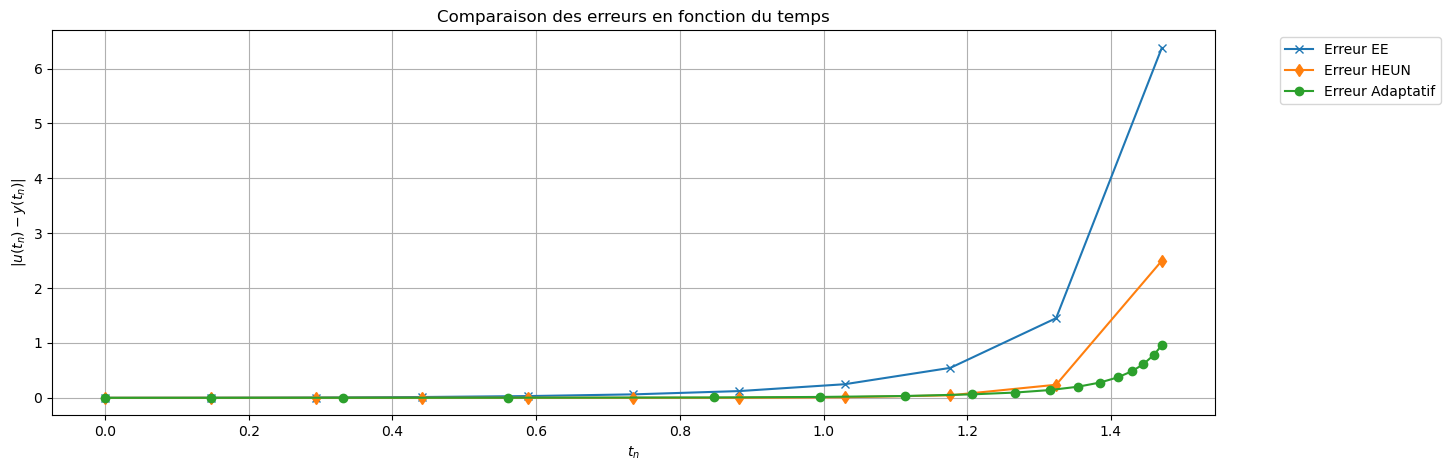
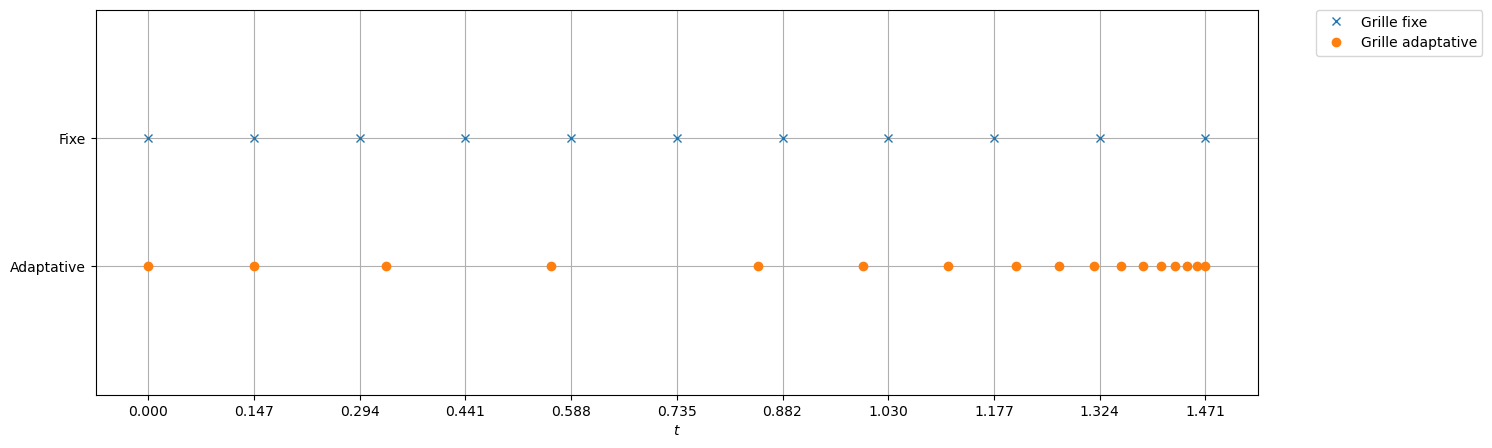
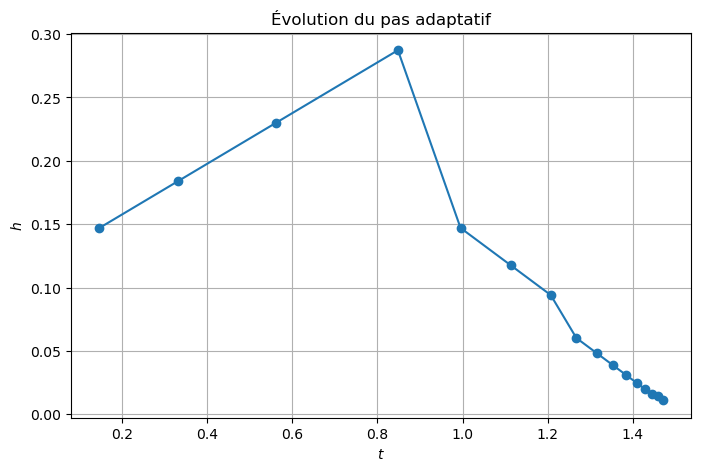
| Méthode | t final | |u(t final)-exacte(tfinal)| | Points de grille |
|---|---|---|---|
| EE | 1.47e+00 | 6.38e+00 | 11 |
| HEUN | 1.47e+00 | 2.50e+00 | 11 |
| RK12 | 1.47e+00 | 9.59e-01 | 17 |
Une méthode de Runge-Kutta adaptative simple combine la méthode de Heun, d’ordre 2, avec la méthode de Simpso, d’ordre 3. Son tableau de Butcher étendu est le suivant : \( \begin{array}{c|ccc} 0 & 0 & 0 & 0\\ 1 & 1 & 0 & 0 \\ \frac{1}{2} & \frac{1}{4} & \frac{1}{4} & 0\\ \hline \text{(Heun)}& \frac{1}{2} & \frac{1}{2} & 0\\ \text{(Simpson)}& \frac{1}{6} & \frac{1}{6} & \frac{4}{6} \end{array} \)
def coeff_K(phi, h, t, u):
k0 = phi(t,u)
k1 = phi(t+h,u+h*k0)
k2 = phi(t+h/2,u+h/4*k0+h/4*k1)
return k0, k1, k2
def HEUN( phi, tt, y0 ):
h = tt[1]-tt[0]
uu = np.empty_like(tt)
uu[0] = y0
for n in range(len(tt)-1):
k0, k1, k2 = coeff_K(phi, h, tt[n], uu[n])
uu[n+1] = uu[n]+h*(1/2*k0+1/2*k1)
return uu
def SIMPSON( phi, tt, y0 ):
h = tt[1]-tt[0]
uu = np.empty_like(tt)
uu[0] = y0
for n in range(len(tt)-1):
k0, k1, k2 = coeff_K(phi, h, tt[n], uu[n])
uu[n+1] = uu[n]+h*(1/6*k0+4/6*k2+1/6*k1)
return uu
def RK23( phi, t0, tfinal, y0, tol, hinit, hmin, hmax ):
tt = np.array([t0])
uu = np.array([y0])
uu[0] = y0
h = hinit
n = 0
while tt[n]<tfinal :
k0, k1, k2 = coeff_K(phi, h, tt[n], uu[n])
# Un pas de Heun
# uu_om = uu[n]+h*(1/2*k0+1/2*k1)
# Un pas de Simpson
uu_om_p1 = uu[n]+h*(1/6*k0+1/6*k1+4/6*k2)
# choix
err = h * ( (1/6-1/2)*k0 + (1/6-1/2)*k1 + (4/6-0)*k2 )
if err > tol:
# Solution refusée et adaptation du pas
h = max( 0.8*h, hmin )
else:
# Solution acceptée
tt = np.append(tt,tt[n]+h)
uu = np.append(uu,uu_om_p1)
n = n+1
# Adaptation du pas
if err < tol / 3:
h = min( 1.25*h, hmax )
# sinon h inchangé
if tt[n]+h>tfinal: h = tfinal-tt[n]
return tt,uu
# ================================
# MAIN
# ================================
t0, tfinal = 0, np.pi/2-0.1
y0 = 0
phi = lambda t,y : 1+y**2
sol_exacte = lambda t : np.tan(t)
# ================================
# Comparaison des méthodes
# ================================
plt.figure(figsize=(15,5))
# exacte
tt_ex = np.linspace(t0,tfinal,101)
yy = sol_exacte(tt_ex)
plt.plot(tt_ex, yy, 'r',label=r'$\tan(t)$')
# Pas fixe h
tt = np.linspace(t0,tfinal,11)
h_init = tt[1]-tt[0]
# HEUN
uu_HEUN = HEUN(phi, tt, y0)
plt.plot(tt,uu_HEUN, 'x', label='HEUN')
# SIMPSON
uu_SIMPSON = SIMPSON(phi, tt, y0)
plt.plot(tt,uu_SIMPSON, 'd', label='SIMPSON')
# Pas adaptatif
tt_adapt, uu_adapt = RK23(phi, t0, tfinal, y0, tol=1.e-1, hinit=h_init, hmin=1e-3, hmax=4*h_init)
plt.plot(tt_adapt,uu_adapt, 'o', label='Adaptatif')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0.)
plt.grid();
# ================================
# Graphe de comparaison des erreurs
# ================================
err_HEUN = np.abs(uu_HEUN - sol_exacte(tt))
err_SIMPSON = np.abs(uu_SIMPSON - sol_exacte(tt))
err_adapt = np.abs(uu_adapt - sol_exacte(tt_adapt))
plt.figure(figsize=(15,5))
plt.plot(tt, err_HEUN, 'x-', label='Erreur HEUN')
plt.plot(tt, err_SIMPSON, 'd-', label='Erreur SIMPSON')
plt.plot(tt_adapt, err_adapt, 'o-', label='Erreur Adaptatif')
plt.xlabel("$t_n$")
plt.ylabel(r"$|u(t_n)-y(t_n)|$")
plt.title("Comparaison des erreurs en fonction du temps")
plt.grid(True, which="both")
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
plt.show()
# ================================
# Comparaison des grilles
# ================================
plt.figure(figsize=(15,5))
plt.plot(tt,np.ones_like(tt)*2,'x',label='Grille fixe')
plt.plot(tt_adapt,np.ones_like(tt_adapt),'o',label='Grille adaptative')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0.)
plt.ylim(0,3);
plt.xticks(tt)
plt.grid()
plt.show()
# ================================================================
# Évolution du pas adaptatif
# ================================================================
plt.figure(figsize=(8,5))
plt.plot(tt_adapt[1:], np.diff(tt_adapt), 'o-')
plt.xlabel("$t$")
plt.ylabel("$h$")
plt.title("Évolution du pas adaptatif")
plt.grid(True)
plt.show()
# ================================================================
# Comparaison des approximations en t=tfinal
# ================================================================
from tabulate import tabulate
tab = []
headers = ["Méthode", "t final", "|u(t final)-exacte(tfinal)|", "Points de grille"]
tab.append(["HEUN", tt[-1], abs(uu_HEUN[-1]-sol_exacte(tfinal)), len(tt)])
tab.append(["SIMPSON", tt[-1], abs(uu_SIMPSON[-1]-sol_exacte(tfinal)), len(tt)])
idx = np.argmax(tt_adapt>tfinal)-1
tab.append(["RK23", tt_adapt[idx], abs(uu_adapt[idx]-sol_exacte(tt_adapt[idx])), len(tt_adapt)])
display(tabulate(tab, headers=headers, tablefmt="html", floatfmt=".2e"))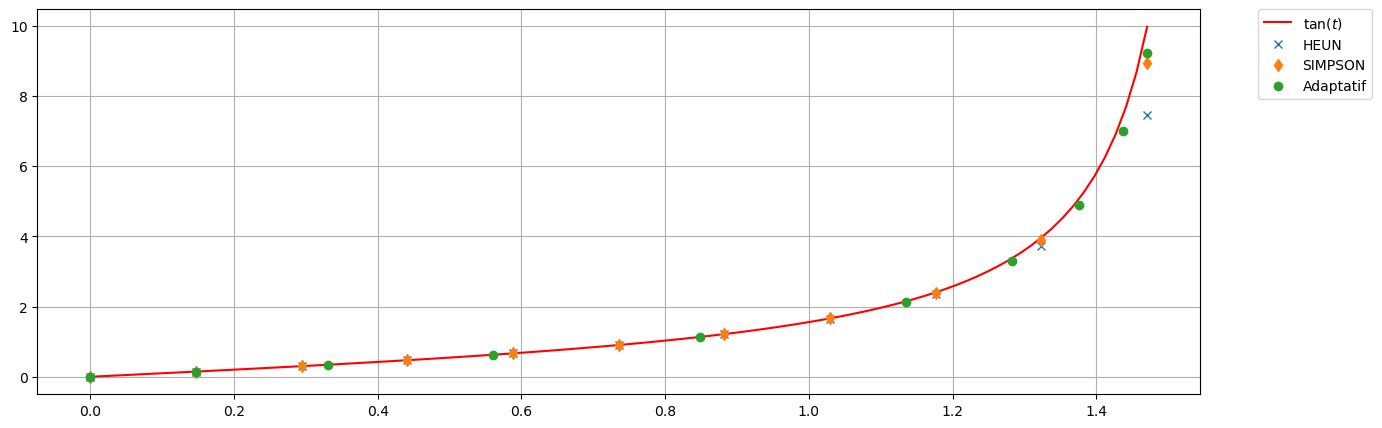
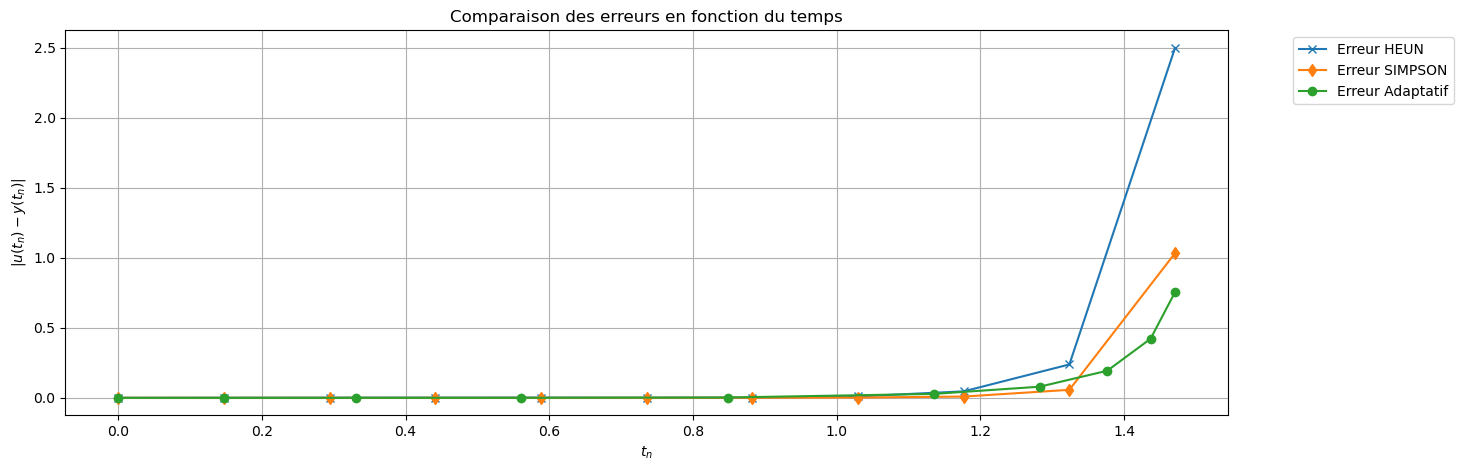
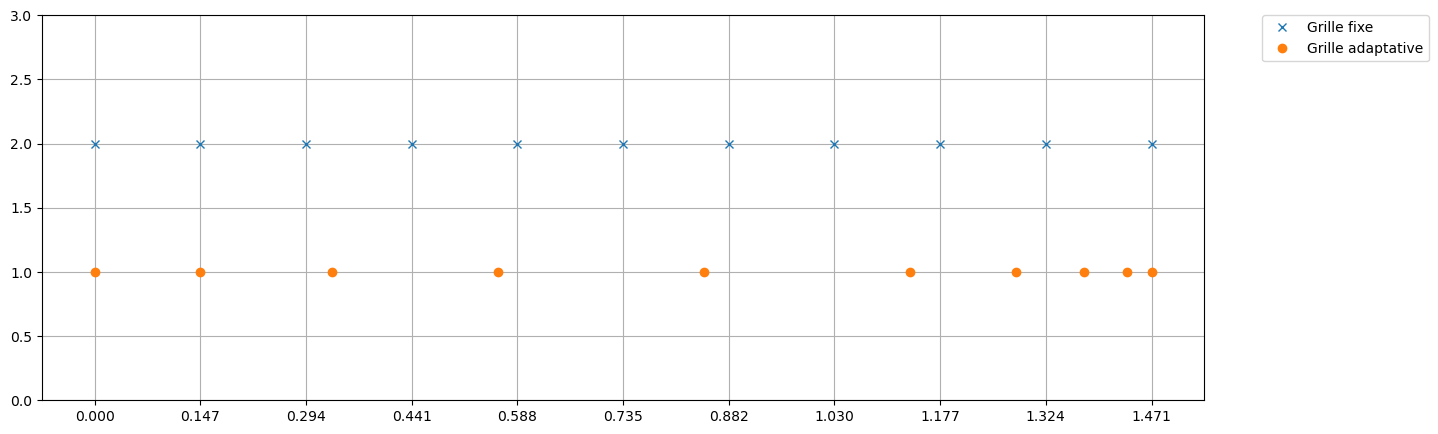
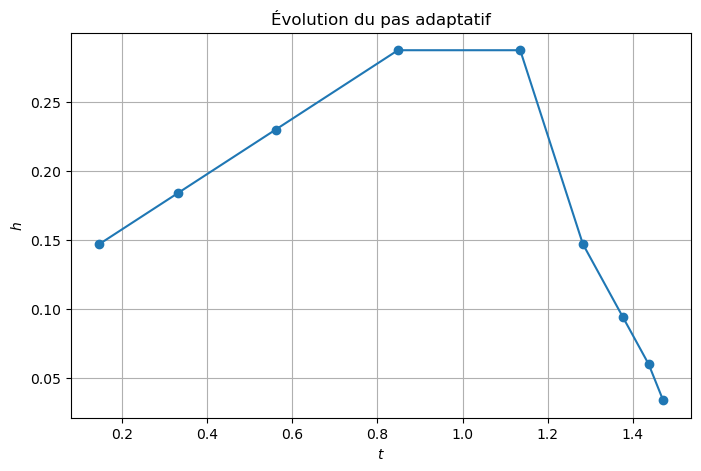
| Méthode | t final | |u(t final)-exacte(tfinal)| | Points de grille |
|---|---|---|---|
| HEUN | 1.47e+00 | 2.50e+00 | 11 |
| SIMPSON | 1.47e+00 | 1.03e+00 | 11 |
| RK23 | 1.47e+00 | 7.55e-01 | 10 |
Une méthode de Runge-Kutta adaptative souvent utilisée combine la méthode de Bogacki avec celle de Shampine. Son tableau de Butcher étendu est le suivant : \( \begin{array}{c|cccc} 0 & 0 & 0 & 0 & 0\\ \frac{1}{2} & \frac{1}{2} & 0 & 0 & 0\\ \frac{3}{4} & 0 & \frac{3}{4} & 0 & 0\\ 1 & \frac{2}{9} & \frac{1}{3} & \frac{4}{9} & 0\\ \hline & \frac{2}{9} & \frac{1}{3} & \frac{4}{9} & 0 \\ & \frac{7}{24} & \frac{1}{4} & \frac{1}{3} & \frac{1}{8} \end{array} \)
def coeff_K(phi, h, t, u):
k0 = phi(t,u)
k1 = phi(t+h/2,u+h/2*k0)
k2 = phi(t+h*3/4,u+h*3/4*k1)
k3 = phi(t+h,u+h*2/9*k0+h/3*k1+h*4/9*k2)
return k0, k1, k2, k3
def Bogacki( phi, tt, y0 ):
h = tt[1]-tt[0]
uu = np.empty_like(tt)
uu[0] = y0
for n in range(len(tt)-1):
k0, k1, k2, k3 = coeff_K(phi, h, tt[n], uu[n])
uu[n+1] = uu[n]+h*(2/9*k0+1/3*k1+4/9*k2)
return uu
def Shampine( phi, tt, y0 ):
h = tt[1]-tt[0]
uu = np.empty_like(tt)
uu[0] = y0
for n in range(len(tt)-1):
k0, k1, k2, k3 = coeff_K(phi, h, tt[n], uu[n])
uu[n+1] = uu[n]+h*(7/24*k0+1/4*k1+1/3*k2+1/8*k3)
return uu
def edo23( phi, t0, tfinal, y0, tol, hinit, hmin, hmax ):
tt = np.array([t0])
uu = np.array([y0])
uu[0] = y0
h = hinit
n = 0
while tt[n]<tfinal :
k0, k1, k2, k3 = coeff_K(phi, h, tt[n], uu[n])
# Un pas de Bogacki
# uu_om = uu[n]+h*(2/9*k0+1/3*k1+4/9*k2)
# Un pas de Shamphine
uu_om_p1 = uu[n]+h*(7/24*k0+1/4*k1+1/3*k2+1/8*k3)
# choix
err = h * ( (7/24-2/9)*k0 + (1/4-1/3)*k1 + (1/3-4/9)*k2 + (1/8-0)*k3 )
if err > tol:
# Solution refusée et adaptation du pas
h = max( 0.7*h, hmin )
else:
# Solution acceptée
tt = np.append(tt,tt[n]+h)
uu = np.append(uu,uu_om_p1)
n = n+1
# Adaptation du pas
if err < tol/4:
h = min( 1.2*h, hmax )
# sinon h inchangé
if tt[n]+h>tfinal: h = tfinal-tt[n]
return tt,uu
# ================================
# MAIN
# ================================
t0, tfinal = 0, np.pi/2-0.1
y0 = 0
phi = lambda t,y : 1+y**2
sol_exacte = lambda t : np.tan(t)
# ================================
# Comparaison des méthodes
# ================================
plt.figure(figsize=(15,5))
# exacte
tt_ex = np.linspace(t0,tfinal,21)
yy = sol_exacte(tt_ex)
plt.plot(tt_ex, yy, 'r',label=r'$\tan(t)$')
# Pas fixe h
tt = np.linspace(t0,tfinal,21)
h_init = tt[1]-tt[0]
# Bogacki
uu_Bogacki = Bogacki(phi, tt, y0)
plt.plot(tt,uu_Bogacki, 'x', label='Bogacki')
# Shampine
uu_Shampine = Shampine(phi, tt, y0)
plt.plot(tt,uu_Shampine, 'd', label='Shampine')
# Pas adaptatif
tt_adapt, uu_adapt = edo23(phi, t0, tfinal, y0, tol=1.e-3, hinit=h_init, hmin=1e-3, hmax=4*h_init)
plt.plot(tt_adapt,uu_adapt, 'o', label='Adaptatif')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0.)
plt.grid();
# ================================
# Graphe de comparaison des erreurs
# ================================
err_Bogacki = np.abs(uu_Bogacki - sol_exacte(tt))
err_Shampine = np.abs(uu_Shampine - sol_exacte(tt))
err_adapt = np.abs(uu_adapt - sol_exacte(tt_adapt))
plt.figure(figsize=(15,5))
plt.plot(tt, err_Bogacki, 'x-', label='Erreur Bogacki')
plt.plot(tt, err_Shampine, 'd-', label='Erreur Shampine')
plt.plot(tt_adapt, err_adapt, 'o-', label='Erreur Adaptatif')
plt.xlabel("$t_n$")
plt.ylabel(r"$|u(t_n)-y(t_n)|$")
plt.title("Comparaison des erreurs en fonction du temps")
plt.grid(True, which="both")
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
plt.show()
# ================================
# Comparaison des grilles
# ================================
plt.figure(figsize=(15,5))
plt.plot(tt,np.ones_like(tt)*2,'x',label='Grille fixe')
plt.plot(tt_adapt,np.ones_like(tt_adapt),'o',label='Grille adaptative')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0.)
plt.ylim(0,3);
plt.xticks(tt)
plt.grid()
plt.show()
# ================================================================
# Évolution du pas adaptatif
# ================================================================
plt.figure(figsize=(8,5))
plt.plot(tt_adapt[1:], np.diff(tt_adapt), 'o-')
plt.xlabel("$t$")
plt.ylabel("$h$")
plt.title("Évolution du pas adaptatif")
plt.grid(True)
plt.show()
# ================================================================
# Comparaison des approximations en t=tfinal
# ================================================================
from tabulate import tabulate
tab = []
headers = ["Méthode", "t final", "|u(t final)-exacte(tfinal)|", "Points de grille"]
tab.append(["Bogacki", tt[-1], abs(uu_Bogacki[-1]-sol_exacte(tfinal)), len(tt)])
tab.append(["Shampine", tt[-1], abs(uu_Shampine[-1]-sol_exacte(tfinal)), len(tt)])
idx = np.argmax(tt_adapt>tfinal)-1
tab.append(["edo23", tt_adapt[idx], abs(uu_adapt[idx]-sol_exacte(tt_adapt[idx])), len(tt_adapt)])
display(tabulate(tab, headers=headers, tablefmt="html", floatfmt=".2e"))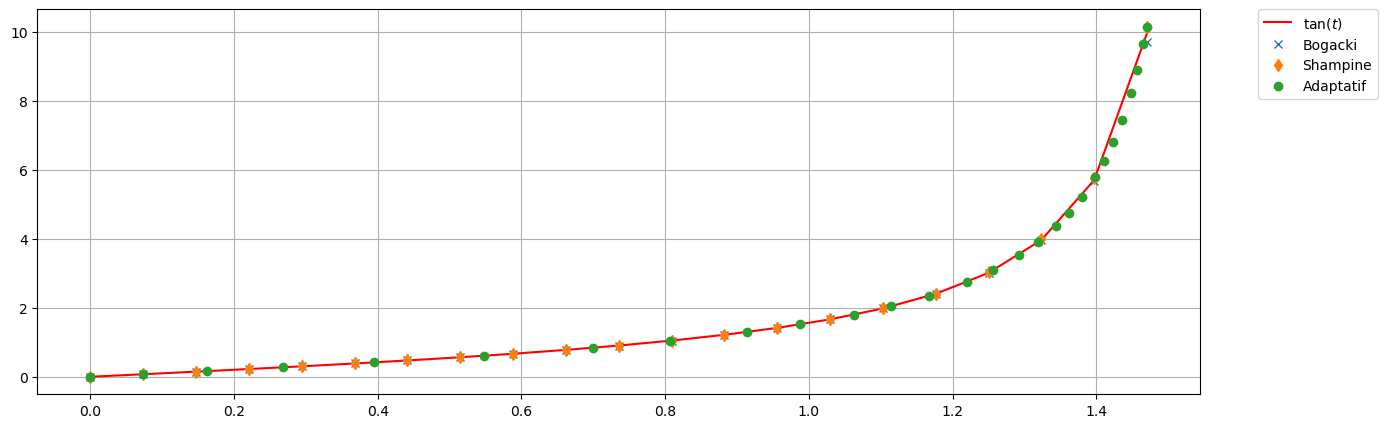
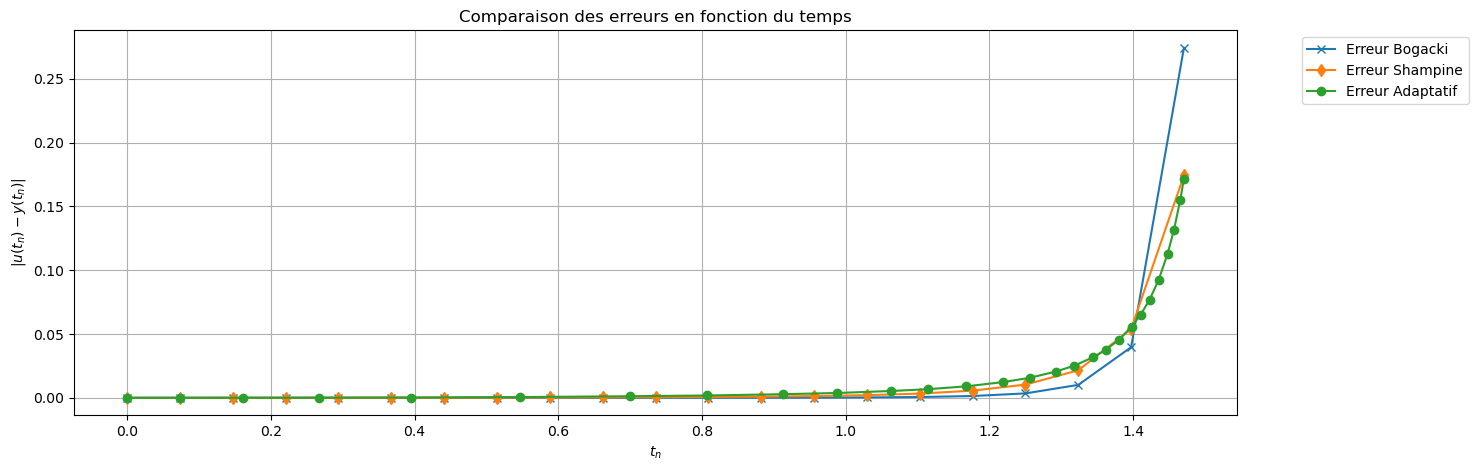
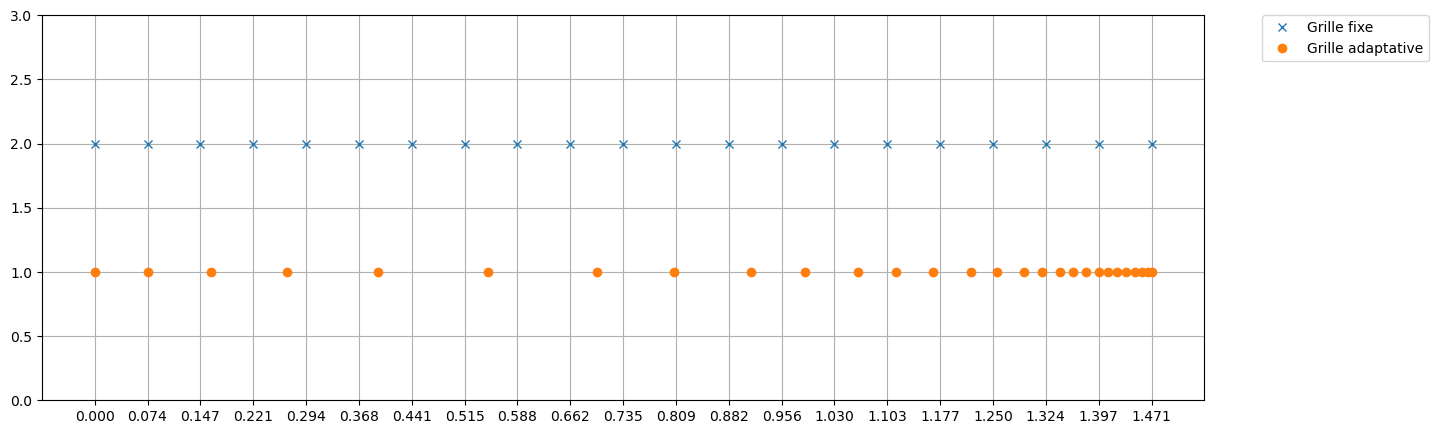
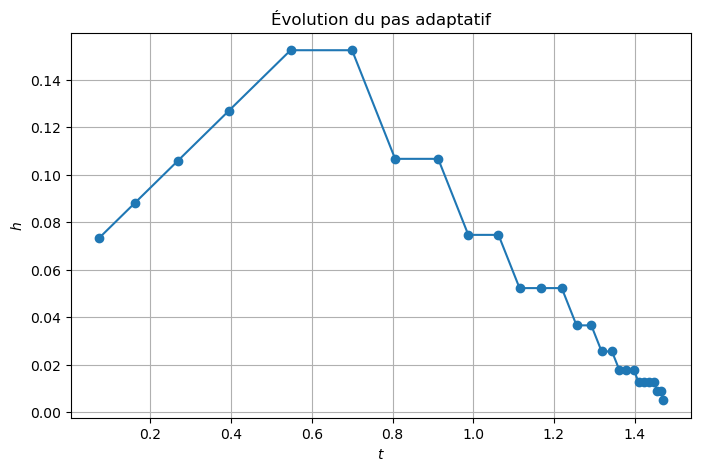
| Méthode | t final | |u(t final)-exacte(tfinal)| | Points de grille |
|---|---|---|---|
| Bogacki | 1.47e+00 | 2.74e-01 | 21 |
| Shampine | 1.47e+00 | 1.74e-01 | 21 |
| edo23 | 1.47e+00 | 1.72e-01 | 28 |
Voici la matrice de Butcher associée à la méthode de Runge-Kutta-Fehlberg (RKF45). Ce tableau représente les coefficients des deux méthodes Runge-Kutta utilisées dans la méthode RK45 pour calculer les coefficients \(k_0\) à \(k_5\), ainsi que les coefficients \(b_0\) à \(b_5\) et \(\hat b_0\) à \(\hat b_5\) utilisés pour combiner les \(K_i\) afin d’obtenir une approximation à l’étape suivante. \( \begin{array}{c|cccccc} 0 & & & & & & \\ \frac{1}{4} & \frac{1}{4} & & & & & \\ \frac{3}{8} & \frac{3}{32} & \frac{9}{32} & & & & \\ \frac{12}{13} & \frac{1932}{2197} & -\frac{7200}{2197} & \frac{7296}{2197} & & & \\ 1 & \frac{439}{216} & -\frac{8}{27} & \frac{3680}{513} & -\frac{845}{4104} & & \\ \frac{1}{2} & -\frac{8}{27} & \frac{2}{9} & -\frac{3544}{2565} & \frac{1859}{4104} & -\frac{11}{40} & \\ \hline & \frac{16}{135} & 0 & \frac{6656}{12825} & \frac{28561}{56430} & -\frac{9}{50} & \frac{2}{55} \\ & \frac{25}{216} & 0 & \frac{1408}{2565} & \frac{2197}{4104} & -\frac{1}{5} & 0 \\ \end{array} \)
Voyons un exemple d’implémentation de la méthode de Runge-Kutta-Fehlberg (RKF45) à pas adaptatif.
def coeff_K(phi, h, t, u):
k = np.zeros(6)
k[0] = phi(t,u)
k[1] = phi(t+h/4,u+h/4*k[0])
k[2] = phi(t+3*h/8,u+3*h/32*k[0]+9*h/32*k[1])
k[3] = phi(t+12*h/13,u+1932*h/2197*k[0]-7200*h/2197*k[1]+7296*h/2197*k[2])
k[4] = phi(t+h,u+439*h/216*k[0]-8*h*k[1]+3680*h/513*k[2]-845*h/4104*k[3])
k[5] = phi(t+h/2,u-8*h/27*k[0]+2*h*k[1]-3544*h/2565*k[2]+1859*h/4104*k[3]-11*h/40*k[4])
return k
def RK4( phi, tt, y0 ):
h = tt[1]-tt[0]
uu = np.empty_like(tt)
uu[0] = y0
for n in range(len(tt)-1):
kk = coeff_K(phi, h, tt[n], uu[n])
uu[n+1] = uu[n] + h*( 25/216*kk[0] + 1408/2565*kk[2] + 2197/4104*kk[3] - 1/5*kk[4] )
return uu
def RK5( phi, tt, y0 ):
h = tt[1]-tt[0]
uu = np.empty_like(tt)
uu[0] = y0
for n in range(len(tt)-1):
kk = coeff_K(phi, h, tt[n], uu[n])
uu[n+1] = uu[n] + h* ( 16/135*kk[0] + 6656/12825*kk[2] + 28561/56430*kk[3] -9/50*kk[4] + 2/55*kk[5] )
return uu
def RK45( phi, t0, tfinal, y0, tol, hinit, hmin, hmax ):
tt = np.array([t0])
uu = np.array([y0])
uu[0] = y0
h = hinit
n = 0
while tt[n]<tfinal:
kk = coeff_K(phi, h, tt[n], uu[n])
# Un pas de RK5
uu_om_p1 = uu[n] + h* ( 16/135*kk[0] + 6656/12825*kk[2] + 28561/56430*kk[3] -9/50*kk[4] + 2/55*kk[5] )
# choix
err = h*( (25/216-16/135)*kk[0] +
(1408/2565-6656/12825)*kk[2] +
(2197/4104-28561/56430)*kk[3] +
(-1/5+9/50)*kk[4] +(0-2/55)*kk[5] )
if err > tol:
# Solution refusée et adaptation du pas
h = max( 0.8*h, hmin )
else:
# Solution acceptée
tt = np.append(tt,tt[n]+h)
uu = np.append(uu,uu_om_p1)
n = n+1
# Adaptation du pas
if err < tol / 3:
h = min( 1.25*h, hmax )
# sinon h inchangé
if tt[n]+h>tfinal: h = tfinal-tt[n]
return tt,uu
# ================================
# MAIN
# ================================
t0, tfinal = 0, 4
y0 = 1
phi = lambda t,y : y*(2-y)
import sympy as sp
t = sp.symbols('t')
y = sp.Function('y')
sol_par = sp.dsolve( sp.Eq(y(t).diff(t), phi(t,y(t)) ) , ics={y(t0): y0} )
display(sol_par)
sol_exacte = sp.lambdify(t,sol_par.rhs,'numpy')
# ================================
# Comparaison des méthodes
# ================================
plt.figure(figsize=(15,5))
# exacte
tt_ex = np.linspace(t0,tfinal,101)
yy = sol_exacte(tt_ex)
plt.plot(tt_ex, yy, 'r',label=r'Exacte')
# Pas fixe h
tt = np.linspace(t0,tfinal,6)
h_init = tt[1]-tt[0]
# RK4
uu_RK4 = RK4(phi, tt, y0)
plt.plot(tt,uu_RK4, 'x', label='RK4')
# RK5
uu_RK5 = RK5(phi, tt, y0)
plt.plot(tt,uu_RK5, 'd', label='RK5')
# Pas adaptatif
tt_adapt, uu_adapt = RK45(phi, t0, tfinal, y0, tol=1.e-5, hinit=h_init, hmin=5e-3, hmax=4*h_init)
plt.plot(tt_adapt,uu_adapt, 'o', label='Adaptatif')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0.)
plt.grid();
# ================================
# Graphe de comparaison des erreurs
# ================================
err_RK4 = np.abs(uu_RK4 - sol_exacte(tt))
err_RK5 = np.abs(uu_RK5 - sol_exacte(tt))
err_adapt = np.abs(uu_adapt - sol_exacte(tt_adapt))
plt.figure(figsize=(15,5))
plt.plot(tt, err_RK4, 'x-', label='Erreur RK4')
plt.plot(tt, err_RK5, 'd-', label='Erreur RK5')
plt.plot(tt_adapt, err_adapt, 'o-', label='Erreur Adaptatif')
plt.xlabel("$t_n$")
plt.ylabel(r"$|u(t_n)-y(t_n)|$")
plt.title("Comparaison des erreurs en fonction du temps")
plt.grid(True, which="both")
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
plt.show()
# ================================
# Comparaison des grilles
# ================================
plt.figure(figsize=(15,5))
plt.plot(tt,np.ones_like(tt)*2,'x',label='Grille fixe')
plt.plot(tt_adapt,np.ones_like(tt_adapt),'o',label='Grille adaptative')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0.)
plt.ylim(0,3);
plt.xticks(tt)
plt.grid()
plt.show()
# ================================================================
# Évolution du pas adaptatif
# ================================================================
plt.figure(figsize=(8,5))
plt.plot(tt_adapt[1:], np.diff(tt_adapt), 'o-')
plt.xlabel("$t$")
plt.ylabel("$h$")
plt.title("Évolution du pas adaptatif")
plt.grid(True)
plt.show()
# ================================================================
# Comparaison des approximations en t=tfinal
# ================================================================
from tabulate import tabulate
tab = []
headers = ["Méthode", "t final", "|u(t final)-exacte(tfinal)|", "Points de grille"]
tab.append(["RK4", tt[-1], abs(uu_RK4[-1]-sol_exacte(tfinal)), len(tt)])
tab.append(["RK5", tt[-1], abs(uu_RK5[-1]-sol_exacte(tfinal)), len(tt)])
idx = np.argmax(tt_adapt>tfinal)-1
tab.append(["RK45", tt_adapt[idx], abs(uu_adapt[idx]-sol_exacte(tt_adapt[idx])), len(tt_adapt)])
display(tabulate(tab, headers=headers, tablefmt="html", floatfmt=".2e"))\(\displaystyle y{\left(t \right)} = \frac{2}{1 + e^{- 2 t}}\)
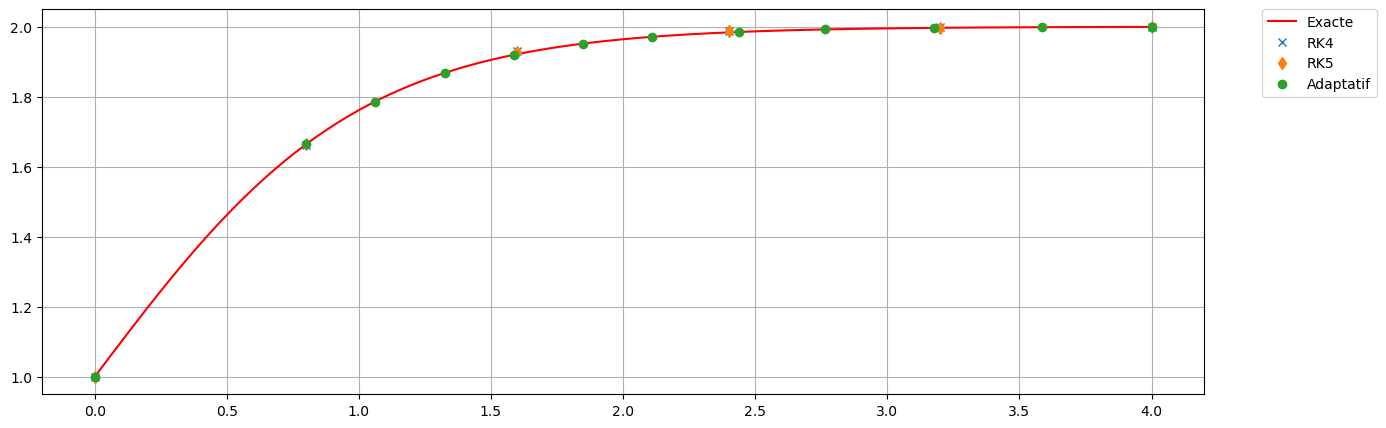
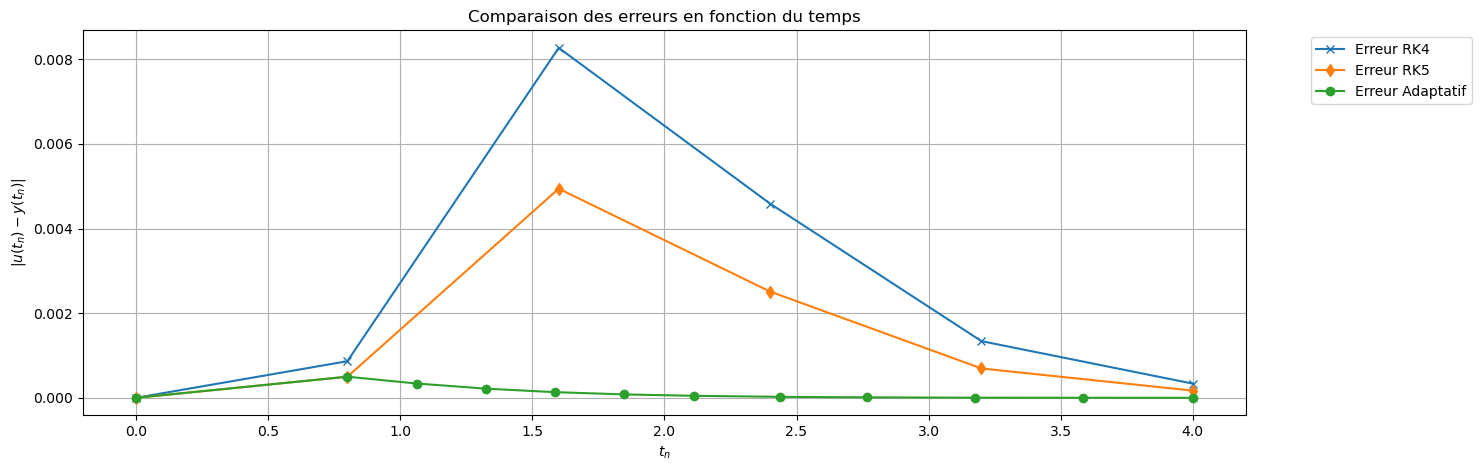
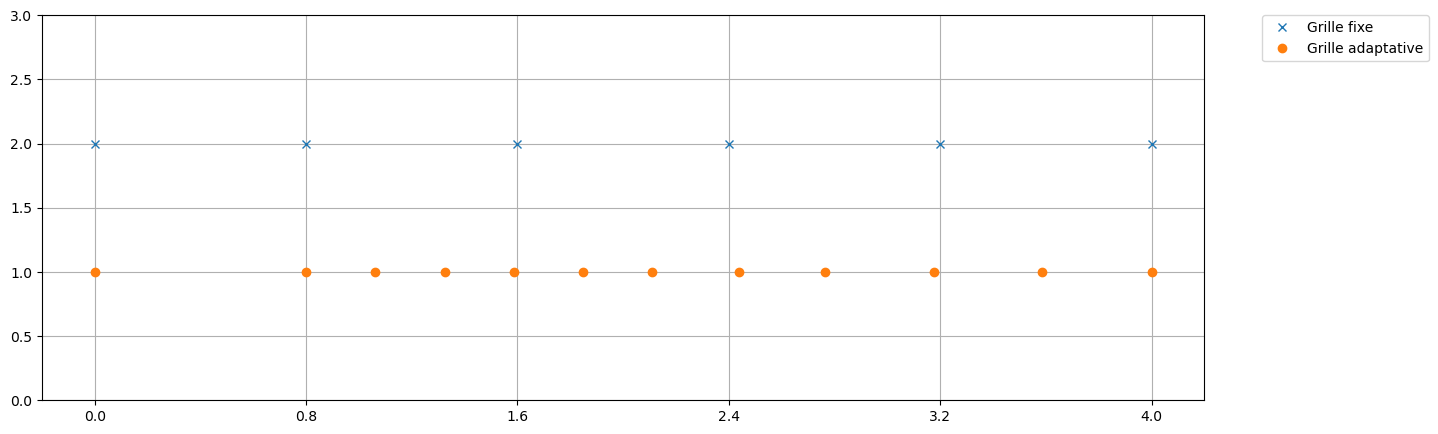
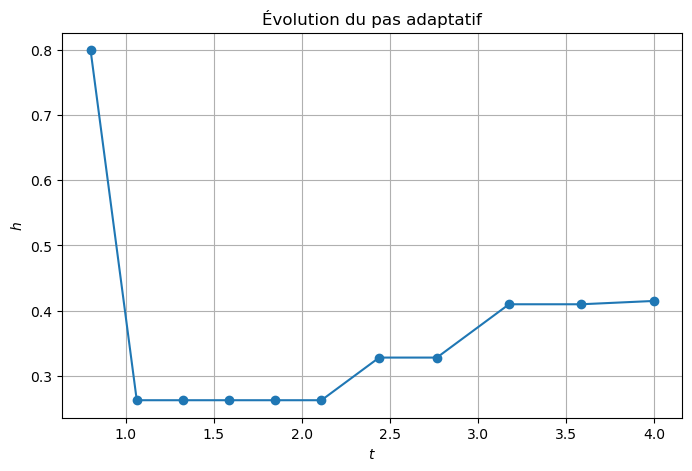
| Méthode | t final | |u(t final)-exacte(tfinal)| | Points de grille |
|---|---|---|---|
| RK4 | 4.00e+00 | 3.36e-04 | 6 |
| RK5 | 4.00e+00 | 1.70e-04 | 6 |
| RK45 | 4.00e+00 | 1.31e-07 | 12 |
Voici la matrice de Butcher associée à la méthode de Dormand-Prince (DP45). Ce tableau représente les coefficients des deux méthodes Runge-Kutta utilisées dans la méthode RK45 pour calculer les coefficients \(k_0\) à \(k_5\), ainsi que les coefficients \(b_0\) à \(b_5\) et \(\hat b_0\) à \(\hat b_5\) utilisés pour combiner les \(K_i\) afin d’obtenir une approximation à l’étape suivante. \( \begin{array}{c|ccccccc} % 1 + 7 colonnes = 8 0 & & & & & & & \\ \frac{1}{5} & \frac{1}{5} & & & & & & \\ \frac{3}{10}& \frac{3}{40} & \frac{9}{40} & & & & & \\ \frac{4}{5} & \frac{44}{45} & -\frac{56}{15} & \frac{32}{9} & & & & \\ \frac{8}{9} & \frac{19372}{6561} & -\frac{25360}{2187} & \frac{64448}{6561} & -\frac{212}{729} & & & \\ 1 & \frac{9017}{3168} & -\frac{355}{33} & \frac{46732}{5247} & \frac{49}{176} & -\frac{5103}{18656} & & \\ 1 & \frac{35}{384} & 0 & \frac{500}{1113} & \frac{125}{192} & -\frac{2187}{6784} & \frac{11}{84} & \\ \hline & \frac{35}{384} & 0 & \frac{500}{1113} & \frac{125}{192} & -\frac{2187}{6784} & \frac{11}{84} & 0 \\ & \frac{5179}{57600} & 0 & \frac{7571}{16695} & \frac{393}{640} & -\frac{92097}{339200} & \frac{187}{2100} & \frac{1}{40} \\ \end{array} \)
Voyons un exemple d’implémentation de la méthode de Runge-Kutta-Fehlberg (RKF45) à pas adaptatif.
def coeff_K(phi, h, t, u):
k = np.zeros(7)
k[0] = phi(t,u)
k[1] = phi(t+h/5,u+h/5*k[0])
k[2] = phi(t+3*h/10,u+3*h/40*k[0]+9*h/40*k[1])
k[3] = phi(t+4*h/5,u+44*h/45*k[0]-56*h/15*k[1]+32*h/9*k[2])
k[4] = phi(t+8*h/9,u+19372*h/6561*k[0]-25360*h/2187*k[1]+64448*h/6561*k[2]-212*h/729*k[3])
k[5] = phi(t+h,u+9017*h/3168*k[0]-355*h/33*k[1]+46732*h/5247*k[2]+49*h/176*k[3]-5103*h/18656*k[4])
k[6] = phi(t+h,u+35*h/384*k[0]+0*k[1]+500*h/1113*k[2]+125*h/192*k[3]-2187*h/6784*k[4]+11*h/84*k[5])
return k
def Dor( phi, tt, y0 ):
h = tt[1]-tt[0]
uu = np.empty_like(tt)
uu[0] = y0
for n in range(len(tt)-1):
kk = coeff_K(phi, h, tt[n], uu[n])
uu[n+1] = uu[n] + h*( 35/384*kk[0] + 0*kk[1] + 500/1113*kk[2] + 125/192*kk[3] - 2187/6784*kk[4] + 11/84*kk[5] )
return uu
def Pri( phi, tt, y0 ):
h = tt[1]-tt[0]
uu = np.empty_like(tt)
uu[0] = y0
for n in range(len(tt)-1):
kk = coeff_K(phi, h, tt[n], uu[n])
uu[n+1] = uu[n] + h* ( 5179/57600*kk[0] + 0*kk[1] + 7571/16695*kk[2] + 393/640*kk[3] - 92097/339200*kk[4] + 187/2100*kk[5] + 1/40*kk[6] )
return uu
def DP45( phi, t0, tfinal, y0, tol, hinit, hmin, hmax ):
tt = np.array([t0])
uu = np.array([y0])
uu[0] = y0
h = hinit
n = 0
while tt[n]<tfinal:
kk = coeff_K(phi, h, tt[n], uu[n])
# Un pas de Pri
# uu_om_p1 = uu[n] + h* ( 5179/57600*k0 + 0*k1 + 7571/16695*k2 + 393/640*k3 - 92097/339200*k4 + 187/2100*k5 + 1/40*k6 )
uu_om_p1 = uu[n] + h*( 35/384*kk[0] + 0*kk[1] + 500/1113*kk[2] + 125/192*kk[3] - 2187/6784*kk[4] + 11/84*kk[5] )
# choix
err = h*( (35/384-5179/57600)*kk[0] +
(0-0)*kk[1] +
(500/1113-7571/16695)*kk[2] +
(125/192-393/640)*kk[3] +
(-2187/6784-92097/339200)*kk[4] +
(11/84-187/2100)*kk[5] +
(0-1/40)*kk[6] )
if err > tol:
# Solution refusée et adaptation du pas
h = max( 0.8*h, hmin )
else:
# Solution acceptée
tt = np.append(tt,tt[n]+h)
uu = np.append(uu,uu_om_p1)
n = n+1
# Adaptation du pas
if err < tol / 3:
h = min( 1.25*h, hmax )
# sinon h inchangé
if tt[n]+h>tfinal: h = tfinal-tt[n]
return tt,uu
# ================================
# MAIN
# ================================
t0, tfinal = 0, 8
y0 = 1
phi = lambda t,y : y*(2-y)
import sympy as sp
t = sp.symbols('t')
y = sp.Function('y')
sol_par = sp.dsolve( sp.Eq(y(t).diff(t), phi(t,y(t)) ) , ics={y(t0): y0} )
display(sol_par)
sol_exacte = sp.lambdify(t,sol_par.rhs,'numpy')
# ================================
# Comparaison des méthodes
# ================================
plt.figure(figsize=(15,5))
# exacte
tt_ex = np.linspace(t0,tfinal,101)
yy = sol_exacte(tt_ex)
plt.plot(tt_ex, yy, 'r',label=r'Exacte')
# Pas fixe h
tt = np.linspace(t0,tfinal,11)
h_init = tt[1]-tt[0]
# Dorman
uu_Dor = Dor(phi, tt, y0)
plt.plot(tt,uu_Dor, 'v', label='Dorman')
# Prince
uu_Pri = Pri(phi, tt, y0)
plt.plot(tt,uu_Pri, 'd', label='Prince')
# DP45 à pas adaptatif
tt_adapt, uu_adapt = DP45(phi, t0, tfinal, y0, tol=1.e-3, hinit=h_init, hmin=h_init/10, hmax=3*h_init)
plt.plot(tt_adapt,uu_adapt, 'o', label='Adaptatif_EE')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0.)
plt.grid();
# ================================
# Graphe de comparaison des erreurs
# ================================
err_Dor = np.abs(uu_Dor - sol_exacte(tt))
err_Pri = np.abs(uu_Pri - sol_exacte(tt))
err_adapt = np.abs(uu_adapt - sol_exacte(tt_adapt))
plt.figure(figsize=(15,5))
plt.plot(tt, err_Dor, 'v-', label='Erreur Dorman')
plt.plot(tt, err_Pri, 'd-', label='Erreur Prince')
plt.plot(tt_adapt, err_adapt, 'o-', label='Erreur Adaptatif')
plt.xlabel("$t_n$")
plt.ylabel(r"$|u(t_n)-y(t_n)|$")
plt.title("Comparaison des erreurs en fonction du temps")
plt.grid(True, which="both")
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
plt.show()
# ================================
# Comparaison des grilles
# ================================
plt.figure(figsize=(15,5))
plt.plot(tt,np.ones_like(tt)*2,'v',label='Grille grossière')
plt.plot(tt_adapt,np.ones_like(tt_adapt),'o',label='Grille adaptative')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0.)
plt.ylim(0,3);
plt.xticks(tt)
plt.yticks([1,2], ['Adaptative','Fixe'])
plt.grid()
plt.show()
# ================================================================
# Évolution du pas adaptatif
# ================================================================
plt.figure(figsize=(8,5))
plt.plot(tt_adapt[1:], np.diff(tt_adapt), 'o-')
plt.xlabel("$t$")
plt.ylabel("$h$")
plt.title("Évolution du pas adaptatif")
plt.grid(True)
plt.show()
# ================================================================
# Comparaison des approximations en t=tfinal
# ================================================================
from tabulate import tabulate
tab = []
headers = ["Méthode", "t final", "|u(t final)-exacte(tfinal)|", "Points de grille"]
tab.append(["Dorman", tt[-1], abs(uu_Dor[-1]-sol_exacte(tfinal)), len(tt)])
tab.append(["Prince", tt[-1], abs(uu_Pri[-1]-sol_exacte(tfinal)), len(tt)])
idx = np.argmax(tt_adapt>tfinal)-1
tab.append(["DP45", tt_adapt[idx], abs(uu_adapt[idx]-sol_exacte(tt_adapt[idx])), len(tt_adapt)])
display(tabulate(tab, headers=headers, tablefmt="html", floatfmt=".2e"))\(\displaystyle y{\left(t \right)} = \frac{2}{1 + e^{- 2 t}}\)
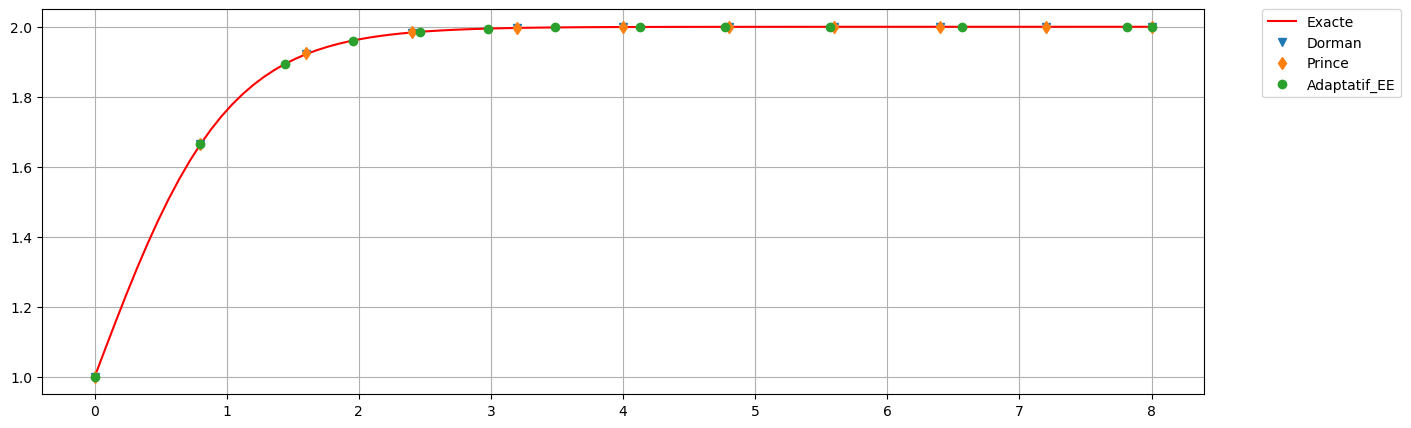
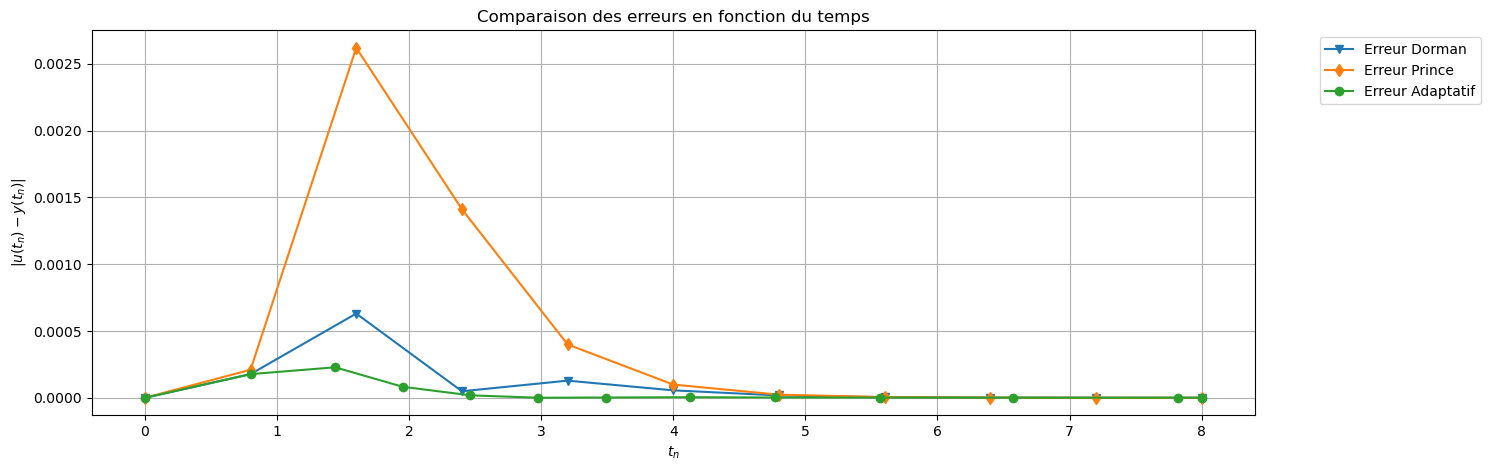
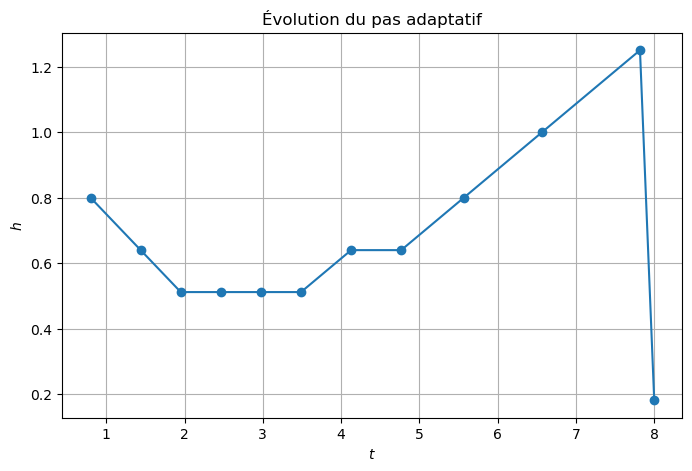
| Méthode | t final | |u(t final)-exacte(tfinal)| | Points de grille |
|---|---|---|---|
| Dorman | 8.00e+00 | 7.86e-08 | 11 |
| Prince | 8.00e+00 | 6.01e-08 | 11 |
| DP45 | 8.00e+00 | 6.76e-07 | 13 |
Lorsqu’on utilise une des méthodes présentées jusqu’ici, une question ouverte est le choix du pas de discrétisation \(h\) pour obtenir une solution précise sans effectuer un nombre excessif de calculs. Une idée naturelle consiste à ajuster dynamiquement le pas de discrétisation en fonction de l’erreur commise à chaque itération. Si l’erreur est inférieure à une tolérance donnée, on peut augmenter le pas de discrétisation pour accélérer le calcul. Inversement, si l’erreur est trop grande, on peut diminuer le pas de discrétisation pour améliorer la précision. Dans ce cas, la discrétisation \(h_n\) n’est plus uniforme mais dépend de l’itération \(n\) : \(t_{n+1} = t_n + h_n\).
Pour estimer l’erreur de discrétisation locale, nous comparons deux approximations : la première calcule \(u_{n+1}\) avec un pas \(h\), la seconde calcule \(u_{n+1}\) avec un pas \(h/2\). L’erreur de discrétisation locale est alors estimée par la différence entre ces deux approximations.
Cette approche est particulièrement adaptée au cas des équations raides, où la solution varie rapidement sur certaines parties de l’intervalle de temps et lentement sur d’autres. Un pas de discrétisation uniforme peut être trop grand pour les parties lentes et trop petit pour les parties rapides. En ajustant le pas de discrétisation en fonction de l’erreur locale, on peut obtenir une solution précise sans effectuer un nombre excessif de calculs.
Étape I : Implémentation de la fonction euler_adaptatif
La méthode d’Euler explicite classique utilise un pas de temps fixe \(h\) : \(u_{n+1} = u_n + h \varphi(t_n, u_n).\) Cependant, pour améliorer la précision tout en minimisant le nombre de calculs, on peut utiliser une version adaptative de la méthode d’Euler. Dans cette version, le pas de temps \(h_n\) est ajusté dynamiquement en fonction d’une estimation de l’erreur locale.
Créez une fonction euler_adaptatif(phi, t0, y0, h0, tol, tfin) qui prend en entrée :
phi : fonction définissant l’équation différentielle \(y'(t) = \varphi(t, y(t))\)t0 : temps initialy0 : condition initiale \(y(t_0)\)h0 : pas de temps initialtol : tolérance pour l’estimation de l’erreur localetfin : temps maximal jusqu’où intégrer l’équation.La fonction doit renvoyer :
L’algorithme d’adaptation du pas de temps suit les étapes suivantes :
Tant que \(t_n\le t_{\text{fin}}\) :
Étape 2 : Test de la méthode
Considérons le problème de Cauchy
\( \begin{cases} y'(t) = -y(t),\\ y(0) = 1. \end{cases} \quad t \in [0, 20]. \)
Nous voulons comparer les solutions obtenues avec la méthode d’Euler explicite et avec la méthode d’Euler adaptative. Nous comparerons ensuite le nombre de points utilisés avec les deux méthodes.
Correction
On commence par calculer une solution approchée avec la méthode d’Euler explicite. On peut ensuite calculer une solution approchée avec la méthode d’Euler adaptatif. On compare ensuite le nombre de points calculés avec les deux méthodes.
def EE(phi,tt,y0):
N = len(tt)-1
h = tt[1]-tt[0]
uu = np.zeros(N+1)
uu[0] = y0
for n in range(N):
uu[n+1] = uu[n] + h*phi(tt[n],uu[n])
return uu
def EA(phi,t0,y0,hinit,tol,tfin):
hmin = 1.e-12
tt = np.array([t0])
uu = np.array([y0])
h = hinit
while tt[-1] < tfin:
k1 = phi(tt[-1],uu[-1])
v = uu[-1] + h*k1
u_demi = uu[-1] + h/2*k1
w = u_demi + h/2*phi(tt[-1]+h/2,u_demi)
erreur = np.abs(w - v)/np.linalg.norm(uu,ord=np.inf)
if erreur < tol or h <= hmin:
tt = np.append(tt,tt[-1]+h)
uu = np.append(uu,w)
h = 2*h
else :
h = max(h/2,hmin)
return tt,uu# TEST
# ========================
phi = lambda t, y : -y
t0, tfin = 0, 40
y0 = 1
# Pour la A-stabilité, il faut que h<2, pour la monotonie h<=1
# h = 1 pour N = (tfin-t0)/h = tfin-t0
N = int(tfin-t0)
tt = np.linspace(t0,tfin,N+1)
plt.figure(figsize=(8,5))
# Solution exacte
sol_exacte = lambda t : y0 * np.exp(-t)
plt.plot(tt,sol_exacte(tt),'-',label='exacte', color='green', lw=2)
# EE
uu_EE = EE(phi,tt,y0)
plt.plot(tt,uu_EE,'o-',label='EE', color='blue')
# EA
hinit = tt[1]-tt[0]
tol = 1.e-3
tt_EA, uu_EA = EA(phi,t0,y0,hinit,tol,tfin)
plt.plot(tt_EA,uu_EA,'o-',label='EA', color='red')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left');
print(f"Erreur EE : {np.linalg.norm(uu_EE-sol_exacte(tt))}")
print(f"Erreur EA : {np.linalg.norm(uu_EA-sol_exacte(tt_EA))}")
print(f"Nombre de pas EE : {len(tt)-1}")
print(f"Nombre de pas EA : {len(tt_EA)-1}")
# Affichons juste les deux grilles de temps sur une droite horizontale
plt.figure(figsize=(8,5))
plt.plot(tt,np.ones_like(tt),'o-',label='EE',color='blue')
plt.plot(tt_EA,1-np.ones_like(tt_EA),'o-',label='EA',color='red')
plt.grid()
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
plt.title('Grilles de temps');Erreur EE : 0.3956231069460752
Erreur EA : 0.03012966353642783
Nombre de pas EE : 40
Nombre de pas EA : 47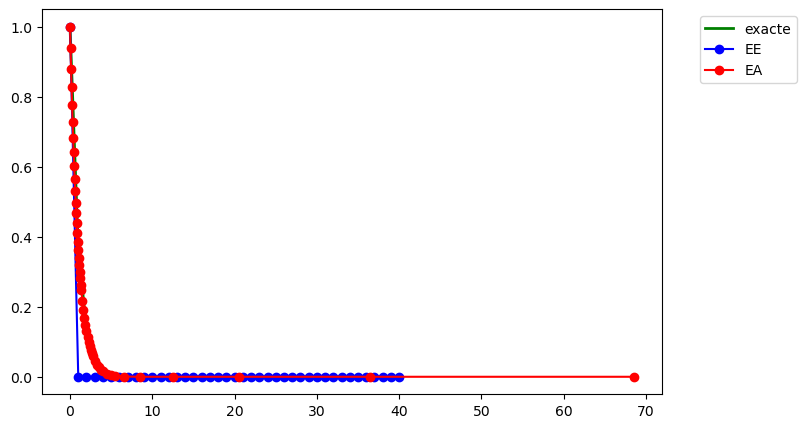
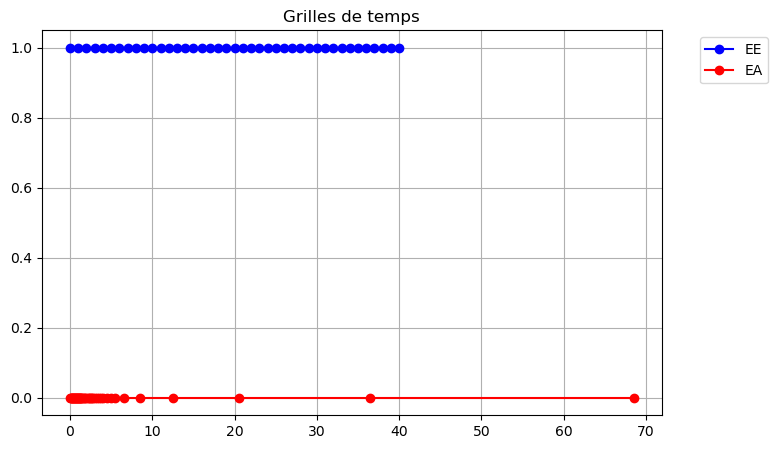
Lorsqu’on utilise une des méthodes présentées jusqu’ici, une question ouverte est le choix du pas de discrétisation \(h\) pour obtenir une solution précise sans effectuer un nombre excessif de calculs. Une idée naturelle consiste à ajuster dynamiquement le pas de discrétisation en fonction de l’erreur commise à chaque itération. Si l’erreur est inférieure à une tolérance donnée, on peut augmenter le pas de discrétisation pour accélérer le calcul. Inversement, si l’erreur est trop grande, on peut diminuer le pas de discrétisation pour améliorer la précision. Dans ce cas, la discrétisation \(h_n\) n’est plus uniforme mais dépend de l’itération \(n\) : \(t_{n+1} = t_n + h_n\).
Pour estimer l’erreur de discrétisation locale, nous comparons deux approximations : pour un même pas \(h\), la première calcule \(u_{n+1}\) avec un schéma, la seconde calcule \(u_{n+1}\) avec un autre schéma. L’erreur de discrétisation locale est alors estimée par la différence entre ces deux approximations.
Cette approche est particulièrement adaptée au cas des équations raides, où la solution varie rapidement sur certaines parties de l’intervalle de temps et lentement sur d’autres. Un pas de discrétisation uniforme peut être trop grand pour les parties lentes et trop petit pour les parties rapides. En ajustant le pas de discrétisation en fonction de l’erreur locale, on peut obtenir une solution précise sans effectuer un nombre excessif de calculs.
Étape I : Implémentation de la fonction euler_heun_adaptatif
Créez une fonction euler_heun_adaptatif(phi, t0, y0, h0, tol, tfin) qui prend en entrée :
phi : fonction définissant l’équation différentielle \(y'(t) = \varphi(t, y(t))\)t0 : temps initialy0 : condition initiale \(y(t_0)\)h0 : pas de temps initialtol : tolérance pour l’estimation de l’erreur localetfin : temps maximal jusqu’où intégrer l’équation.La fonction doit renvoyer :
L’algorithme d’adaptation du pas de temps suit les étapes suivantes :
Tant que \(t_n\ge t_{\text{fin}}\) :
Étape 2 : Test de la méthode
Considérons le problème de Cauchy
\( \begin{cases} y'(t) = -y(t),\\ y(0) = 1. \end{cases} \quad t \in [0, 20]. \)
Nous voulons comparer les solutions obtenues avec la méthode d’Euler explicite, la méthode de Heun et avec la méthode d’Euler-Heun adaptative. Nous comparerons ensuite le nombre de points utilisés avec les deux méthodes.
Correction
On commence par calculer une solution approchée avec la méthode d’Euler explicite. On peut ensuite calculer une solution approchée avec la méthode d’Euler adaptatif. On compare ensuite le nombre de points calculés avec les deux méthodes.
def EE(phi,tt,y0):
N = len(tt)-1
h = tt[1]-tt[0]
uu = np.zeros(N+1)
uu[0] = y0
for n in range(N):
k_0 = phi(tt[n],uu[n])
uu[n+1] = uu[n] + h*k_0
return uu
def Heun(phi,tt,y0):
N = len(tt)-1
h = tt[1]-tt[0]
uu = np.zeros(N+1)
uu[0] = y0
for n in range(N):
k_0 = phi(tt[n],uu[n])
k_1 = phi(tt[n]+h,uu[n]+h*k_0)
uu[n+1] = uu[n] + h/2*(k_0+k_1)
return uu
def EHA(phi,t0,y0,hinit,tol,tfin):
hmin = 1.e-12
tt = np.array([t0])
uu = np.array([y0])
h = hinit
while tt[-1] < tfin:
k_0 = phi(tt[-1],uu[-1])
v = uu[-1] + h*k_0
k_1 = phi(tt[-1]+h,v)
w = uu[-1] + h/2*(k_0 + k_1)
erreur = np.abs(w - v)/np.linalg.norm(uu,ord=np.inf)
if erreur < tol or h <= hmin:
tt = np.append(tt,tt[-1]+h)
uu = np.append(uu,w)
h = 2*h
else :
h = max(h/2,hmin)
return tt,uu# TEST
# ========================
phi = lambda t, y : -y
t0, tfin = 0, 40
y0 = 1
# Pour la A-stabilité, il faut que h<2, pour la monotonie h<=1
# h = 1 pour N = (tfin-t0)/h = tfin-t0
N = int(tfin-t0)
tt = np.linspace(t0,tfin,N+1)
plt.figure(figsize=(8,5))
# Solution exacte
sol_exacte = lambda t : y0 * np.exp(-t)
plt.plot(tt,sol_exacte(tt),'-',label='exacte', color='green', lw=2)
# EE
uu_EE = EE(phi,tt,y0)
plt.plot(tt,uu_EE,'o-',label='EE', color='blue')
# Heun
uu_Heun = Heun(phi,tt,y0)
plt.plot(tt,uu_Heun,'o-',label='Heun', color='orange')
# EHA
hinit = tt[1]-tt[0]
tol = 5.e-3
tt_EHA, uu_EHA = EHA(phi,t0,y0,hinit,tol,tfin)
plt.plot(tt_EHA,uu_EHA,'o-',label='EA', color='red')
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left');
# Affichons juste les deux grilles de temps sur une droite horizontale
plt.figure(figsize=(8,5))
plt.plot(tt,np.ones_like(tt),'o-',label='EE',color='blue')
plt.plot(tt,0.5-np.empty_like(tt),'o-',label='Heun',color='orange')
plt.plot(tt_EHA,1-np.ones_like(tt_EHA),'o-',label='EHA',color='red')
plt.grid()
plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left')
plt.title('Grilles de temps');
# print(f"Erreur EE : {np.linalg.norm(uu_EE-sol_exacte(tt))}")
# print(f"Erreur Heun : {np.linalg.norm(uu_Heun-sol_exacte(tt))}")
# print(f"Erreur EHA : {np.linalg.norm(uu_EHA-sol_exacte(tt_EHA))}")
# print(f"Nombre de pas EE : {len(tt)-1}")
# print(f"Nombre de pas Heun : {len(tt)-1}")
# print(f"Nombre de pas EHA : {len(tt_EHA)-1}")
# Affichage des résultats avec pandas
# ===================================
import pandas as pd
# Création du DataFrame contenant les résultats
data = {
"Méthode": ["Euler Explicite", "Heun", "Euler-Heun Adaptatif"],
"Erreur": [
np.linalg.norm(uu_EE - sol_exacte(tt)),
np.linalg.norm(uu_Heun - sol_exacte(tt)),
np.linalg.norm(uu_EHA - sol_exacte(tt_EHA))
],
"Nombre de pas": [
len(tt) - 1,
len(tt) - 1,
len(tt_EHA) - 1
]
}
pd.DataFrame(data)
| Méthode | Erreur | Nombre de pas | |
|---|---|---|---|
| 0 | Euler Explicite | 0.395623 | 40 |
| 1 | Heun | 0.197615 | 40 |
| 2 | Euler-Heun Adaptatif | 0.009670 | 47 |