De nombreux processus, en particulier ceux dépendant du temps, peuvent être décrits par des Équations Différentielles Ordinaires (EDO), tels que la dynamique des systèmes d’ingénierie, la physique quantique, les réactions chimiques, la modélisation des systèmes biologiques et la dynamique des populations.
Les EDO ont exactement une variable indépendante \(t\) (souvent, mais pas toujours, représentant le temps).
Le type le plus simple d’EDO a un degré de liberté, \(y\), qui dépend du temps \(t\), c’est-à-dire \(y = y(t)\) (par exemple, la température en fonction du temps, la distance parcourue par une voiture en fonction du temps, etc.).
En général, un vecteur \(y\) avec \(k\) composantes peut dépendre de la variable indépendante \(t\) : il s’agit d’un système d’équations différentielles ordinaires avec \(k\) degrés de liberté.
La solution de l’EDO est la fonction \(y(t)\).
Typiquement, nous disposons de :
une valeur initiale \(y_0\) de \(y(t)\) à un certain temps \(t_0\),
l’EDO elle-même qui relie le changement de \(y\) par rapport à \(t\) à une fonction \(\varphi(t, y)\), c’est-à-dire \(y'(t) = \varphi(t, y(t))\).
Exemple : rechercher la solution \(y(t)\) de \(t_0 = 0\) à \(t = 2\) de \(y'(t) = -2y(t)\) avec \(y_0 = y(t_0) = 17\). La solution exacte existe, est unique, et est \(y(t) = 17 \exp(-2t)\).
La résolution formelle d’équations différentielles s’avère très compliquée et limitée : la plupart des problèmes ne peuvent être qu’approchés.
On ne peut expliciter des solutions analytiques que pour des équations différentielles ordinaires très particulières. Par exemple :
dans certains cas, on ne peut exprimer la solution que sous forme implicite. C’est le cas par exemple de l’EDO \(y'(t)=\dfrac{y(t)-t}{y(t)+t}\) dont les solutions vérifient la relation implicite \(
\frac{1}{2}\ln(t^2+y^2(t))+\arctan\left( \frac{y(t)}{t} \right)=C,
\) où \(C\) est une constante arbitraire ;
dans d’autres cas, on ne parvient même pas à représenter la solution sous forme implicite.
C’est le cas par exemple de l’EDO \(y'(t)=e^{-t^2}\) dont les solutions ne peuvent pas s’écrire comme composition de fonctions élémentaires.
Lorsqu’on ne connait pas de solution exacte à un problème de Cauchy qui admet une et une seule solution, on essaye d’en avoir une bonne approximation par des méthodes numériques.
1 Position du problème
Problème de Cauchy:
trouver une fonction \(y \colon I\subset \mathbb{R} \to \mathbb{R}\) définie sur un intervalle \(I\) telle que \(
\begin{cases}
y'(t) = \varphi(t,y(t)), &\forall t \in I=]t_0,T[,\\
y(t_0) = y_0,
\end{cases}
\) avec \(y_0\) une valeur donnée et supposons que l’on ait montré l’existence et l’unicité d’une solution \(y\) pour \(t\in I\).
L’idée la plus simple pour résoudre de manière approchée un problème de Cauchy est de discrétiser l’intervalle de temps avec un pas \(h\) et d’approcher la dérivée temporelle sur chaque sous-intervalle de longueur \(h\).
Pour \(h>0\) soit \(t_n\equiv t_0+nh\) avec \(n=0,1,2,\dots,N\) une suite de \(N+1\) nœuds de \(I\) induisant une discrétisation de \(I\) en \(N\) sous-intervalles \(I_n=[t_n;t_{n+1}]\) chacun de longueur \(h=\frac{T-t_0}{N}>0\) (appelé le pas de discrétisation).
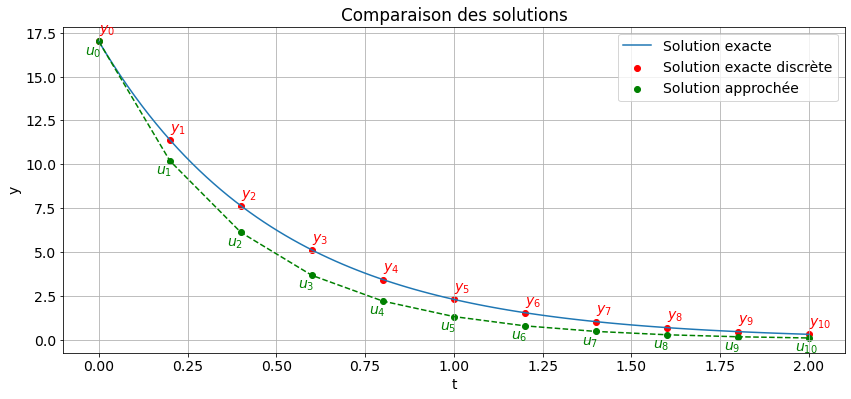
Pour chaque nœud \(t_n\), on cherche la valeur inconnue \(u_n\) qui approche la valeur exacte \(y_n\equiv y(t_n)\).
L’ensemble de \(N+1\) valeurs \(\{t_0, t_1=t_0+h,\dots , t_{N}=T \}\) représente les points de la discrétisation.
L’ensemble de \(N+1\) valeurs \(\{y_0, y_1,\dots , y_{N} \}\) représente la solution exacte discrète.
L’ensemble de \(N+1\) valeurs \(\{u_0 = y_0, u_1,\dots , u_{N} \}\) représente la solution numérique.
Code
import numpy as npimport matplotlib.pyplot as pltplt.rcParams.update({<span class="st">'font.size'</span>: <span class="dv">14</span>})def euler_explicit(f, y0, t_values): h = t_values[1] - t_values[0] y_values = np.zeros_like(t_values) y_values[0] = y0for i inrange(len(t_values) -1): y_values[i+1] = y_values[i] + h * f(t_values[i], y_values[i])return y_valuesdef plot_solutions(n, show_exact_line=True, show_exact_points=True, show_approx_points=True): t0 =0 tn =2 y0 =17 phi =lambda t, y : -2* y exact_solution =lambda t : 17* np.exp(-2* t)# Calcul des solutions t_exact = np.linspace(t0, tn, 100) # pour la solution exacte continue y_exact = exact_solution(t_exact) t_exact_discrete = np.linspace(t0, tn, n+1) # pour les solutions exacte et approchée discrètes y_exact_discrete = exact_solution(t_exact_discrete) y_approx = euler_explicit(phi, y0, t_exact_discrete) plt.figure(figsize=(14, 6)) plt.xlabel('t') plt.ylabel('y') plt.title('Comparaison des solutions')if show_exact_line: plt.plot(t_exact, y_exact, label='Solution exacte')if show_exact_points: plt.scatter(t_exact_discrete, y_exact_discrete, color='red', label='Solution exacte discrète')for i inrange(len(y_exact_discrete)): plt.annotate('$y_{'</span><span class="op">+</span><span class="bu">str</span>(i)<span class="op">+</span><span class="st">'}$', (t_exact_discrete[i], y_exact_discrete[i] +0.5), color='red')if show_approx_points: plt.plot(t_exact_discrete, y_approx, 'g--') plt.scatter(t_exact_discrete, y_approx, color='green', label='Solution approchée')for i inrange(len(y_approx)): plt.annotate('$u_{'</span><span class="op">+</span><span class="bu">str</span>(i)<span class="op">+</span><span class="st">'}$', (t_exact_discrete[i]-0.04, y_approx[i] -0.75), color='green') plt.legend() plt.grid(True) plt.show()# si interactif# from ipywidgets import interact, widgets# interact(plot_solutions, n=widgets.IntSlider(min=5, max=20, step=1, value=10), # show_exact_line=True, show_exact_points=False, show_approx_points=False);# si non interactifplot_solutions(10, show_exact_line=True, show_exact_points=True, show_approx_points=True);
2 Construction élémentaire des méthodes d’Euler explicite et implicite
Une méthode classique, la méthode d’Euler explicite (ou progressive, de l’anglais forward), est obtenue en considérant l’équation différentielle en chaque nœud \(t_n\) et en remplaçant la dérivée exacte \(y'(t_n)\) par le taux d’accroissement \(
\varphi(t_n,y(t_n))=y'(t_n)=\frac{y(t_{n}+h)-y(t_n)}{h}+\mathscr{O}(h).
\) Cela permet de construire une solution numérique par une suite récurrente:
On peut donner une intérprétation géométrique de la méthode d’Euler explicite : en un point donné \(t_n\), on avance d’un pas \(h\) le long de la droite tangente à la solution (inconnue).
De même, en utilisant le taux d’accroissement \(
\varphi(t_{n+1},y(t_{n+1}))=y'(t_{n+1})\simeq\frac{y(t_{n+1})-y(t_n)}{h}
\) pour approcher \(y'(t_{n+1})\), on obtient la méthode d’Euler implicite (ou rétrograde, de l’anglais backward)
Ces deux méthodes sont dites à un pas: pour calculer la solution numérique \(u_{n+1}\) au nœud \(t_{n+1}\), on a seulement besoin des informations disponibles au nœud précédent \(t_n\). Plus précisément,
pour la méthode d’Euler progressive, \(u_{n+1}\) ne dépend que de la valeur \(u_n\) calculée précédemment,
pour la méthode d’Euler rétrograde, \(u_{n+1}\) dépend aussi “de lui-même” à travers la valeur de \(\varphi(t_{n+1},u_{n+1})\).
C’est pour cette raison que la méthode d’Euler progressive est dite explicite tandis que la méthode d’Euler rétrograde est dite implicite.
Les méthodes implicites sont plus coûteuses que les méthodes explicites car, si la fonction \(\varphi\) est non linéaire, un problème non linéaire doit être résolu à chaque temps \(t_{n+1}\) pour calculer \(u_{n+1}\). Néanmoins, nous verrons que les méthodes implicites jouissent de meilleures propriétés de stabilité que les méthodes explicites.
3 Implémentation des schémas d’Euler explicite et implicite
Voyons un exemple complet.
Exemple: considérons le problème de Cauchy
trouver la fonction \(y \colon I\subset \mathbb{R} \to \mathbb{R}\) définie sur l’intervalle \(I=[0,1]\) telle que \(
\begin{cases}
y'(t) = 2ty(t), &\forall t \in I=[0,1],\\
y(0) = 1.
\end{cases}
\)
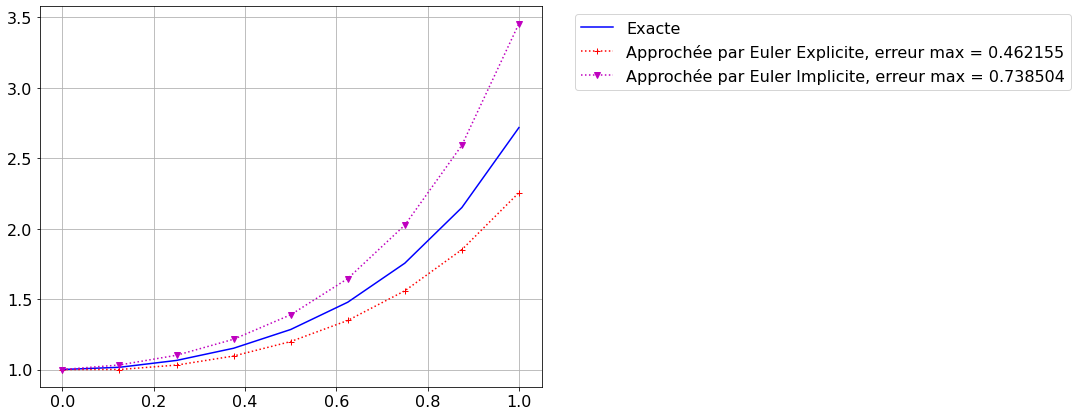
Sachant que la solution est \(y(t)=e^{t^2}\), estimer la qualité du schéma en affichant la plus grande erreur commise (en valeur absolue).
On commence par importer
la fonction fsolve du module scipy.optimize pour résoudre les équations implicites présentes dans le schéma implicite.
le module matplotlib et le module numpy:
soit en important séparemment matplotlib.pyplot et numpy (avec les alias classiques);
soit en important juste matplotlib.pylab, ce qui importe à la fois matplotlib et numpy (avec par exemple l’alias commun pyl ou sans alias si on utilise *).
Rappels: numpy rédéfinit toutes les fonctions mathématiques du module math et ces fonctions sont vectorisées (e.g. on pourra écrire directement yy=sin(xx) avec xx une liste/tuple/array au lieu d’écrire yy=[sin(x) for x in xx]).
Code
%reset -f%matplotlib inlinefrom scipy.optimize import fsolve # pour les schémas implicites#from matplotlib.pylab import *import numpy as npimport matplotlib.pyplot as plt# plt.rcdefaults()plt.rcParams.update({<span class="st">'font.size'</span>: <span class="dv">16</span>})
On initialise le problème de Cauchy
Code
t0 =0tfinal =1y0 =1
On définit l’équation différentielle : phi est une fonction python qui contient la fonction mathématique \(\varphi\colon [t_0,T]\times\mathbb{R}\to\mathbb{R}\) définie par \(\varphi(t, y)=2ty\). Bien noter que \(\varphi\) dépend de deux variables: \(t\) et \(y\). Dans l’EDO on a \(\varphi(t,y(t))\): il s’agit d’une fonction d’une seule variable obtenue par composition de la fonction \(\varphi\) avec la fonction \(t\mapsto y(t)\).
Code
phi =lambda t, y : 2*y*t
On introduit la discrétisation: les nœuds d’intégration \([t_0,t_1,\dots,t_{N}]\) sont contenus dans le vecteur tt.
On a \(N+1\) points espacés de \(h=\frac{t_N-t_0}{N}\).
Code
N =8tt = np.linspace(t0,tfinal,N+1)
On écrit les schémas numériques : les valeurs \([u_0,u_1,\dots,u_{N}]\) pour chaque méthode sont contenues dans le vecteur uu.
\(u_{n+1}\) est solution de l’équation \(x=u_n+h\varphi(t_{n+1},x)\), c’est-à-dire un zéro de la fonction (en général non linéaire) \(x\mapsto -x+u_n+h\varphi(t_{n+1},x)\)
la fonction fsolve du module scipy.optimize requiert deux paramètres : une fonction et un point de départ. Elle renvoie une liste avec la valeur du zéro approché (c’est une liste, car fsolve résout un système, ici avec une seule équation).
Code
def euler_regressif(phi,tt,y0): h = tt[1]-tt[0] uu = np.zeros_like(tt) # array de même taille que tt uu[0] = y0for n inrange(len(tt)-1): temp = fsolve( lambda x: -x+uu[n]+h*phi(tt[n+1],x) , uu[n] ) uu[n+1] = temp[0] # fsolve renvoie un array qui ne contient qu'un seul élémentreturn uu
Comme on la connait, on définit la solution exacte pour calculer les erreurs:
Code
sol_exacte =lambda t : y0*np.exp(t**2)yy = sol_exacte(tt) # = [sol_exacte(t) for t in tt]
On compare les graphes des solutions exacte (en bleu) et approchées (en rouge) et on affiche le maximum de l’erreur:
Code
plt.figure(figsize=(9, 7))plt.plot(tt,yy ,'b-',label='Exacte')plt.plot(tt,uu_ep,'r:+',label=f'Approchée par Euler Explicite, erreur max = {</span><span class="bu">max</span>(np.<span class="bu">abs</span>(uu_ep<span class="op">-</span>yy))<span class="sc">:g}')plt.plot(tt,uu_er,'m:v',label=f'Approchée par Euler Implicite, erreur max = {</span><span class="bu">max</span>(np.<span class="bu">abs</span>(uu_er<span class="op">-</span>yy))<span class="sc">:g}')plt.grid()plt.legend(bbox_to_anchor=(1.05, 1), loc='upper left');
4 Convergence théorique des schémas d’Euler
Définition: schéma convergent
Une méthode numérique est convergente si \(
|y_n-u_n|\le C(h)\xrightarrow[h\to0]{}0 \qquad\forall n=0,\dots,N
\)
Définition: ordre de convergence
Si \(C(h) = \mathcal{O}(h^p)\) pour \(p > 0\), on dit que la convergence de la méthode est d’ordre \(p\).
Remarque: \(N\to+\infty\) lorsque \(h\to0\).
Soit \(u_{n+1}^*\) la solution numérique au temps \(t_{n+1}\) qu’on obtiendrait en insérant la solution exacte dans le schéma (par exemple, pour la méthode d’Euler explicite on a \(u_{n+1}^*\equiv y_{n} + h\varphi(t_{n}, y_{n})\)). Pour vérifier qu’une méthode converge, on écrit l’erreur ainsi \(
e_n \equiv y_n - u_n = (y_n - u_n^*) + (u_n^* - u_n).
\) Si les deux termes \((y_n - u_n^*)\) et \((u_n^* - u_n)\) tendent vers zéro quand \(h \to 0\) alors la méthode converge.
Définition: erreur de troncature
La quantité \(
\tau_{n+1}(h)\equiv\frac{y_{n+1}-u_{n+1}^*}{h}
\) est appelée erreur de troncature locale. Elle représente (à un facteur \(1/h\) près) l’erreur qu’on obtient en insérant la solution exacte dans le schéma numérique.
L’erreur de troncature globale (ou plus simplement l’erreur de troncature) est définie par \(
\tau(h)=\max_{n=0,\dots,N}|\tau_n(h)|.
\)
Définition: consistance
Si \(\lim_{h\to0} \tau (h) = 0\) on dit que la méthode est consistante.
Définition: ordre de consistance
On dit qu’elle est consistante d’ordre \(p\) si \(\tau (h) = \mathcal{O}(h^p)\) pour un certain \(p\ge1\).
Remarque: la propriété de consistance est nécessaire pour avoir la convergence. En effet, si elle n’était pas consistante, la méthode engendrerait à chaque itération une erreur qui ne tendrait pas vers zéro avec \(h\). L’accumulation de ces erreurs empêcherait l’erreur globale de tendre vers zéro quand \(h \to 0\).
Proposition.
Si la fonction \(\varphi\) est lipschitzienne de constante \(L\) par rapport à sa deuxième variable, la méthode d’Euler explicite appliquée au problème de Cauchy \(y'(t)=\varphi(t,y(y))\) pour \(t\in[t_0;T]\) et \(y(t_0)=y_0\) est convergente d’ordre 1.
Preuve
On étudie séparément l’erreur de consistance et l’accumulation de ces erreurs. On en déduit ensuite la convergence.
Terme \(y_n - u_n^*\) (erreur de consistance).
Il représente l’erreur engendrée par une seule itération de la méthode d’Euler explicite.
En supposant que la dérivée seconde de \(y\) existe et est continue, on écrit le développement de Taylor de \(y\) au voisinage de \(t_n\): \(
y(t_{n+1})=y(t_n)+hy'(t_n)+\frac{h^2}{2}y''(\eta_n)
\) où \(\eta_n\) est un point de l’intervalle \(]t_n;t_{n+1}[\). Donc il existe \(\eta_n \in ]t_n, t_{n+1}[\) tel que \(
y_{n+1}-u_{n+1}^*
=y_{n+1}-\Big(y_{n} + h\varphi(t_{n}, y_{n})\Big)=y_{n+1}-y_{n} - hy'(t_n)=\frac{h^2}{2}y''(\eta_n).
\) L’erreur de troncature de la méthode d’Euler explicite est donc de la forme \(
\tau(h)=M\frac{h}{2},
\qquad
M\equiv\max_{t\in [t_0,T]}|y''(t)|.
\) On en déduit que \(\lim_{h\to0} \tau (h) = 0\): la méthode est consistante.
Terme \(u_{n+1}^* - u_{n+1}\) (accumulation des erreurs).
Il représente la propagation de \(t_{n}\) à \(t_{n+1}\) de l’erreur accumulée au temps précédent \(t_{n}\). On a \(u_{n+1}^* - u_{n+1} =
\Big(y_n + h \varphi(t_n, y_n)\Big)-\Big(u_n + h \varphi(t_n, y_n)\Big)=e_n+h\Big( \varphi(t_n,y_n)-\varphi(t_n,u_n) \Big). \) Comme \(\varphi\) est lipschitzienne par rapport à sa deuxième variable, on a \(
|u_{n+1}^{*} - u_{n+1}|\le (1 + hL)|e_{n}|.
\)
Convergence.
Comme \(e_0 = 0\), les relations précédentes donnent \(\begin{align*}
|e_n|
&\le
|y_n - u_n^*| + |u_n^* - u_n|
\\
&\le
h|\tau_n(h)| + (1+hL)|e_{n-1}|
\\
&\le
h|\tau_n(h)| + (1+hL)\left( h|\tau_{n-1}(h)| + (1+hL)|e_{n-2}| \right)|
\\
&\le
\left( 1+(1+hL)+\dots+(1+hL)^{n-1} \right)h\tau(h)
\\
&=\left(\sum_{i=0}^{n-1}(1+hL)^i\right)h\tau(h)
\\
&=\frac{(1+hL)^n-1}{hL}h\tau(h)
\\
&\le\frac{(e^{hL})^n-1}{hL}h\tau(h) \qquad\text{car }(1+x)\le e^x
\\
&=\frac{(e^{hL})^{(t_n-t_0)/h}-1}{L}\tau(h)\qquad\text{car } t_n-t_0=nh
\\
&=\frac{e^{L(t_n-t_0)}-1}{L}\tau(h)
\\
&=\frac{e^{L(t_n-t_0)}-1}{L}\frac{M}{2}h=\mathcal{O}(h)
\end{align*}\) On peut conclure que la méthode d’Euler explicite est convergente d’ordre 1.
On remarque que l’ordre de cette méthode coïncide avec l’ordre de son erreur de troncature. On retrouve cette propriété dans de nombreuses méthodes de résolution numérique d’équations différentielles ordinaires.
Remarque: l’estimation de convergence est obtenue en supposant seulement \(\varphi\) lipschitzienne. On peut établir une meilleure estimation si \(\partial_y\varphi\) existe et est non négative pour tout \(t \in [t_0;T]\) et tout \(y\in\mathbb{R}\). En effet dans ce cas \(\begin{align*}
u_n^* - u_n
&=
\left(y_{n-1} + h\varphi(t_{n-1}, y_{n-1})\right) -
\left( u_{n-1} + h\varphi(t_{n-1},u_{n-1})\right)
\\
&=
e_{n-1}+h\left( \varphi(t_{n-1},y_{n-1})-\varphi(t_{n-1},u_{n-1}) \right)
\\
&=
e_{n-1}+h\left( e_{n-1}\partial_y\varphi(t_{n-1},\eta_n) \right)
\\
&=
\left( 1+h\partial_y\varphi(t_{n-1},\eta_n) \right)e_{n-1}
\end{align*}\) où \(\eta_n\) appartient à l’intervalle dont les extrémités sont \(y_{n-1}\) et \(u_{n-1}\). Ainsi, si \(
0<h<\frac{2}{\max\limits_{t\in[t_0,T]}\partial_y\varphi(t,y(t))}
\) alors \(
|u_n^* - u_n |\le |e_{n-1}|.
\) On en déduit \(|e_n| \le |y_n - u_n^*| + |e_{n-1}| \le nh\tau(h) + |e_0|\) et donc \(
|e_n|\le M \frac{h}{2}(t_n-t_0).
\) La restriction sur le pas de discrétisation \(h\) est une condition de stabilité, comme on le verra dans la suite.
5 Convergence empirique des schémas d’Euler
Considérons le même problème de Cauchy.
On se propose d’estimer l’ordre de convergence des méthodes d’Euler.
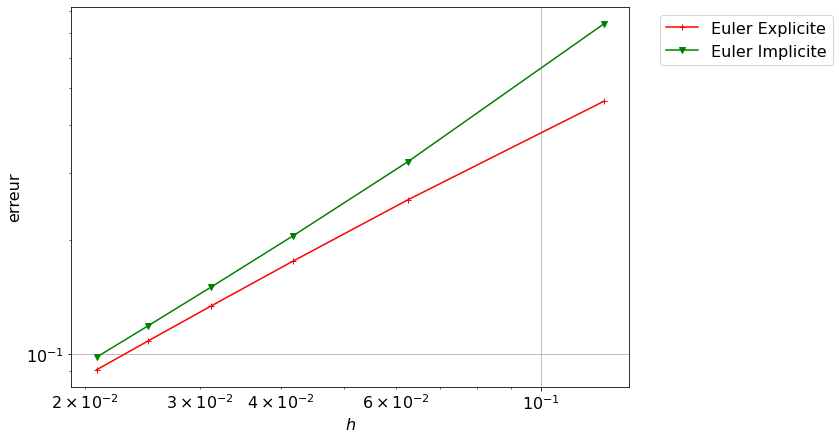
Pour chaque schéma, on calcule la solution approchée avec différentes valeurs de \(h\) (ce qui correspond à différentes valeurs de \(N\)). On sauvegarde les valeurs de \(h\) dans le vecteur H.
Pour chaque valeur de \(h\), on calcule le maximum de la valeur absolue de l’erreur et on sauvegarde toutes ces erreurs dans le vecteur err_schema de sort que err_schema[k] contient \(e_k=\max_{i=0,\dots,N_k}|y(t_i)-u_{i}|\) avec \(N_k\).
Code
H = []err_ep = []err_er = []from numpy.linalg import normfor k inrange(1,7): tt_tmp = np.linspace(t0,tfinal,k*N+1) # on raffine la grille H.append(tt_tmp[1]-tt_tmp[0]) yy = sol_exacte(tt_tmp) uu_ep_tmp = euler_progressif(phi,tt_tmp,y0) uu_er_tmp = euler_regressif(phi,tt_tmp,y0) err_ep.append( norm(uu_ep_tmp-yy,np.inf) ) # idem que max(abs(uu_ep-yy)) err_er.append( norm(uu_er_tmp-yy,np.inf) ) # idem que max(abs(uu_er-yy))
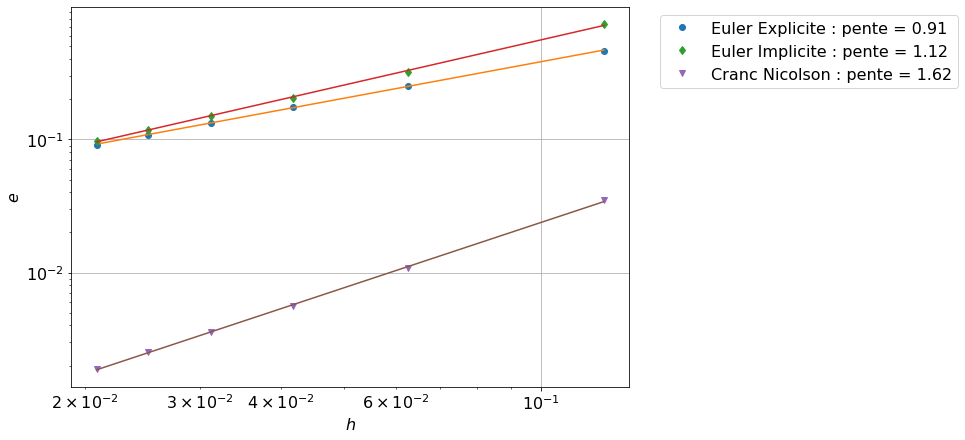
Pour afficher l’ordre de convergence on affiche les points (h[k],err_ep[k]) en échelle logarithmique: on représente \(\ln(h)\) sur l’axe des abscisses et \(\ln(\text{err})\) sur l’axe des ordonnées. En effet, si \(\text{err}=Ch^p\) alors \(\ln(\text{err})=\ln(C)+p\ln(h)\), autrement dit, en échelle logarithmique, \(p\) représente la pente de la ligne droite \(\ln(\text{err})\).
Pour estimer l’ordre de convergence on doit estimer la pente de la droite qui relie l’erreur au pas \(k\) à l’erreur au pas \(k+1\) en échelle logarithmique. Pour estimer la pente globale de cette droite (par des moindres carrés) on peut utiliser la fonction polyfit (du module numpy).
Code
# ln(e) = a ln(h) + ba_ep, b_ep = np.polyfit(np.log(H),np.log(err_ep), 1) # polyfit ( [liste des abscisses], [liste des ordonnées], degré du polynome)print (f'Euler progressif: ordre {</span>a_ep <span class="sc">:1.2f}')a_er, b_er = np.polyfit(np.log(H),np.log(err_er), 1)print (f'Euler regressif: ordre {</span>a_er<span class="sc">:1.2f}')
On peut bien-sûr afficher la droite obtenue par régression linéaire en même temps que les points.
Soit on affiche les logarithmes des données et l’équation de la droite avec la commande plot:
Code
plt.figure(figsize=(18, 7))plt.subplot(1,2,1)plt.plot(np.log(H),np.log(err_ep), 'ro',label='Euler Explicite')plt.plot(np.log(H),[a_ep*np.log(h)+b_ep for h in H])plt.xlabel('$\ln(h)$')plt.ylabel('$\ln(e)$')plt.legend(loc='upper left')plt.grid(True);plt.subplot(1,2,2)plt.plot(np.log(H),np.log(err_er), 'ro',label='Euler Implicite')plt.plot(np.log(H),[a_er*np.log(h)+b_er for h in H])plt.xlabel('$\ln(h)$')plt.ylabel('$\ln(e)$')plt.legend(loc='upper left')plt.grid(True);
Soit on affiche les données en échelle logarithmique et l’équation de l’erreur \(Ch^p\) avec \(C=\ln(b)\) et \(p=a\) avec l’instruction loglog:
Code
plt.figure(figsize=(18, 7))plt.subplot(1,2,1)plt.loglog(H,err_ep, 'ro',label='Euler Explicite')plt.loglog(H,[np.exp(b_ep)*(h**a_ep) for h in H])plt.xlabel('$h$')plt.ylabel('$e$')plt.legend(loc='upper left')plt.grid(True);plt.subplot(1,2,2)plt.loglog(H,err_er, 'ro',label='Euler Implicite')plt.loglog(H,[np.exp(b_er)*(h**a_er) for h in H])plt.xlabel('$h$')plt.ylabel('$e$')plt.legend(loc='upper left')plt.grid(True);
6 Annexe: implémentation d’un schéma “moyen” des deux schémas précédents
On obtient la méthode de Crank-Nicolson (ou du trapèze)