Premiers pas avec Pandas
Dans le cours DS&SC-4, nous avons étudié NumPy, dont l’objet principal, le ndarray, permet de stocker et de manipuler efficacement des tableaux homogènes. Cet objet, idéal pour les valeurs numériques (et donc la mise en œuvre de schémas d’approximation), montre ses limites dès qu’il s’agit de données variées (catégories, libellés, dates, texte).
En analyse de données, on organise souvent l’information sous forme de lignes (individus) et de colonnes (variables), qui ne sont pas nécessairement numériques. Exemples :
- dans l’automobile, chaque individu est une voiture, avec des caractéristiques telles que la puissance du moteur, les dimensions, la marque, le modèle, la couleur, etc. ;
- en grande distribution, chaque individu est un produit, avec des informations comme le prix et la catégorie ;
- dans le secteur bancaire, chaque individu est une personne, avec des informations comme le salaire moyen, l’âge et les mensualités d’un prêt.
Nous avons donc besoin d’un outil capable de :
- représenter les données au format individus × variables ;
- manipuler des types hétérogènes ;
- lire et écrire des données depuis diverses sources.
C’est exactement le rôle de la bibliothèque pandas.
Objectifs d’apprentissage
- Identifier les objets de base de
pandas(Series, DataFrame) et leur lien avecNumPy. - Lire et écrire des données (CSV) et comprendre les types hétérogènes.
- Sélectionner, filtrer, trier, agréger et fusionner des données.
- Calculer et interpréter des statistiques descriptives (describe, moyennes, écarts-types, quantiles).
- Visualiser des données avec
Matplotlib,Seaborn,Plotlyet choisir une représentation adaptée.
1 Importation de pandas
Une fois pandas installé, vérifions que tout fonctionne correctement. La communauté Python a adopté quelques conventions de nommage pour les modules courants :
Définissons quelques options par défaut pour la création des figures :
plt.rcParams['font.size'] = 15
plt.rcParams['figure.figsize'] = (15, 7) # Taille par défaut des figures
# plt.style.use('ggplot') # set ggplot style
sns.set_theme(context = "notebook", # paper, notebook, talk, poster
style = "darkgrid", # ticks, whitegrid, darkgrid, white, dark
palette = "pastel", # None, Set2, husl, deep, muted, bright, pastel, dark, colorblind
rc = {"axes.spines.right": False,
"axes.spines.top": False}
)Quelques remarques sur les bibliothèques de visualisation. Trois options populaires se distinguent : Matplotlib, Seaborn et Plotly, chacune avec ses forces et particularités.
- Matplotlib est la bibliothèque de base en Python. Elle offre une grande flexibilité et un contrôle fin de tous les aspects des graphiques, des tracés simples aux visualisations complexes. Elle est idéale pour une personnalisation poussée et un large éventail de types de graphiques. Cette flexibilité s’accompagne toutefois d’une complexité accrue et demande souvent davantage de code.
- Seaborn, construit sur Matplotlib, simplifie la création de graphiques statistiques élégants. Il propose des thèmes et des palettes intégrés qui rendent les visualisations plus attrayantes et informatives. En contrepartie, les personnalisations très spécifiques peuvent être plus limitées.
Avec Matplotlib et Seaborn, les figures sont statiques : toute l’information doit être visible dans la figure, ce qui peut la surcharger. On peut concevoir des visualisations à plusieurs niveaux : un premier niveau « coup d’œil » pour les messages clés, puis des détails supplémentaires. Les visualisations interactives, devenues la norme en dataviz, facilitent cette approche : au survol de la souris, on obtient des informations complémentaires (par exemple, les valeurs exactes).
- Plotly, basé sur JavaScript, permet de créer des visualisations interactives et dynamiques. Il prend en charge les graphiques 3D et les cartes, ce qui le rend très puissant.
2 Un tableau monodimensionnel : la série
Commençons par créer des données aléatoires et tracer leur histogramme. Il s’agit d’une série, c’est-à-dire la généralisation d’un tableau NumPy à une dimension.
np.random.seed(0) # for reproducibility
values = np.random.randn(100) # array of normally distributed random numbers
s = pd.Series(values) # generate a pandas series
display(s)0 1.764052
1 0.400157
2 0.978738
3 2.240893
4 1.867558
...
95 0.706573
96 0.010500
97 1.785870
98 0.126912
99 0.401989
Length: 100, dtype: float64s.plot(kind='hist', title='Normally distributed random values', color='c', bins=10, edgecolor='black'); # histogram of the data
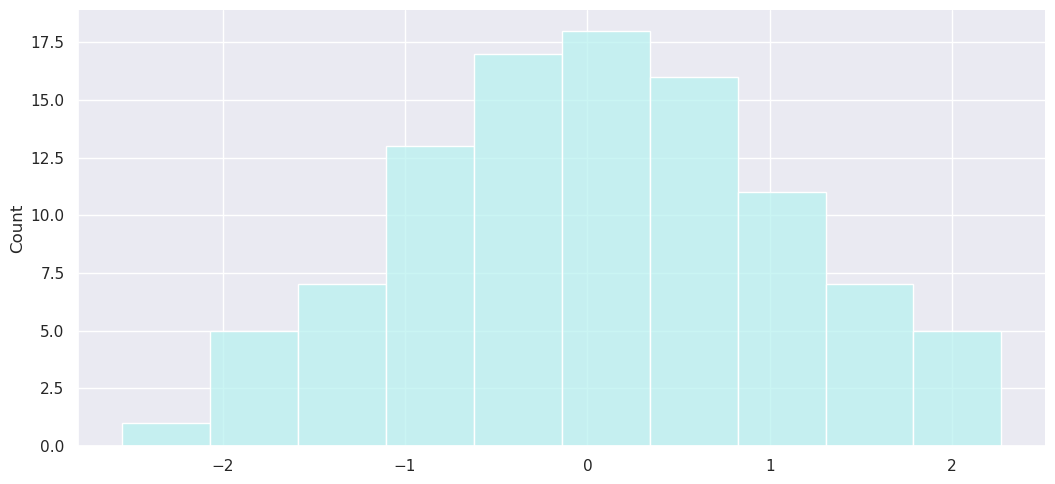
sns.displot(s, bins=10, color='c', aspect=15/7); # seaborn histogram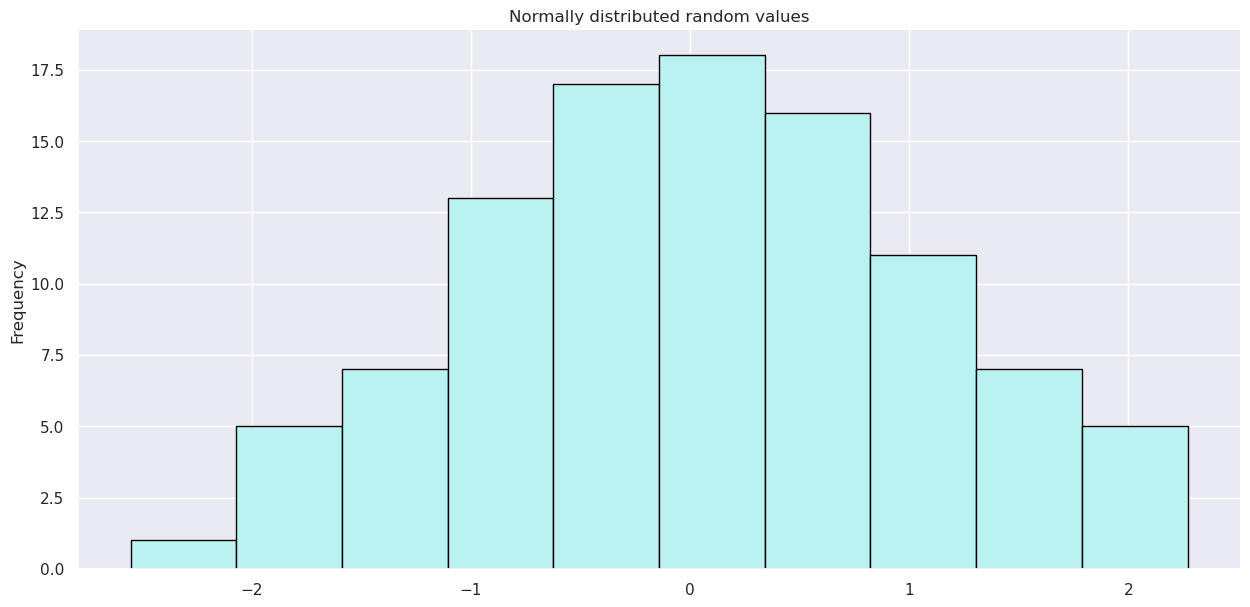
Vérifions quelques statistiques des données (moyenne, écart-type, nombre d’observations, minimum, maximum et quartiles) à l’aide de la méthode .describe() :
3 Un tableau bidimensionnel : le DataFrame
Passons à un exemple avec un DataFrame.
Un DataFrame est une structure de données bidimensionnelle, similaire à une table de base de données ou à une feuille de calcul Excel. Il est particulièrement utile pour gérer des données hétérogènes, c’est-à-dire des données de types différents (entiers, chaînes de caractères, dates, etc.).
df = pd.DataFrame({'Colonne A': [1, 2, 1, 4, 3, 5, 2, 3, 4, 1],
'Colonne B': [12, 14, 11, 16, 18, 18, 22, 13, 21, 17],
'Colonne C': ['a', 'a', 'b', 'a', 'b', 'c', 'b', 'a', 'b', 'a']})
display(df)| Colonne A | Colonne B | Colonne C | |
|---|---|---|---|
| 0 | 1 | 12 | a |
| 1 | 2 | 14 | a |
| 2 | 1 | 11 | b |
| 3 | 4 | 16 | a |
| 4 | 3 | 18 | b |
| 5 | 5 | 18 | c |
| 6 | 2 | 22 | b |
| 7 | 3 | 13 | a |
| 8 | 4 | 21 | b |
| 9 | 1 | 17 | a |
Vérifions à nouveau quelques statistiques des données (moyenne, écart-type, nombre d’observations, minimum, maximum et quartiles) à l’aide de la méthode .describe() :
| Colonne A | Colonne B | |
|---|---|---|
| count | 10.000000 | 10.000000 |
| mean | 2.600000 | 16.200000 |
| std | 1.429841 | 3.705851 |
| min | 1.000000 | 11.000000 |
| 25% | 1.250000 | 13.250000 |
| 50% | 2.500000 | 16.500000 |
| 75% | 3.750000 | 18.000000 |
| max | 5.000000 | 22.000000 |
On observe que, puisque la colonne C ne contient pas de valeurs numériques, elle est exclue de la sortie. Dans ce cas, on peut afficher le nombre d’observations par catégorie, le nombre d’éléments uniques, le mode et la fréquence du mode.
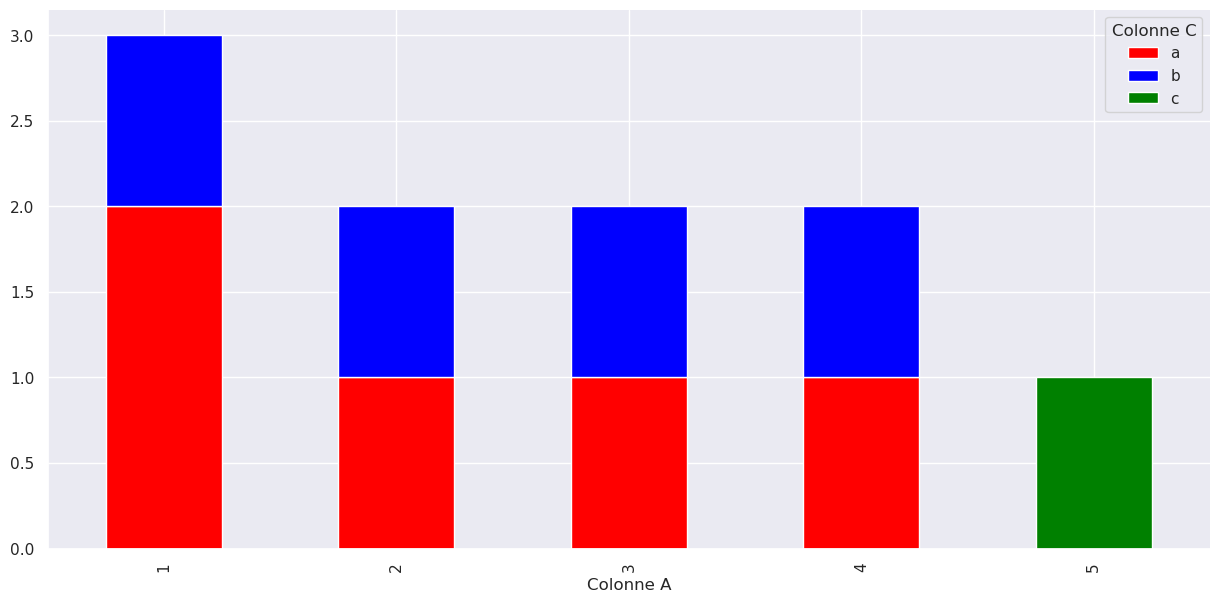
On peut également croiser les données avec crosstab() puis visualiser le résultat :
| Colonne C | a | b | c |
|---|---|---|---|
| Colonne A | |||
| 1 | 2 | 1 | 0 |
| 2 | 1 | 1 | 0 |
| 3 | 1 | 1 | 0 |
| 4 | 1 | 1 | 0 |
| 5 | 0 | 0 | 1 |