Loi de Benford et suspicion de fraudes aux présidentielles des USA en 2016
Source : problème 9 de “Python & Pandas et les 36 problèmes de Data Science”, Frédéric Bro et Chantal Remy
La loi de Benford est une loi empirique qui concerne la distribution des premiers chiffres significatifs dans de nombreux ensembles de données réels. Elle prédit que le premier chiffre significatif suit une distribution logarithmique, c’est-à-dire que le chiffre 1 apparaît en premier 30% du temps, le chiffre 2 apparaît 17,6% du temps, le chiffre 3 apparaît 12,5% du temps, etc. Une loi analogue est valable pour le second chiffre significatif. De nos jours, pour vérifier l’authenticité des données, on peut vérifier si elles suivent la loi de Benford. Si ce n’est pas le cas, cela peut être un signe de fraude.
Lors des élections présidentielles américaines de 2016, des chercheurs ont appliqué la loi de Benford aux résultats des élections dans les différents États. Ils ont constaté que les résultats des élections dans certains États ne suivaient pas la loi de Benford et ont suggéré que cela pourrait être dû à des fraudes électorales. Ceci incita les candidats Hilary Clinton et Jill Stein à demander un comptage manuel dans certains comtés.
Dans cet exercice, vous allez vérifier si les résultats des élections dans les différents États des États-Unis en 2016 suivent la loi de Benford. Pour cela, vous allez utiliser les données des élections présidentielles américaines de 2016, disponibles dans le fichier benford_usa.csv.
Quelques liens pour en savoir plus sur la loi de Benford :
1 Exercice
Loi de Benford
Tracer la fréquence relative du deuxième chiffre significatif \(c\in\{0,1,\dots,9\}\) dans la représentation en base \(10\) prédite par la loi de Benford suivante : \[ p(c) = \sum_{i=1}^9 \log_{10}\left(1+\frac{1}{10i+c}\right). \]Ouverture et sélection des données
- Le fichier
benford_usa.csvcontient le nombre de voix remportées par trois candidats dans chaque district des États-Unis. Importer le fichier et analyser brièvement les données.
Bonus : retrouver le résultat des élections en combinant avec le nombre de grands électeurs par État (cf. Wikipedia). - Ne garder ensuite que les lignes correspondant aux comtés du Michigan, de la Pennsylvanie et du Wisconsin. Parmi ces lignes, ne garder que celles où chaque candidat a obtenu plus de 10 voix. Ce sont ces données que nous allons analyser.
- Le fichier
Analyse des données
En théorie, la répartition des fréquences du deuxième chiffre des nombres de voix suit la loi de Benford. Pour chaque candidat, vérifier si c’est le cas.- Calculer la fréquence du deuxième chiffre des nombres de voix pour chaque candidat et comparer avec la loi de Benford (créer un DataFrame où chaque ligne correspond à un chiffre et chaque colonne à un candidat ; ajouter une colonne pour les fréquences théoriques).
- Afficher/visualiser la distribution de chaque colonne.
- Calculer la fréquence du deuxième chiffre des nombres de voix pour chaque candidat et comparer avec la loi de Benford (créer un DataFrame où chaque ligne correspond à un chiffre et chaque colonne à un candidat ; ajouter une colonne pour les fréquences théoriques).
Bonus : simulation pour la détection d’éventuelles anomalies
Les graphes peuvent susciter des doutes quant à la régularité des résultats. Pour aller plus loin, introduire un indicateur synthétique pour résumer l’analyse.- Calculer la distance euclidienne entre la colonne théorique et la colonne observée pour chaque candidat.
- Simuler \(10^4\) votations qui suivent la distribution théorique de Benford et vérifier si ce résultat est effectivement rare ou non.
- Calculer la distance euclidienne entre la colonne théorique et la colonne observée pour chaque candidat.
Importation des bibliothèques nécessaires.
2 Loi de Benford
La fonction théorique \(p\) qui donne la fréquence du second chiffre significatif dans la représentation en base \(10\) prédite par la loi de Benford est donnée par:
\[
p(c) = \sum_{i=1}^9 \log_{10}\left(1+\frac{1}{10i+c}\right).
\]
# Fonction pour calculer la probabilité
p = lambda c : sum( [ np.log10( 1+1/(10*i+c)) for i in range( 1 , 10 ) ] )
# Générer les chiffres de 0 à 9
cc = np.arange(0,10)
# Calculer les probabilités pour chaque valeur de cc
FB = [ p(c) for c in cc ]
# Affichage des résultats dans un DataFrame, utiliser la première colonne comme index
df = pd.DataFrame({'Chiffre':cc,'Probabilité':FB})
display(df)
# Vérification que FB est normalisée
display(df['Probabilité'].sum())
# Tracer les résultats avec seaborn
sns.barplot(x='Chiffre',y='Probabilité',data=df)
plt.title("Loi de Benford pour le deuxième chiffre significatif")
plt.show()
# Tracer les résultats avec plotly
fig = px.bar(df, x='Chiffre', y='Probabilité', title="Loi de Benford pour le deuxième chiffre significatif")
fig.show()| Chiffre | Probabilité | |
|---|---|---|
| 0 | 0 | 0.119679 |
| 1 | 1 | 0.113890 |
| 2 | 2 | 0.108821 |
| 3 | 3 | 0.104330 |
| 4 | 4 | 0.100308 |
| 5 | 5 | 0.096677 |
| 6 | 6 | 0.093375 |
| 7 | 7 | 0.090352 |
| 8 | 8 | 0.087570 |
| 9 | 9 | 0.084997 |
0.9999999999999997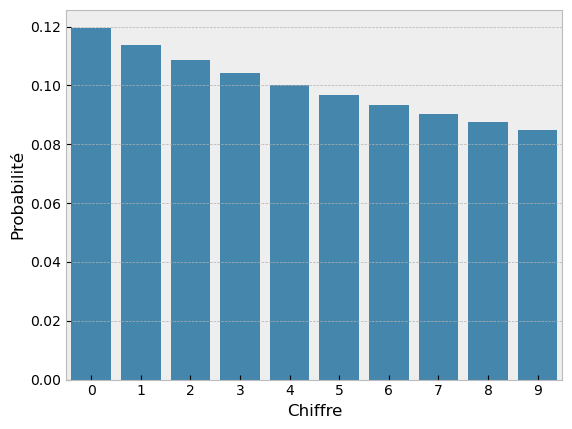
Unable to display output for mime type(s): application/vnd.plotly.v1+json3 Ouverture et séléction des données
On importe les données à partir d’un fichier csv. Par défaut, le séparateur d’éléments est , . Dans ce fichier c’est ;, il faut donc l’indiquer explicitement.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3143 entries, 0 to 3142
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 State 3143 non-null object
1 ST 3143 non-null object
2 Fips 3143 non-null int64
3 County 3143 non-null object
4 Trump 3143 non-null int64
5 Clinton 3143 non-null int64
6 Stein 3143 non-null int64
dtypes: int64(4), object(3)
memory usage: 172.0+ KBNone| State | ST | Fips | County | Trump | Clinton | Stein | |
|---|---|---|---|---|---|---|---|
| 0 | Georgia | GA | 13089 | DeKalb County, Georgia | 47531 | 239131 | 0 |
| 1 | Texas | TX | 48487 | Wilbarger County, Texas | 3166 | 807 | 13 |
| 2 | Virginia | VA | 51111 | Lunenburg County, Virginia | 3206 | 2226 | 25 |
| 3 | Georgia | GA | 13297 | Walton County, Georgia | 31093 | 8279 | 0 |
| 4 | North Carolina | NC | 37011 | Avery County, North Carolina | 6226 | 1670 | 0 |
| 5 | North Carolina | NC | 37069 | Franklin County, North Carolina | 16320 | 12811 | 0 |
| 6 | Michigan | MI | 26037 | Clinton County, Michigan | 21635 | 16490 | 379 |
| 7 | Arkansas | AR | 5045 | Faulkner County, Arkansas | 29170 | 14525 | 507 |
| 8 | North Carolina | NC | 37025 | Cabarrus County, North Carolina | 53224 | 35048 | 0 |
| 9 | Idaho | ID | 16025 | Camas County, Idaho | 410 | 110 | 15 |
Combien de valeurs uniques y a-t-il dans la colonne State ? Et dans la colonne County ? Ou encore dans la colonne Fips ?
for col in ['State', 'County', 'Fips']:
display(Markdown(f"**Nombre de valeurs uniques dans la colonne `{col}` :** {Tot[col].nunique()}"))Nombre de valeurs uniques dans la colonne State : 51
Nombre de valeurs uniques dans la colonne County : 3143
Nombre de valeurs uniques dans la colonne Fips : 3143
Les colonnes “Fips” et “County” ne sont pas utiles pour notre analyse, on peut les supprimer.
| State | ST | Trump | Clinton | Stein | |
|---|---|---|---|---|---|
| 0 | Georgia | GA | 47531 | 239131 | 0 |
| 1 | Texas | TX | 3166 | 807 | 13 |
| 2 | Virginia | VA | 3206 | 2226 | 25 |
| 3 | Georgia | GA | 31093 | 8279 | 0 |
| 4 | North Carolina | NC | 6226 | 1670 | 0 |
| ... | ... | ... | ... | ... | ... |
| 3138 | Tennessee | TN | 9525 | 2425 | 36 |
| 3139 | Michigan | MI | 224589 | 176238 | 3886 |
| 3140 | West Virginia | WV | 3516 | 1315 | 47 |
| 3141 | North Carolina | NC | 6225 | 1585 | 0 |
| 3142 | Maryland | MD | 7938 | 5695 | 94 |
3143 rows × 5 columns
Combien d’états sont dans le fichier ? Lesquels ? Affichons la liste des états (sans doublons):
# Résumé statistique de la colonne 'State'
# ================================================================
colonne = Tot['State']
display(Markdown("**Nombre de valeurs uniques = nombre d'États**"))
display(colonne.nunique())
# display(Markdown("**Valeurs uniques = noms des États**"))
# display(colonne.unique())
display(Markdown("**Combien d'occurrences de chaque valeur unique = combien de fois chaque État apparaît**"))
display(pd.DataFrame({
'Occurrences': colonne.value_counts(),
'Proportions': colonne.value_counts(normalize=True)
}))Nombre de valeurs uniques = nombre d’États
51Combien d’occurrences de chaque valeur unique = combien de fois chaque État apparaît
| Occurrences | Proportions | |
|---|---|---|
| State | ||
| Texas | 254 | 0.080815 |
| Georgia | 159 | 0.050589 |
| Virginia | 134 | 0.042634 |
| Kentucky | 120 | 0.038180 |
| Missouri | 115 | 0.036589 |
| Kansas | 105 | 0.033408 |
| Illinois | 102 | 0.032453 |
| North Carolina | 100 | 0.031817 |
| Iowa | 99 | 0.031499 |
| Tennessee | 95 | 0.030226 |
| Nebraska | 93 | 0.029590 |
| Indiana | 92 | 0.029271 |
| Ohio | 88 | 0.027999 |
| Minnesota | 87 | 0.027681 |
| Michigan | 83 | 0.026408 |
| Mississippi | 82 | 0.026090 |
| Oklahoma | 77 | 0.024499 |
| Arkansas | 75 | 0.023863 |
| Wisconsin | 72 | 0.022908 |
| Pennsylvania | 67 | 0.021317 |
| Florida | 67 | 0.021317 |
| Alabama | 67 | 0.021317 |
| South Dakota | 66 | 0.020999 |
| Louisiana | 64 | 0.020363 |
| Colorado | 64 | 0.020363 |
| New York | 62 | 0.019726 |
| California | 58 | 0.018454 |
| Montana | 56 | 0.017817 |
| West Virginia | 55 | 0.017499 |
| North Dakota | 53 | 0.016863 |
| South Carolina | 46 | 0.014636 |
| Idaho | 44 | 0.013999 |
| Washington | 39 | 0.012409 |
| Oregon | 36 | 0.011454 |
| New Mexico | 33 | 0.010500 |
| Utah | 29 | 0.009227 |
| Alaska | 29 | 0.009227 |
| Maryland | 24 | 0.007636 |
| Wyoming | 23 | 0.007318 |
| New Jersey | 21 | 0.006682 |
| Nevada | 17 | 0.005409 |
| Maine | 16 | 0.005091 |
| Arizona | 15 | 0.004773 |
| Massachusetts | 14 | 0.004454 |
| Vermont | 14 | 0.004454 |
| New Hampshire | 10 | 0.003182 |
| Connecticut | 8 | 0.002545 |
| Hawaii | 5 | 0.001591 |
| Rhode Island | 5 | 0.001591 |
| Delaware | 3 | 0.000955 |
| District of Columbia | 1 | 0.000318 |
Combien de voix ont été obtenues par chaque candidat au total ?
# On affiche le nombre total de votes pour chaque candidat, i.e. la somme des colonnes Trump, Clinton et Stein
cols = ['Trump','Clinton','Stein']
pour_affichage = pd.DataFrame( Tot[cols].sum().sort_values(ascending=False),columns=['Nombre de votes'])
pour_affichage['Pourcentage'] = pour_affichage / pour_affichage.sum() * 100
# pour un affichage plus joli
pour_affichage = pour_affichage.style.format({'Pourcentage':'{:.2f} %'})
pour_affichage| Nombre de votes | Pourcentage | |
|---|---|---|
| Clinton | 62426228 | 50.02 % |
| Trump | 61064602 | 48.93 % |
| Stein | 1311595 | 1.05 % |
4 Bonus : pourquoi une fraude éventuelle dans ces trois états aurait changé le résultat de l’élection ?
Aux USA, ce n’est pas la majorité qui gagne mais le candidat qui obtient le plus de grands électeurs. Clinton a obtenu plus de voix que Trump mais c’est ce dernier qui a été élu. En effet, chaque État a un nombre de grands électeurs qui lui est attribué et le candidat qui remporte la majorité des voix dans un État obtient tous les grands électeurs de cet État.
Voici le bilan des voix puis des grands électeurs obtenus par chaque candidat :
# Agréger les votes par état
# votes_by_state = Tot.pivot_table(index='State', values=['Trump', 'Clinton', 'Stein'], aggfunc='sum')
# Pour garder la colonne 'ST' (code état) on utilise groupby avec agg
votes_by_state = Tot.groupby('State')[['Trump', 'Clinton', 'Stein', 'ST']].agg({
'Trump': 'sum',
'Clinton': 'sum',
'Stein': 'sum',
'ST': 'first'
})
votes_by_state| Trump | Clinton | Stein | ST | |
|---|---|---|---|---|
| State | ||||
| Alabama | 1306925 | 718084 | 9287 | AL |
| Alaska | 0 | 0 | 0 | AK |
| Arizona | 1021154 | 936250 | 25255 | AZ |
| Arkansas | 677904 | 378729 | 9837 | AR |
| California | 3916209 | 7362490 | 220312 | CA |
| Colorado | 1137455 | 1212209 | 33147 | CO |
| Connecticut | 668266 | 884432 | 22793 | CT |
| Delaware | 185103 | 235581 | 6100 | DE |
| District of Columbia | 11553 | 260223 | 3995 | DC |
| Florida | 4605515 | 4485745 | 64019 | FL |
| Georgia | 2068623 | 1837300 | 0 | GA |
| Hawaii | 128815 | 266827 | 12727 | HI |
| Idaho | 407199 | 189677 | 8464 | ID |
| Illinois | 2118179 | 2977498 | 74112 | IL |
| Indiana | 1556220 | 1031953 | 0 | IN |
| Iowa | 798923 | 650790 | 11119 | IA |
| Kansas | 656009 | 414788 | 22698 | KS |
| Kentucky | 1202942 | 628834 | 13913 | KY |
| Louisiana | 1178004 | 779535 | 14018 | LA |
| Maine | 334838 | 354873 | 14075 | ME |
| Maryland | 873646 | 1497951 | 31839 | MD |
| Massachusetts | 1083069 | 1964768 | 46910 | MA |
| Michigan | 2279805 | 2268193 | 50700 | MI |
| Minnesota | 1322891 | 1366676 | 36957 | MN |
| Mississippi | 678457 | 462001 | 3580 | MS |
| Missouri | 1585753 | 1054889 | 25086 | MO |
| Montana | 274120 | 174521 | 7669 | MT |
| Nebraska | 485819 | 273858 | 8346 | NE |
| Nevada | 511319 | 537753 | 0 | NV |
| New Hampshire | 345789 | 348521 | 6416 | NH |
| New Jersey | 1535513 | 2021756 | 35949 | NJ |
| New Mexico | 315875 | 380724 | 9729 | NM |
| New York | 2640570 | 4143874 | 99895 | NY |
| North Carolina | 2339603 | 2162074 | 0 | NC |
| North Dakota | 216133 | 93526 | 3769 | ND |
| Ohio | 2771984 | 2317001 | 44310 | OH |
| Oklahoma | 947934 | 419788 | 0 | OK |
| Oregon | 742506 | 934631 | 45132 | OR |
| Pennsylvania | 2912941 | 2844705 | 48912 | PA |
| Rhode Island | 179421 | 249902 | 6155 | RI |
| South Carolina | 1143611 | 849469 | 12917 | SC |
| South Dakota | 227460 | 114938 | 0 | SD |
| Tennessee | 1517402 | 867110 | 15919 | TN |
| Texas | 4681590 | 3867816 | 71307 | TX |
| Utah | 452086 | 274188 | 7695 | UT |
| Vermont | 95053 | 178179 | 6748 | VT |
| Virginia | 1731156 | 1916845 | 27272 | VA |
| Washington | 1129120 | 1610524 | 51066 | WA |
| West Virginia | 486198 | 187457 | 8000 | WV |
| Wisconsin | 1403694 | 1380823 | 30934 | WI |
| Wyoming | 174248 | 55949 | 2512 | WY |
On constate que, pour l’Alaska, les résultats des trois candidats (Trump, Clinton et Stein) sont tous à 0 ; cela signifie qu’il n’y a pas de votes enregistrés pour cet État dans le fichier. Y a‑t‑il d’autres États pour lesquels les résultats sont manquants ? Si oui, lesquels ? Pour détecter ces États, on peut filtrer les lignes où les totaux de votes pour ces candidats sont égaux à zéro.
# Filtrer les lignes où les votes sont tous à zéro pour Trump, Clinton et Stein
# On utilise sum(axis=1) qui calcule la somme des votes pour chaque ligne (chaque état)
mask = votes_by_state[['Trump', 'Clinton', 'Stein']].sum(axis=1) == 0
states_with_no_votes = votes_by_state[mask]
# Afficher les états avec 0 votes
states_with_no_votes| Trump | Clinton | Stein | ST | |
|---|---|---|---|---|
| State | ||||
| Alaska | 0 | 0 | 0 | AK |
Nous constatons que les résultats pour 1 état sont absents dans notre jeu de données. Cependant, nous poursuivrons l’analyse en supposant que toutes les données nécessaires sont présentes, sans tenir compte de cette omission.
Ajoutons maintenant le nombre de grands électeurs par état. Pour cela, nous allons utiliser un dictionnaire qui contient le nombre de grands électeurs par état.
# Dictionnaire des grands électeurs par état en 2016
electoral_votes = {
"Georgia": 16,
"Texas": 38,
"Virginia": 13,
"North Carolina": 15,
"Michigan": 16,
"Arkansas": 6,
"Idaho": 4,
"Florida": 29,
"Tennessee": 11,
"Kentucky": 8,
"Alabama": 9,
"Colorado": 9,
"Missouri": 10,
"Ohio": 18,
"Pennsylvania": 20,
"South Dakota": 3,
"Louisiana": 8,
"Wisconsin": 10,
"Minnesota": 10,
"Indiana": 11,
"Maryland": 10,
"Kansas": 6,
"New York": 29,
"Mississippi": 6,
"North Dakota": 3,
"Iowa": 6,
"California": 55,
"Wyoming": 3,
"New Mexico": 5,
"Montana": 3,
"Utah": 6,
"Oklahoma": 7,
"Alaska": 3,
"Oregon": 7,
"Illinois": 20,
"Hawaii": 4,
"South Carolina": 9,
"West Virginia": 5,
"Arizona": 11,
"Maine": 4,
"New Jersey": 14,
"Connecticut": 7,
"Nebraska": 5,
"Washington": 12,
"Nevada": 6,
"Massachusetts": 11,
"Rhode Island": 4,
"New Hampshire": 4,
"Delaware": 3,
"Vermont": 3,
"District of Columbia": 3,
}
# Ajouter les grands électeurs au DataFrame
votes_by_state['ElectoralVotes'] = electoral_votes
votes_by_state| Trump | Clinton | Stein | ST | ElectoralVotes | |
|---|---|---|---|---|---|
| State | |||||
| Alabama | 1306925 | 718084 | 9287 | AL | 9 |
| Alaska | 0 | 0 | 0 | AK | 3 |
| Arizona | 1021154 | 936250 | 25255 | AZ | 11 |
| Arkansas | 677904 | 378729 | 9837 | AR | 6 |
| California | 3916209 | 7362490 | 220312 | CA | 55 |
| Colorado | 1137455 | 1212209 | 33147 | CO | 9 |
| Connecticut | 668266 | 884432 | 22793 | CT | 7 |
| Delaware | 185103 | 235581 | 6100 | DE | 3 |
| District of Columbia | 11553 | 260223 | 3995 | DC | 3 |
| Florida | 4605515 | 4485745 | 64019 | FL | 29 |
| Georgia | 2068623 | 1837300 | 0 | GA | 16 |
| Hawaii | 128815 | 266827 | 12727 | HI | 4 |
| Idaho | 407199 | 189677 | 8464 | ID | 4 |
| Illinois | 2118179 | 2977498 | 74112 | IL | 20 |
| Indiana | 1556220 | 1031953 | 0 | IN | 11 |
| Iowa | 798923 | 650790 | 11119 | IA | 6 |
| Kansas | 656009 | 414788 | 22698 | KS | 6 |
| Kentucky | 1202942 | 628834 | 13913 | KY | 8 |
| Louisiana | 1178004 | 779535 | 14018 | LA | 8 |
| Maine | 334838 | 354873 | 14075 | ME | 4 |
| Maryland | 873646 | 1497951 | 31839 | MD | 10 |
| Massachusetts | 1083069 | 1964768 | 46910 | MA | 11 |
| Michigan | 2279805 | 2268193 | 50700 | MI | 16 |
| Minnesota | 1322891 | 1366676 | 36957 | MN | 10 |
| Mississippi | 678457 | 462001 | 3580 | MS | 6 |
| Missouri | 1585753 | 1054889 | 25086 | MO | 10 |
| Montana | 274120 | 174521 | 7669 | MT | 3 |
| Nebraska | 485819 | 273858 | 8346 | NE | 5 |
| Nevada | 511319 | 537753 | 0 | NV | 6 |
| New Hampshire | 345789 | 348521 | 6416 | NH | 4 |
| New Jersey | 1535513 | 2021756 | 35949 | NJ | 14 |
| New Mexico | 315875 | 380724 | 9729 | NM | 5 |
| New York | 2640570 | 4143874 | 99895 | NY | 29 |
| North Carolina | 2339603 | 2162074 | 0 | NC | 15 |
| North Dakota | 216133 | 93526 | 3769 | ND | 3 |
| Ohio | 2771984 | 2317001 | 44310 | OH | 18 |
| Oklahoma | 947934 | 419788 | 0 | OK | 7 |
| Oregon | 742506 | 934631 | 45132 | OR | 7 |
| Pennsylvania | 2912941 | 2844705 | 48912 | PA | 20 |
| Rhode Island | 179421 | 249902 | 6155 | RI | 4 |
| South Carolina | 1143611 | 849469 | 12917 | SC | 9 |
| South Dakota | 227460 | 114938 | 0 | SD | 3 |
| Tennessee | 1517402 | 867110 | 15919 | TN | 11 |
| Texas | 4681590 | 3867816 | 71307 | TX | 38 |
| Utah | 452086 | 274188 | 7695 | UT | 6 |
| Vermont | 95053 | 178179 | 6748 | VT | 3 |
| Virginia | 1731156 | 1916845 | 27272 | VA | 13 |
| Washington | 1129120 | 1610524 | 51066 | WA | 12 |
| West Virginia | 486198 | 187457 | 8000 | WV | 5 |
| Wisconsin | 1403694 | 1380823 | 30934 | WI | 10 |
| Wyoming | 174248 | 55949 | 2512 | WY | 3 |
Éliminons la ligne correspondant à l’Alaska, car elle n’a pas de données de vote.
# Trouver le gagnant pour chaque état
votes_by_state['Winner'] = votes_by_state[['Trump', 'Clinton', 'Stein']].idxmax(axis=1)
votes_by_state| Trump | Clinton | Stein | ST | ElectoralVotes | Winner | |
|---|---|---|---|---|---|---|
| State | ||||||
| Alabama | 1306925 | 718084 | 9287 | AL | 9 | Trump |
| Arizona | 1021154 | 936250 | 25255 | AZ | 11 | Trump |
| Arkansas | 677904 | 378729 | 9837 | AR | 6 | Trump |
| California | 3916209 | 7362490 | 220312 | CA | 55 | Clinton |
| Colorado | 1137455 | 1212209 | 33147 | CO | 9 | Clinton |
| Connecticut | 668266 | 884432 | 22793 | CT | 7 | Clinton |
| Delaware | 185103 | 235581 | 6100 | DE | 3 | Clinton |
| District of Columbia | 11553 | 260223 | 3995 | DC | 3 | Clinton |
| Florida | 4605515 | 4485745 | 64019 | FL | 29 | Trump |
| Georgia | 2068623 | 1837300 | 0 | GA | 16 | Trump |
| Hawaii | 128815 | 266827 | 12727 | HI | 4 | Clinton |
| Idaho | 407199 | 189677 | 8464 | ID | 4 | Trump |
| Illinois | 2118179 | 2977498 | 74112 | IL | 20 | Clinton |
| Indiana | 1556220 | 1031953 | 0 | IN | 11 | Trump |
| Iowa | 798923 | 650790 | 11119 | IA | 6 | Trump |
| Kansas | 656009 | 414788 | 22698 | KS | 6 | Trump |
| Kentucky | 1202942 | 628834 | 13913 | KY | 8 | Trump |
| Louisiana | 1178004 | 779535 | 14018 | LA | 8 | Trump |
| Maine | 334838 | 354873 | 14075 | ME | 4 | Clinton |
| Maryland | 873646 | 1497951 | 31839 | MD | 10 | Clinton |
| Massachusetts | 1083069 | 1964768 | 46910 | MA | 11 | Clinton |
| Michigan | 2279805 | 2268193 | 50700 | MI | 16 | Trump |
| Minnesota | 1322891 | 1366676 | 36957 | MN | 10 | Clinton |
| Mississippi | 678457 | 462001 | 3580 | MS | 6 | Trump |
| Missouri | 1585753 | 1054889 | 25086 | MO | 10 | Trump |
| Montana | 274120 | 174521 | 7669 | MT | 3 | Trump |
| Nebraska | 485819 | 273858 | 8346 | NE | 5 | Trump |
| Nevada | 511319 | 537753 | 0 | NV | 6 | Clinton |
| New Hampshire | 345789 | 348521 | 6416 | NH | 4 | Clinton |
| New Jersey | 1535513 | 2021756 | 35949 | NJ | 14 | Clinton |
| New Mexico | 315875 | 380724 | 9729 | NM | 5 | Clinton |
| New York | 2640570 | 4143874 | 99895 | NY | 29 | Clinton |
| North Carolina | 2339603 | 2162074 | 0 | NC | 15 | Trump |
| North Dakota | 216133 | 93526 | 3769 | ND | 3 | Trump |
| Ohio | 2771984 | 2317001 | 44310 | OH | 18 | Trump |
| Oklahoma | 947934 | 419788 | 0 | OK | 7 | Trump |
| Oregon | 742506 | 934631 | 45132 | OR | 7 | Clinton |
| Pennsylvania | 2912941 | 2844705 | 48912 | PA | 20 | Trump |
| Rhode Island | 179421 | 249902 | 6155 | RI | 4 | Clinton |
| South Carolina | 1143611 | 849469 | 12917 | SC | 9 | Trump |
| South Dakota | 227460 | 114938 | 0 | SD | 3 | Trump |
| Tennessee | 1517402 | 867110 | 15919 | TN | 11 | Trump |
| Texas | 4681590 | 3867816 | 71307 | TX | 38 | Trump |
| Utah | 452086 | 274188 | 7695 | UT | 6 | Trump |
| Vermont | 95053 | 178179 | 6748 | VT | 3 | Clinton |
| Virginia | 1731156 | 1916845 | 27272 | VA | 13 | Clinton |
| Washington | 1129120 | 1610524 | 51066 | WA | 12 | Clinton |
| West Virginia | 486198 | 187457 | 8000 | WV | 5 | Trump |
| Wisconsin | 1403694 | 1380823 | 30934 | WI | 10 | Trump |
| Wyoming | 174248 | 55949 | 2512 | WY | 3 | Trump |
Qui a obtenu le plus d’états indépendamment du nombre total de voix ou de grands électeurs ?
Bonus : on peut afficher sur une carte choroplèthe le résultat des élections. On colore chaque État selon le candidat qui a remporté le plus de voix (en effet, aux États-Unis, le président est élu par un collège électoral où chaque État dispose d’un certain nombre de grands électeurs, en général proportionnel au nombre d’habitants).
# Transformer l'index en colonne pour plotly
votes_map = votes_by_state.reset_index()
# Fonction formatage français pour l'affichage des nombres avec des espaces comme séparateurs de milliers
fmt = lambda n: f"{n:,}".replace(",", " ")
# Carte choroplèthe
fig = px.choropleth(
votes_map,
locations='ST',
locationmode='USA-states',
color='Winner',
hover_name='State',
hover_data={
'Winner': True,
'Grandes Electeurs': votes_map['ElectoralVotes'].apply(fmt),
'Trump votes': votes_map['Trump'].apply(fmt),
'Clinton votes': votes_map['Clinton'].apply(fmt),
'Stein votes': votes_map['Stein'].apply(fmt),
'ST': False,
},
color_discrete_map={'Trump':'red','Clinton':'blue','Stein':'green'},
scope='usa',
title='Résultats des élections US 2016 par État'
)
fig.show()Unable to display output for mime type(s): application/vnd.plotly.v1+jsonOn regarde juste les trois lignes associées aux états du Michigan, de Pennsylvanie et du Wisconsin.
| Trump | Clinton | Stein | ST | ElectoralVotes | Winner | |
|---|---|---|---|---|---|---|
| State | ||||||
| Michigan | 2279805 | 2268193 | 50700 | MI | 16 | Trump |
| Wisconsin | 1403694 | 1380823 | 30934 | WI | 10 | Trump |
| Pennsylvania | 2912941 | 2844705 | 48912 | PA | 20 | Trump |
# Résultats finaux
final_results = votes_by_state.pivot_table(index='Winner', values='ElectoralVotes', aggfunc='sum')
# Ajouter le nombre de votes pour chaque candidat, le pourcentage de grands électeurs et le pourcentage de votes
final_results.insert(0, 'Votes', votes_by_state[['Trump', 'Clinton', 'Stein']].sum())
final_results.insert(1, 'PercentageVotes' , final_results['Votes'] / final_results['Votes'].sum() * 100)
final_results['PercentageElectoralVotes'] = final_results['ElectoralVotes'] / final_results['ElectoralVotes'].sum() * 100
final_results| Votes | PercentageVotes | ElectoralVotes | PercentageElectoralVotes | |
|---|---|---|---|---|
| Winner | ||||
| Clinton | 62426228 | 50.551307 | 233 | 43.551402 |
| Trump | 61064602 | 49.448693 | 302 | 56.448598 |
Sur Wikipedia on peut trouver les résultats suivants pour les élections :
- Hillary Clinton : 65 853 514 voix, 232 grands électeurs
- Donald Trump : 62 984 828 voix, 306 grands électeurs
Nos données ne sont donc pas complètes.
On voit que Trump a obtenu 305 grands électeurs contre 233 pour Clinton. Il a donc été élu président des USA. Cependant, si les résultats dans les états du Michigan, de Pennsylvanie et du Wisconsin avaient été différents, Clinton aurait obtenu plus de grands électeurs (et Trump moins). Aurait-elle été élue ?
# Calcul de la somme des grands électeurs des états impliqués dans la triche éventuelle
si_triche_verifiee = electoral_votes['Michigan'] + electoral_votes['Wisconsin'] + electoral_votes['Pennsylvania']
# Ajuster les résultats de Trump et Clinton
new_Trump = final_results.loc['Trump','ElectoralVotes'] - si_triche_verifiee # Déduire les grands électeurs pour Trump
new_Clinton = final_results.loc['Clinton','ElectoralVotes'] + si_triche_verifiee # Ajouter les grands électeurs à Clinton
# Afficher les résultats ajustés
display(Markdown("**Résultats ajustés si la triche est confirmée :**"))
display(Markdown(f"- Trump : {new_Trump} grands électeurs"))
display(Markdown(f"- Clinton : {new_Clinton} grands électeurs"))Résultats ajustés si la triche est confirmée :
- Trump : 256 grands électeurs
- Clinton : 279 grands électeurs
5 Sélection des données dans les États du Michigan, de la Pennsylvanie et du Wisconsin
Nous allons examiner les données relatives aux États du Michigan, du Wisconsin et de la Pennsylvanie. Nous nous intéressons aux comtés où chaque candidat a obtenu plus de 10 voix.
mask1 = (Tot['State'] == 'Michigan') | (Tot['State'] == 'Wisconsin') | (Tot['State'] == 'Pennsylvania')
# mask1 = Tot['State'].isin(['Michigan', 'Wisconsin', 'Pennsylvania'])
mask2 = (Tot['Trump'] >= 10) & (Tot['Clinton'] >= 10) & (Tot['Stein'] >= 10)
# Nouveau DataFrame avec les lignes sélectionnées
Sel = Tot[mask1 & mask2].copy()
Sel| State | ST | Trump | Clinton | Stein | |
|---|---|---|---|---|---|
| 6 | Michigan | MI | 21635 | 16490 | 379 |
| 12 | Michigan | MI | 2158 | 1156 | 49 |
| 20 | Pennsylvania | PA | 22676 | 6849 | 136 |
| 26 | Wisconsin | WI | 17310 | 18524 | 583 |
| 33 | Wisconsin | WI | 31044 | 17391 | 449 |
| ... | ... | ... | ... | ... | ... |
| 3057 | Wisconsin | WI | 39010 | 26476 | 641 |
| 3090 | Pennsylvania | PA | 257488 | 363017 | 5021 |
| 3105 | Wisconsin | WI | 46620 | 42506 | 834 |
| 3125 | Michigan | MI | 7228 | 3973 | 116 |
| 3139 | Michigan | MI | 224589 | 176238 | 3886 |
220 rows × 5 columns
Combien de bureaux de vote sont concernés par ces critères ?
6 Analyse des données
Nous allons ajouter, pour chaque candidat, une colonne contenant le deuxième chiffre du nombre de voix :
for candidat in ["Trump", "Clinton", "Stein"]:
Sel.loc[:, candidat + '_2chiffre'] = Sel[candidat].apply(lambda x: int(str(x)[1]))
Sel| State | ST | Trump | Clinton | Stein | Trump_2chiffre | Clinton_2chiffre | Stein_2chiffre | |
|---|---|---|---|---|---|---|---|---|
| 6 | Michigan | MI | 21635 | 16490 | 379 | 1 | 6 | 7 |
| 12 | Michigan | MI | 2158 | 1156 | 49 | 1 | 1 | 9 |
| 20 | Pennsylvania | PA | 22676 | 6849 | 136 | 2 | 8 | 3 |
| 26 | Wisconsin | WI | 17310 | 18524 | 583 | 7 | 8 | 8 |
| 33 | Wisconsin | WI | 31044 | 17391 | 449 | 1 | 7 | 4 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 3057 | Wisconsin | WI | 39010 | 26476 | 641 | 9 | 6 | 4 |
| 3090 | Pennsylvania | PA | 257488 | 363017 | 5021 | 5 | 6 | 0 |
| 3105 | Wisconsin | WI | 46620 | 42506 | 834 | 6 | 2 | 3 |
| 3125 | Michigan | MI | 7228 | 3973 | 116 | 2 | 9 | 1 |
| 3139 | Michigan | MI | 224589 | 176238 | 3886 | 2 | 7 | 8 |
220 rows × 8 columns
On crée un DataFrame avec l’histogramme des secondes chiffres par candidat. Autrement dit, on compte le nombre de fois où chaque chiffre est apparu en deuxième position dans les nombres de votes.
Pour cela on utilise apply qui applique une fonction donnée (ici, pd.Series.value_counts) à chaque colonne du DataFrame résultant. La fonction pd.Series.value_counts compte les occurrences uniques des valeurs dans une série (ici une colonne) et renvoie une série dont les indices sont les valeurs uniques présentes dans la colonne d’origine. Ces valeurs sont triées par défaut en ordre décroissant de fréquence.
# Première méthode
# Trump_histo = Sel['Trump_2chiffre'].value_counts()
# Clinton_histo = Sel['Clinton_2chiffre'].value_counts()
# Stein_histo = Sel['Stein_2chiffre'].value_counts()
Trump_histo = Sel['Trump_2chiffre'].value_counts(normalize=True)
Clinton_histo = Sel['Clinton_2chiffre'].value_counts(normalize=True)
Stein_histo = Sel['Stein_2chiffre'].value_counts(normalize=True)
His = pd.DataFrame({'Trump_histo': Trump_histo,
'Clinton_histo': Clinton_histo,
'Stein_histo': Stein_histo})
His = His.rename_axis('Chiffre')
display(His)
# Deuxième méthode
# cols = ['Trump_2chiffre', 'Clinton_2chiffre', 'Stein_2chiffre']
# # His = Sel[cols].apply(pd.Series.value_counts) / nb_bureaux
# His = Sel[cols].apply(lambda x: x.value_counts(normalize=True))
# His = His.rename_axis('Chiffre')
# His = His.rename(columns={"Trump_2chiffre": "Trump_histo", "Clinton_2chiffre": "Clinton_histo", "Stein_2chiffre": "Stein_histo"})
# display(His)| Trump_histo | Clinton_histo | Stein_histo | |
|---|---|---|---|
| Chiffre | |||
| 0 | 0.100000 | 0.086364 | 0.109091 |
| 1 | 0.140909 | 0.113636 | 0.136364 |
| 2 | 0.104545 | 0.122727 | 0.063636 |
| 3 | 0.109091 | 0.090909 | 0.095455 |
| 4 | 0.113636 | 0.104545 | 0.163636 |
| 5 | 0.104545 | 0.090909 | 0.027273 |
| 6 | 0.109091 | 0.122727 | 0.109091 |
| 7 | 0.095455 | 0.109091 | 0.063636 |
| 8 | 0.063636 | 0.095455 | 0.104545 |
| 9 | 0.059091 | 0.063636 | 0.127273 |
On ajoute la colonne Benford avec les effectifs théoriques des seconde chiffres attendus par la loi de Benford :
# On ajoute la colonne Benford avec les effectifs théoriques
# His['Benford'] = { Chiffre : round(p(Chiffre)*nb_bureaux) for Chiffre in His.index}
His['Benford'] = { Chiffre : p(Chiffre) for Chiffre in His.index}
His| Trump_histo | Clinton_histo | Stein_histo | Benford | |
|---|---|---|---|---|
| Chiffre | ||||
| 0 | 0.100000 | 0.086364 | 0.109091 | 0.119679 |
| 1 | 0.140909 | 0.113636 | 0.136364 | 0.113890 |
| 2 | 0.104545 | 0.122727 | 0.063636 | 0.108821 |
| 3 | 0.109091 | 0.090909 | 0.095455 | 0.104330 |
| 4 | 0.113636 | 0.104545 | 0.163636 | 0.100308 |
| 5 | 0.104545 | 0.090909 | 0.027273 | 0.096677 |
| 6 | 0.109091 | 0.122727 | 0.109091 | 0.093375 |
| 7 | 0.095455 | 0.109091 | 0.063636 | 0.090352 |
| 8 | 0.063636 | 0.095455 | 0.104545 | 0.087570 |
| 9 | 0.059091 | 0.063636 | 0.127273 | 0.084997 |
On affiche la distribution des seconds chiffres par candidat.
# His.plot(figsize=(15,5))
# plt.xticks(range(10));
# His.plot.bar(figsize=(15,5));
plt.figure(figsize=(10,5))
plt.subplot(2,2,1)
sns.barplot(data=His, x=His.index, y='Trump_histo', color='blue', alpha=0.5)
plt.subplot(2,2,2)
sns.barplot(data=His, x=His.index, y='Clinton_histo', color='red', alpha=0.5)
plt.subplot(2,2,3)
sns.barplot(data=His, x=His.index, y='Stein_histo', color='green', alpha=0.5)
plt.subplot(2,2,4)
sns.barplot(data=His, x=His.index, y='Benford', color='black', alpha=0.5)
plt.tight_layout();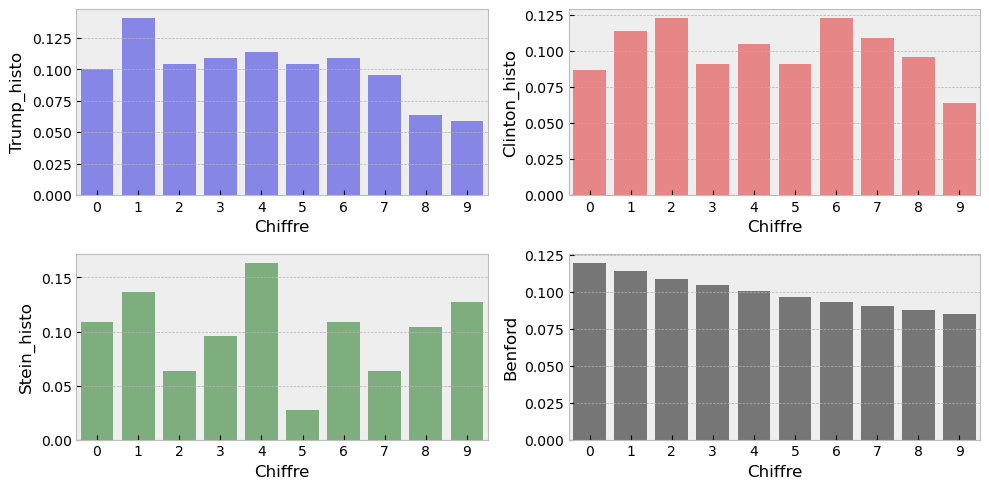
Pour chaque candidat, on calcule la distance euclidienne entre les effectifs théoriques et les effectifs de chaque candidats. Si A et B sont deux listes de même longueur, la distance euclidienne entre A et B est donnée par : \[\text{dist}(A,B) = || A-B ||_2 =\sqrt{\sum_{c=0}^9 \left( A_c - B_c \right)^2}.\] Dans numpy, cela se calcule simplement par np.linalg.norm(A-B).
# Dictionnaire pour stocker les distances
D = {}
# Pour chaque candidat, calculer la norme euclidienne entre les colonnes
for candidat in ["Trump_histo", "Clinton_histo", "Stein_histo"]:
D[candidat] = np.linalg.norm(His[candidat] - His['Benford'])
D{'Trump_histo': 0.05398891120857391,
'Clinton_histo': 0.05714784909840473,
'Stein_histo': 0.12083530757488783}Selon ces valeurs, le candidat Stein semble légitime à contester les résultats. Mais est-ce effectivement si rare d’obtenir une telle distance ?
7 Bonus : Simulation pour la détection d’éventuelles anomalies
Pour commencer, on simule 10 votations qui suivent la loi de Benford.
# Créer une copie de Sel et ajouter une colonne avec des chiffres simulés selon FB
Sel_copy = Sel.copy()
for test in ["test"+str(i) for i in range(1,11)]:
# Générer nb_bureaux chiffres aléatoires selon la distribution FB
Sel_copy[test] = np.random.choice(range(10), size=nb_bureaux, p=FB)
# Calculer les effectifs pour la colonne simulée
# His[test] = Sel_copy[test].value_counts()
His[test] = Sel_copy[test].value_counts(normalize=True)
# Calculer la norme entre les effectifs simulés et ceux de Benford
D[test] = np.linalg.norm(His[test] - His['Benford'])
# Affichage des distances un peu plus joli
pd.DataFrame( index=D.keys(), data=D.values(), columns=['Distance']).sort_values(by='Distance')| Distance | |
|---|---|
| test5 | 0.045230 |
| test2 | 0.052289 |
| Trump_histo | 0.053989 |
| test8 | 0.055313 |
| test7 | 0.056501 |
| Clinton_histo | 0.057148 |
| test3 | 0.060035 |
| test6 | 0.060576 |
| test9 | 0.060761 |
| test10 | 0.062428 |
| test1 | 0.073702 |
| test4 | 0.084107 |
| Stein_histo | 0.120835 |
Bien que la valeur semble effectivement élevée pour Stein, il est possible que cette valeur ne soit pas si rares. En effet, dans nos 10 simulations, nous avons parfois obtenu des valeurs de distance euclidienne presque aussi élevées que celles observées pour Stein. Pour comprendre s’il s’agit d’evenement rares, on simule \(10^4\) fois pour voir combien de fois D['test']>D[candidat] :
distance_Stein = D['Stein_histo']
distance_Clinton = D['Clinton_histo']
distance_Trump = D['Trump_histo']
cpt_Stein = 0
cpt_Clinton = 0
cpt_Trump = 0
N = 10_000
for i in range(N):
test = pd.Series(np.random.choice(range(10), size=nb_bureaux, p=FB)) # le chiffre i apparait avec une probabilité FB[i] et ce pour 220 bureaux de vote
# test_histo = test.value_counts()
test_histo = test.value_counts(normalize=True)
D_test = np.linalg.norm( test_histo - His['Benford'])
if D_test > distance_Stein:
cpt_Stein += 1
if D_test > distance_Clinton:
cpt_Clinton += 1
if D_test > distance_Trump:
cpt_Trump += 1
print(f"""Sur {N} simulations,
• {cpt_Stein} fois on a obtenu une distance supérieure à celle de Stein, soit {cpt_Stein/N*100:.2f}% des fois;
• {cpt_Clinton} fois on a obtenu une distance supérieure à celle de Clinton, soit {cpt_Clinton/N*100:.2f}% des fois;
• {cpt_Trump} fois on a obtenu une distance supérieure à celle de Trump, soit {cpt_Trump/N*100:.2f}% des fois.
""")Sur 10000 simulations,
• 0 fois on a obtenu une distance supérieure à celle de Stein, soit 0.00% des fois;
• 6161 fois on a obtenu une distance supérieure à celle de Clinton, soit 61.61% des fois;
• 6968 fois on a obtenu une distance supérieure à celle de Trump, soit 69.68% des fois.
8 Conclusion
La visualisation de la distribution des effectifs du second chiffre des résultats de vote dans les bureaux des états du pour chaque candidat à montré une anomalie. Les résultats ne sont pas conforme à la loi théorique de Benford. De plus, très peu de simulations ont donné des écarts encore plus importants pour le candidat Stein, autrement dit c’est très rare de voir une telle distribution.