Notes et moyennes pondérées en L3 Mathématiques
1 Exercice
On s’intéresse aux résultats d’un étudiant (ou de deux étudiants) en L3 Mathématiques, pour les deux semestres de l’année universitaire.
On vous fournit les ECUE, leurs coefficients, et les notes (aléatoires) de chaque étudiant.
1.1 Semestre 1
- Créér une Series contenant les coefficients des ECUE. Les indices doivent être les noms des ECUE.
- Crééer une Series contenant les notes des ECUE (entiers aléatoires entre 0 et 20), avec les mêmes indices que pour les coefficients.
- Construire un DataFrame à partir de ces deux Series.
Exemple attendu :
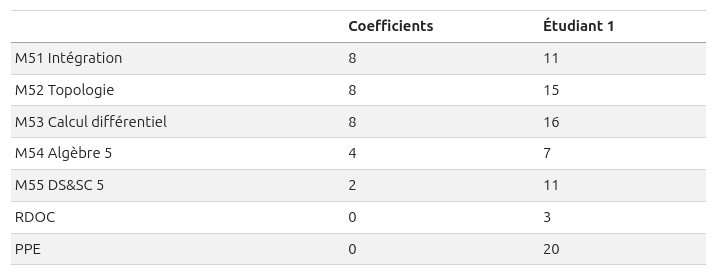
Bonus: ajouter un deuxième étudiant.
1.2 Semestre 2
Faire la même chose pour les ECUE du semestre 2.
Exemple attendu :
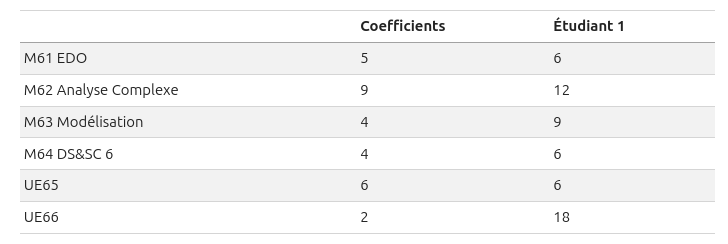
Bonus: ajouter un deuxième étudiant.
1.3 Calculs à effectuer à partir des deux DataFrames
Calculer la moyenne pondérée du semestre 1 : \[ \bar{x} = \frac{\sum_i \text{note}_i \times \text{coeff}_i}{\sum_i \text{coeff}_i} \]
Calculer la moyenne pondérée du semestre 2
Fusionner les deux DataFrames (par concaténation) puis calculer la moyenne pondérée globale. Exemple attendu :
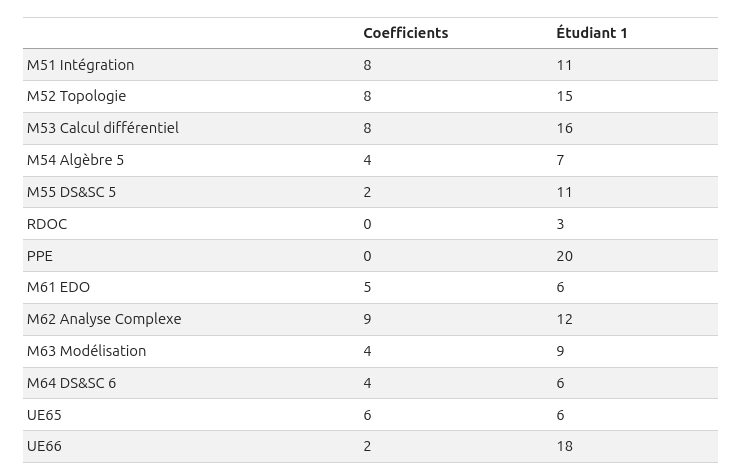
Pour chaque étudiant, déterminer l’ECUE où il a eu sa pire note et l’ECUE où il a eu sa meilleure note.
# --- Semestre 1 : définition des ECUE, coefficients, et notes des étudiants ---
# Liste des ECUE du semestre 1
ecue_names_semester1 = [
"M51 Intégration",
"M52 Topologie",
"M53 Calcul différentiel",
"M54 Algèbre 5",
"M55 DS&SC 5",
"RDOC",
"PPE"
]
nb_ecue_semester1 = len(ecue_names_semester1)
# Coefficients des ECUE (indexés par les noms des ECUE)
coefficients_semester1 = pd.Series(
[8, 8, 8, 4, 2, 0, 0],
index=ecue_names_semester1
)
# Notes aléatoires pour deux étudiants
etu_1_semester1 = pd.Series(
np.random.randint(0, 21, size=nb_ecue_semester1),
index=ecue_names_semester1
)
etu_2_semester1 = pd.Series(
np.random.randint(0, 21, size=nb_ecue_semester1),
index=ecue_names_semester1
)
# Construction du DataFrame
df_semester1 = pd.DataFrame({
"Coefficients": coefficients_semester1,
"Étudiant 1": etu_1_semester1,
"Étudiant 2": etu_2_semester1
})
display(df_semester1)| Coefficients | Étudiant 1 | Étudiant 2 | |
|---|---|---|---|
| M51 Intégration | 8 | 1 | 8 |
| M52 Topologie | 8 | 7 | 17 |
| M53 Calcul différentiel | 8 | 0 | 5 |
| M54 Algèbre 5 | 4 | 10 | 10 |
| M55 DS&SC 5 | 2 | 16 | 15 |
| RDOC | 0 | 4 | 6 |
| PPE | 0 | 3 | 9 |
# --- Semestre 2 : définition des ECUE, coefficients, et notes des étudiants ---
# Liste des ECUE du semestre 2
ecue_names_semester2 = [
"M61 EDO",
"M62 Analyse Complexe",
"M63 Modélisation",
"M64 DS&SC 6",
"UE65",
"UE66"
]
nb_ecue_semester2 = len(ecue_names_semester2)
# Coefficients des ECUE (indexés par les noms des ECUE)
coefficients_semester2 = pd.Series(
[5, 9, 4, 4, 6, 2],
index=ecue_names_semester2
)
# Notes aléatoires pour deux étudiants
etu_1_semester2 = pd.Series(
np.random.randint(0, 21, size=nb_ecue_semester2),
index=ecue_names_semester2
)
etu_2_semester2 = pd.Series(
np.random.randint(0, 21, size=nb_ecue_semester2),
index=ecue_names_semester2
)
# Construction du DataFrame
df_semester2 = pd.DataFrame({
"Coefficients": coefficients_semester2,
"Étudiant 1": etu_1_semester2,
"Étudiant 2": etu_2_semester2
})
display(df_semester2)| Coefficients | Étudiant 1 | Étudiant 2 | |
|---|---|---|---|
| M61 EDO | 5 | 2 | 19 |
| M62 Analyse Complexe | 9 | 2 | 12 |
| M63 Modélisation | 4 | 1 | 11 |
| M64 DS&SC 6 | 4 | 4 | 18 |
| UE65 | 6 | 15 | 20 |
| UE66 | 2 | 9 | 16 |
# Fonction qui pour un DataFrame donné et un étudiant donné
# calcule la moyenne pondérée
def weighted_average(df, student_name):
notes = df[student_name]
coeffs = df["Coefficients"]
# --- Somme pondérée ---
return (notes * coeffs).sum() / coeffs.sum()
# --- Alternatives ---
# return notes.dot(coeffs) / coeffs.sum()
# return np.average(notes, weights=coeffs)
# Moyenne pondérée pour chaque étudiant au semestre 1
print("Semestre 1")
for etu in ["Étudiant 1", "Étudiant 2"]:
print(f"{etu} : {weighted_average(df_semester1, etu):.2f}")Semestre 1
Étudiant 1 : 4.53
Étudiant 2 : 10.33# Moyenne pondérée pour chaque étudiant au semestre 2
print("Semestre 2")
for etu in ["Étudiant 1", "Étudiant 2"]:
print(f"{etu} : {weighted_average(df_semester2, etu):.2f}")Semestre 2
Étudiant 1 : 7.20
Étudiant 2 : 3.37Notes et coefficients pour l’année entière :
# ==========================================
# Fusion des semestres pour l'année entière
# ==========================================
# Option 1 : concaténation simple (les lignes sont juste empilées)
df_year = pd.concat([df_semester1, df_semester2])
display(df_year)
# Option 2 : concaténation avec MultiIndex pour identifier le semestre
# df_year = pd.concat([df_semester1, df_semester2],
# keys=["Semestre 1", "Semestre 2"], axis=0)
# display(df_year)
# Avantages :
# - Option 1 : plus simple pour calculer directement les moyennes pondérées
# - Option 2 : permet de conserver l'information du semestre dans l'index| Coefficients | Étudiant 1 | Étudiant 2 | |
|---|---|---|---|
| M51 Intégration | 8 | 8 | 18 |
| M52 Topologie | 8 | 15 | 12 |
| M53 Calcul différentiel | 8 | 8 | 0 |
| M54 Algèbre 5 | 4 | 18 | 10 |
| M55 DS&SC 5 | 2 | 14 | 9 |
| RDOC | 0 | 15 | 6 |
| PPE | 0 | 11 | 2 |
| M61 EDO | 5 | 0 | 2 |
| M62 Analyse Complexe | 9 | 12 | 1 |
| M63 Modélisation | 4 | 0 | 13 |
| M64 DS&SC 6 | 4 | 7 | 1 |
| UE65 | 6 | 8 | 4 |
| UE66 | 2 | 16 | 1 |
# Calculs de la pire et meilleure note pour chaque étudiant au semestre 1
for etu in ["Étudiant 1", "Étudiant 2"]:
min_idx = df_semester1[etu].idxmin()
max_idx = df_semester1[etu].idxmax()
print(f"{etu} :")
print(f" Pire note au semestre 1 : {df_semester1.loc[min_idx, etu]} à {min_idx}")
print(f" Meilleure note au semestre 1 : {df_semester1.loc[max_idx, etu]} à {max_idx}")
print()Étudiant 1 :
Pire note au semestre 1 : 8 à M51 Intégration
Meilleure note au semestre 1 : 18 à M54 Algèbre 5
Étudiant 2 :
Pire note au semestre 1 : 0 à M53 Calcul différentiel
Meilleure note au semestre 1 : 18 à M51 Intégration
# ===============================
# DataFrame récapitulatif annuel
# ===============================
students = ["Étudiant 1", "Étudiant 2"]
df_summary = pd.DataFrame({
etu: {
"Pire note": df_year[etu].min(),
"ECUE pire note": df_year[etu].idxmin(),
"Meilleure note": df_year[etu].max(),
"ECUE meilleure note": df_year[etu].idxmax(),
"Moyenne annuelle pondérée": weighted_average(df_year, etu),
"Moyenne semestre 1": weighted_average(df_semester1, etu),
"Moyenne semestre 2": weighted_average(df_semester2, etu)
}
for etu in students
})
display(df_summary)| Étudiant 1 | Étudiant 2 | |
|---|---|---|
| Pire note | 0 | 0 |
| ECUE pire note | M61 EDO | M53 Calcul différentiel |
| Meilleure note | 18 | 18 |
| ECUE meilleure note | M54 Algèbre 5 | M51 Intégration |
| Moyenne annuelle pondérée | 9.4 | 6.65 |
| Moyenne semestre 1 | 11.6 | 9.933333 |
| Moyenne semestre 2 | 7.2 | 3.366667 |